The document discusses the benefits of treating XML data dynamically rather than statically mapping it to objects. It advocates for avoiding rigid mappings between XML schemas and classes, limiting friction-causing features like namespaces, and ensuring integrity through tests rather than strict validation. The document promotes designing XML applications in a modular, resource-oriented way and using test-driven development practices.































![Test-driving XSLT
Test fixtures simplify complex inputs:
Fragments
String makeMovie(Map fields) {
"""<movie>
<title>${
fields?.title ?: 'Fake Title'
}</title>
<genre>${
fields?.genre ?: 'fakumentary'
}</genre>
${fields?.rating ?
'<rating>' + fields.rating + '</rating>' : ''}
</movie>"""
}
Documents
String makeMovieList(List movies) {
"""<movieList>
${movies.join('n')}
</movieList>"""
}
Usage
@Test
void shouldTransformMovies() {
String input = makeMovieList([
makeMovie(title: 'Primer')
])
// act, assert…
}](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-35-320.jpg)
![Test-driving XSLT
Tests analyze specific features:
@Test
void shouldAggregateIntoGenres() {
List movies = (1..2).collect {
makeMovie(genre: 'drama')
}
movies << makeMovie(genre: 'comedy')
def result =
parseXml(transform(makeMovieList(movies)))
assert result.genre.size() == 2
}
@Test
void shouldCanonicalizeGenreNames() {
String input = makeMovieList([
makeMovie(genre: 'science fiction'),
makeMovie(genre: 'SCIENCE FICTION')
])
def result = parseXml(transform(input))
assert result.genre.size() == 1
assert result.genre.'@name' == 'Science Fiction'
}](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-36-320.jpg)
![Test-driving XSLT
Use of rich language features can help
keep tests short and expressive:
@Test
void shouldSortMovieTitles() {
String input = makeMovieList([
makeMovie(title: 'Zorro', rating: '2'),
makeMovie(title: 'Catching Fire', rating: '1'),
makeMovie(title: 'case insensitive', rating: '0')
])
def result = parseXml(transform(input))
0..2.each {
assertEquals(
it.toString(),
result.genre.film[it].'@mpaa'
)
}
}](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-37-320.jpg)










![Database Migrations
One day, we decided to stop version-managing a
category of documents. Here's what the
migration looked like:
for $doc in cts:search( /citation, dls:documents-query() )
return dls:document-unmanage( fn:base-uri($doc), fn:false(), fn:true() )
And here's a fix for some damaged data:
for $empty-desc in /somePath/description[ fn:string-length() = 0 ]
return xdmp:node-delete( $empty-desc )](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-48-320.jpg)






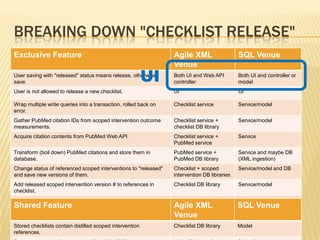
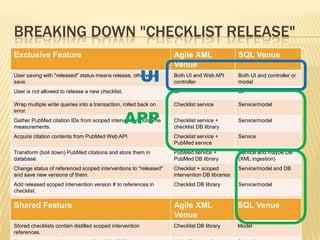
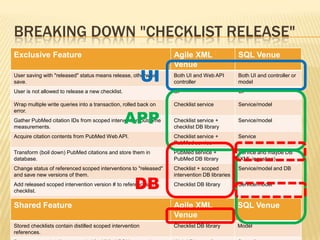



