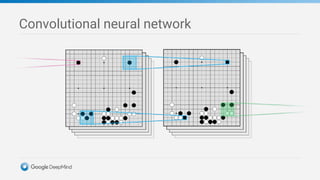
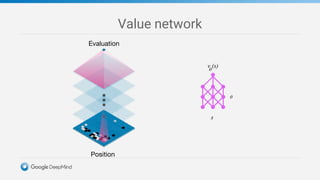
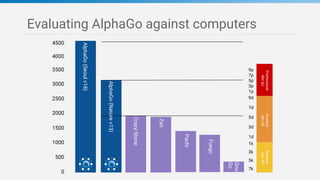
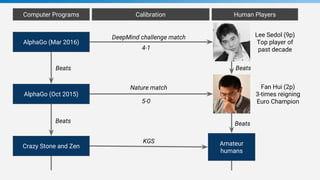
Game tree complexity grows exponentially with the board size, making brute force search intractable for Go. DeepMind developed AlphaGo using a neural network with a policy network to recommend moves and a value network to evaluate board positions. AlphaGo was trained through supervised learning on human expert games and reinforcement learning through self-play, achieving superhuman performance at Go.