動作の例
train/baking/0-2-8-2-0-8-1-6-3302820816_13 train/bending/-DczhmCwr38_40
MiT [Monfort+,TPAMI2019]
train/100/"Putting [something]and [something]on the table"
train/1/"Putting [something similar to other things that are already on the table]"
SSv2 [Goyal+, ICCV2017]
shaking hands/-5IoqELcxSU_000138_000148 robot dancing/-ADLGQ4KR0U_000019_000029
Kinetics [Kay+, arXiv2017] 握手 ロボットダンス
何かを置く
同じ物を
更に置く
料理 腰を曲げて
作業する
画像認識から動画認識へ
◼ CNNによる画像認識
• LeNet[LeCun+, Proc. IEEE, 1998]
• AlexNet [Krizhevsky+, NIPS2012]
• VGG [Simonyan&Zisserman, ICLR2015]
• GoogLeNet / Inception [Szegedy+, CVPR2015]
• ResNet [He+, CVPR2016]
◼ 動画像のフレーム毎に2D CNNを適用
• 画像認識モデルの再利用
• 時間情報の貧弱なモデル化
◼ 動画像への3D CNNの適用
• C3D [Tran+, ICCV2015]
• I3D [Carreira&Zisserman, CVPR2017]
• 3D ResNet [Hara+, CVPR2018]
• SlowFast [Feichtenhofer+, ICCV2019]
• X3D [Feichtenhofer, CVPR2020]
• 計算量の増大
[Karpathy+, CVPR2014]
Figure 1: Explored approaches for fusing information over
temporal dimension through the network. Red, green and
blue boxes indicate convolutional, normalization and pool-
ing layers respectively. In the Slow Fusion model, the de-
picted columns shareparameters.
3.1. TimeInformation Fusion in CNNs
We investigate several approaches to fusing information
in the first fully connected layer. T
frame tower alone can detect any m
connected layer can compute globa
by comparing outputs of both towe
Slow Fusion. The Slow Fusio
mix between thetwo approaches th
information throughout the netwo
ers get access to progressively mo
both spatial and temporal dimensio
by extending the connectivity of
in time and carrying out temporal
to spatial convolutions to compute
[1, 10]. In the model we use, the fir
extended to apply every filter of te
an input clip of 10 frames through
stride 2 and produces 4 responses
Figure 1: Explored approaches for fu
temporal dimension through the netw
blue boxes indicate convolutional, no
ing layers respectively. In the Slow F
picted columns shareparameters.
3.1. TimeInformation Fusion in
We investigate several approaches
[LeCun+, Proc. IEEE, 1998]
[Feichtenhofer, CVPR2020]

![自己紹介
◼2001.4〜2005.9 新潟大学助手
◼2005.10〜2020.9 広島大学准教授
◼2015.5〜2016.1 ESIEE Paris客員研究員
◼2020.10〜 名古屋工業大学教授
◼翻訳書
◼オンライン講義動画・論文紹介スライド
[CVPRW2020, IEEE Access]
AIにとってどのような質問が難しいのかの解析
実時間での大腸内視鏡ガン認識
[MedAI, 2013]
[IVC, 2018]
視野を共有しないカメラの校正](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-2-320.jpg)

![画像認識と動画像認識
モデル
カテゴリ
画像
モデル
カテゴリ
画像認識
動作認識
2xxcpLQHZf8_000002_000012.mp4
Kinetics400 [Kay+, arXiv2017]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-4-320.jpg)
![動画像=静止フレームの時系列
◼入力:動画像
• 時間方向の次元が増える
• 時間情報や動き情報のモデ
ル化が必要
• temporal modeling
時間
動画像
フレーム
2xxcpLQHZf8_000002_000012.mp4
Kinetics400 [Kay+, arXiv2017]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-5-320.jpg)

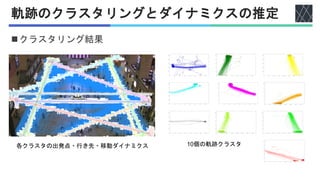
![人物行動軌跡の解析
◼歩行者の行動や軌跡を映像から解析
• 軌跡を扱うためには分割が必要:計算コスト削減,局所的な情報の抽出
◼行動の「意図」を反映した分割が必要
• 行き先・出発点・移動速度等のダイナミクス
[Tamaki+, Advanced Robotics, 2019]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-7-320.jpg)
![従来手法
◼軌跡クラスタリング
[Zhou+, IJCV2015] [Lee+, CVPR2017]
[Saligrama+, CVPR2012]
[Solmaz+, PAMI2012]
◼異常行動検知
◼行動予測
◼群衆行動解析](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-8-320.jpg)
![クラスタリングと分割の同時推定
◼ベイズクラスタリングとHMMの統合
学習済み行動モデル パラメータ推定
歩行軌跡 軌跡分割
MDA+HMM
MDA
[Zhou+, IJCV2015]
HMM
[Baum, 1972]
[Viterbi, 1967]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-9-320.jpg)


![動作認識とは
◼動画像理解タスクの一つ
◼人間の動作を認識する
(Human Action
Recognition, HAR)
• 動き:motion
• 動作:action, activity
• 行動:behavior
◼動画像の識別
• 「人間が動作している映像」
に限らない
• 人間に限定する手法もある
• 人物検出や姿勢推定を併用
モデル
カテゴリ
画像
モデル
カテゴリ
画像認識
動作認識
cats and dogs dataset
2xxcpLQHZf8_000002_000012.mp4
Kinetics400 [Kay+, arXiv2017]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-13-320.jpg)
![動作の例
train/baking/0-2-8-2-0-8-1-6-3302820816_13 train/bending/-DczhmCwr38_40
MiT [Monfort+, TPAMI2019]
train/100/"Putting [something]and [something]on the table"
train/1/"Putting [something similar to other things that are already on the table]"
SSv2 [Goyal+, ICCV2017]
shaking hands/-5IoqELcxSU_000138_000148 robot dancing/-ADLGQ4KR0U_000019_000029
Kinetics [Kay+, arXiv2017] 握手 ロボットダンス
何かを置く
同じ物を
更に置く
料理 腰を曲げて
作業する](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-14-320.jpg)
![Object-ABN
◼アテンション機構
• 入力データの注目するべき所を決める
• Transformer (Vaswani+, NIPS2017)
• 動画認識にも利用されている
• GTA (He+, BMVC2021)
• Non-Local Neural Network (Wang+, CVPR2018)
• アテンションマップが説明可能AIなどに使われる
• ABN (Fukui+, CVPR2019)
◼Object-ABN
• シャープな
アテンション
を生成
入力動画像
[Nitta+, IEICE-ED, 2022]
従来手法
ABN
提案手法
Object-ABN](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-15-320.jpg)
![ObjectMix
◼セグメンテーションした領域を貼り付け
• セグメンテーション用の手法を拡張
• Copy-Paste [Ghiasi+, CVPR2021]
• CutPaste [Li+, CVPR2021]
• 時間方向の不連続性
• 時間方向へのOR演算で領域を拡張
[Kimata+, MMAsia2022]
temporal
OR
each
frame
ObjectMix ObjectMix+or
提案手法 ObjectMix
従来手法 VideoMix](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-16-320.jpg)
![S3Aug
◼バイアスへの対策:セグメンテーションラベルから動画生成
• Segmentation:フレーム毎にセグメンテーション
• Sampling:セグメンテーションラベルをランダムに変更
• Label-to-Image:ラベル画像から実画像へ変換
• Shift:特徴量シフトによる時間方向の不連続性の除去
[Sugiura&Tamaki, VISAPP2024]
label frames
w shift
w/o shift](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-17-320.jpg)

![画像認識から動画認識へ
◼ CNNによる画像認識
• LeNet [LeCun+, Proc. IEEE, 1998]
• AlexNet [Krizhevsky+, NIPS2012]
• VGG [Simonyan&Zisserman, ICLR2015]
• GoogLeNet / Inception [Szegedy+, CVPR2015]
• ResNet [He+, CVPR2016]
◼ 動画像のフレーム毎に2D CNNを適用
• 画像認識モデルの再利用
• 時間情報の貧弱なモデル化
◼ 動画像への3D CNNの適用
• C3D [Tran+, ICCV2015]
• I3D [Carreira&Zisserman, CVPR2017]
• 3D ResNet [Hara+, CVPR2018]
• SlowFast [Feichtenhofer+, ICCV2019]
• X3D [Feichtenhofer, CVPR2020]
• 計算量の増大
[Karpathy+, CVPR2014]
Figure 1: Explored approaches for fusing information over
temporal dimension through the network. Red, green and
blue boxes indicate convolutional, normalization and pool-
ing layers respectively. In the Slow Fusion model, the de-
picted columns shareparameters.
3.1. TimeInformation Fusion in CNNs
We investigate several approaches to fusing information
in the first fully connected layer. T
frame tower alone can detect any m
connected layer can compute globa
by comparing outputs of both towe
Slow Fusion. The Slow Fusio
mix between thetwo approaches th
information throughout the netwo
ers get access to progressively mo
both spatial and temporal dimensio
by extending the connectivity of
in time and carrying out temporal
to spatial convolutions to compute
[1, 10]. In the model we use, the fir
extended to apply every filter of te
an input clip of 10 frames through
stride 2 and produces 4 responses
Figure 1: Explored approaches for fu
temporal dimension through the netw
blue boxes indicate convolutional, no
ing layers respectively. In the Slow F
picted columns shareparameters.
3.1. TimeInformation Fusion in
We investigate several approaches
[LeCun+, Proc. IEEE, 1998]
[Feichtenhofer, CVPR2020]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-19-320.jpg)
![MSCA
◼特徴量を時間方向へシフトする
• フレームごとに2Dモデルを適用
• シフト操作で特徴量を時間的に混合
• 学習パラメータがなく軽量
• TSM [Lin+, ICCV2019]
• Token Shift [Zhang+, ACMMM2021]
• 単純なシフトのみ
◼Multi-head Self/Cross Attention
• クロスアテンションを導入
• アテンションで情報を時間的に混合
• 時間方向の密な情報交換
[Hashiguchi&Tamaki, ACCVW2022]
[Zhang+, ACMMM2021]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-20-320.jpg)

![CNNベースの画像・動画の同時学習
◼UniDual [Wang+, arXiv2019]
• 静止画をコピーして動画像に変換
• R(2+1)D CNNを利用
◼OmniSource [Duan+, ECCV2020]
• 静止画をコピーして動画像に変換
• SlowOnly (3D ResNet)を利用
[Duan+, ECCV2020]
[Wang+, arXiv2019]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-22-320.jpg)
![IV-ViT
◼単一モデル(ViT)を用いた
画像と動画像の同時学習
• 画像:
• 複数画像をバッチで入力
• 出力はそれぞれで損失計算
• 動画:
• 1本の動画のフレームをバッチと
みなして入力
• 出力はlate fusion
◼複数のモダリティ・ドメイン・
データセットの同時学習が可能
画像の学習
動画の学習
.
.
.
1
2
𝑇
ViT
ViT
ViT
.
.
.
.
.
.
ViT
特徴量
予測
予測
入力
入力
[Shimizu&Tamaki, MVA2023]
特徴量
シフト](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-23-320.jpg)
![共有・固有のアダプタ学習
◼通常のfine-tuning
• ヘッドを追加学習
• 事前学習は画像
• fine-tuningは同画像
◼アダプタのfine-tuning
• アダプタとヘッド再学習
• fine-tuningの計算量削減
◼共有・固有のアダプタ
• 画像の事前学習モデルを利用
• 動画の学習には
• データセット毎のアダプタ
• 全データセットに共通のアダプタ
通常のfine-tuning
アダプタ
(LoRA)
データセット毎のアダプタ
共通のアダプタ
[木全&玉木, MIRU2024]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-24-320.jpg)
![共有・固有のプロンプト学習
◼画像とテキストのLLMの事前学習モデル(CLIP)を利用
◼動画の学習には
• データセット毎のプロンプト
• 全データセットに共通のプロンプト
matching
Image:n01440764_10040.JPEG
Video:v_YoYo_g25_c05.avi
Vision
𝑠ℎ𝑎𝑟𝑒𝑑
𝑝𝑟𝑜𝑚𝑝𝑡
𝑎𝑣𝑔
𝐷𝑎𝑡𝑎2
𝑝𝑟𝑜𝑚𝑝𝑡
𝐷𝑎𝑡𝑎1
𝑝𝑟𝑜𝑚𝑝𝑡
Text
A photo of a fish
PlayingPiano 𝐷𝑎𝑡𝑎2
𝑝𝑟𝑜𝑚𝑝𝑡
𝐷𝑎𝑡𝑎1
𝑝𝑟𝑜𝑚𝑝𝑡
𝑠ℎ𝑎𝑟𝑒𝑑
𝑝𝑟𝑜𝑚𝑝𝑡
+
+
+
+
+
+
[志水&玉木, 2024]](https://image.slidesharecdn.com/20240925nagoya-240925050745-9b1de34c/85/AI-Nagoya-25-320.jpg)


















![[DL輪読会]Blind Video Temporal Consistency via Deep Video Prior](https://cdn.slidesharecdn.com/ss_thumbnails/20201030deepvideoprior-201030024757-thumbnail.jpg?width=640&height=640&fit=bounds)





![[IBIS2017 講演] ディープラーニングによる画像変換](https://cdn.slidesharecdn.com/ss_thumbnails/ibis2017iizuka-171120134119-thumbnail.jpg?width=640&height=640&fit=bounds)






