![Fetching the Data
declare private function enriched-performance-measure($perfMeasure as node()) {
return element performanceMeasure {
$perfMeasure/*,
/performanceMeasure[fn:normalize-space(id) = fn:normalize-space($perfMeasure/*[fn:local-name() = 'id'])]/abbreviation
}
};
declare private function enriched-impact-threshold($impactThreshold as node()) {
return element impactThreshold {
$impactThreshold/*,
element pubMedCitation {
let $citation := /pubMedCitation[fn:normalize-space(id) = fn:normalize-space($impactThreshold/*[fn:local-name() = 'pubMedId']/text())]
return (
element title {zpmc:get-article-title($citation)},
element journalInfo {zpmc:get-journal-info($citation)},
element authorList {zpmc:get-authors-list($citation)}
)
}
}
};
declare function enrich-scoped-intervention($element as element()) as element() {
return element { fn:node-name($element) } {
$element/@*,
for $n in $element/node()
return typeswitch ($n)
case element(si:performanceMeasure) return enriched-performance-measure($n)
case element(si:impactThreshold) return enriched-impact-threshold($n)
case element() return enrich-scoped-intervention($n)
default return $n
}
};
declare private function produce-enriched-checklist($element as element()) as element() {
element { fn:node-name($element) } {
$element/@*
,
for $n in $element/node()
return typeswitch ($n)
case $siRef as element(scopedIntervention) return
let $original := zsi:get-scoped-intervention-by-id($siRef/id, $siRef/version/version-id cast as xs:unsignedInt)
return zsi:enrich-scoped-intervention($original)
case $e as element()
return produce-enriched-checklist($e, $fields-to-include)
default return $n
}
};
declare function get-checklist($id as xs:string, $version as xs:unsignedInt) {
let $uri := checklist-uri-from-id($id)
let $doc := c:get-document-with-version-metadata-embedded($uri, $version)
return produce-enriched-checklist($doc)
};
55 Xquery lines
1 round trip](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-65-320.jpg)
![Fetching the Data
declare private function enriched-performance-measure($perfMeasure as node()) {
return element performanceMeasure {
$perfMeasure/*,
/performanceMeasure[fn:normalize-space(id) = fn:normalize-space($perfMeasure/*[fn:local-name() = 'id'])]/abbreviation
}
};
declare private function enriched-impact-threshold($impactThreshold as node()) {
return element impactThreshold {
$impactThreshold/*,
element pubMedCitation {
let $citation := /pubMedCitation[fn:normalize-space(id) = fn:normalize-space($impactThreshold/*[fn:local-name() = 'pubMedId']/text())]
return (
element title {zpmc:get-article-title($citation)},
element journalInfo {zpmc:get-journal-info($citation)},
element authorList {zpmc:get-authors-list($citation)}
)
}
}
};
declare function enrich-scoped-intervention($element as element()) as element() {
return element { fn:node-name($element) } {
$element/@*,
for $n in $element/node()
return typeswitch ($n)
case element(si:performanceMeasure) return enriched-performance-measure($n)
case element(si:impactThreshold) return enriched-impact-threshold($n)
case element() return enrich-scoped-intervention($n)
default return $n
}
};
declare private function produce-enriched-checklist($element as element()) as element() {
element { fn:node-name($element) } {
$element/@*
,
for $n in $element/node()
return typeswitch ($n)
case $siRef as element(scopedIntervention) return
let $original := zsi:get-scoped-intervention-by-id($siRef/id, $siRef/version/version-id cast as xs:unsignedInt)
return zsi:enrich-scoped-intervention($original)
case $e as element()
return produce-enriched-checklist($e, $fields-to-include)
default return $n
}
};
declare function get-checklist($id as xs:string, $version as xs:unsignedInt) {
let $uri := checklist-uri-from-id($id)
let $doc := c:get-document-with-version-metadata-embedded($uri, $version)
return produce-enriched-checklist($doc)
};
function enrichedScopedIntervention(id) {
var si = db.scopedInterventions.findOne({'id': id});
si.performanceMeasures.forEach(function (pm) {
pm.abbreviation = db.performanceMeasures.findOne({'id': pm.id}).abbreviation;
});
si.impactThresholds.forEach(function (th) {
var citation = db.pubMedCitations.findOne({'id': th.pubMedId})
th.pubMedCitation = {
title: getArticleTitle(citation),
journalInfo: getJournalInfo(citation),
authorList: getAuthorList(citation)
};
});
}
function getChecklist(id, version) {
var checklist = db.checklists.findOne({'id': id + '_' + version});
checklist.groups.forEach(function (group) {
for (i = 0; i < group.scopedInterventions.length; ++i) {
group.scopedInterventions[i] =
enrichedScopedIntervention(group.scopedInterventions[i].id);
}
});
return checklist;
}
26 JavaScript lines
> 200
round trips](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-66-320.jpg)
![Generating the View
<xsl:template name="intervention">
<xsl:param name="intervention-group-key"/>
<xsl:param name="intervention-name" />
<intervention>
<id>
<xsl:copy-of select="normalize-space($intervention-group-key)"/>
</id>
<displayName><xsl:value-of select="$intervention-name" /></displayName>
<xsl:copy-of select="current-group()[1]/shouldAvoid"/>
<hasOutcomes>
<xsl:value-of select="exists(current-group()/outcomes/outcomeContainer/outcome)" />
</hasOutcomes>
<hasGuidelines>
<xsl:value-of select="exists(current-group()/guidelines/guideline)" />
</hasGuidelines>
<scopes>
<xsl:for-each-group select="current-group()"
group-by="concat(local:canonicalize-field-value-ids(., 'careSetting'), '_', local:canonicalize-field-value-ids(., 'ageGroup'))">
<xsl:sort>
<xsl:variable name="care-setting-names" select="local:canonicalize-field-values-for-sorting(., 'careSetting')" />
<xsl:variable name="age-group-names" select="local:canonicalize-field-values-for-sorting(., 'ageGroup')" />
<xsl:value-of select="concat($care-setting-names, '__', $age-group-names)" />
</xsl:sort>
<xsl:variable name="sub-group-key" select="current-grouping-key()"/>
<scope>
<xsl:variable name="first-si" select="current-group()[1]"/>
<ageGroupName>
<xsl:value-of select="local:format-field-values-for-display($first-si, 'ageGroup')"/>
</ageGroupName>
<careSettingName>
<xsl:value-of select="local:format-field-values-for-display($first-si, 'careSetting')"/>
</careSettingName>
<id>
<xsl:value-of select="$intervention-group-key"/>
<xsl:text>__</xsl:text>
<xsl:value-of select="$sub-group-key"/>
</id>
<scopedInterventions>
<xsl:for-each select="current-group()">
<xsl:copy-of select="." />
</xsl:for-each>
</scopedInterventions>
</scope>
</xsl:for-each-group>
</scopes>
</intervention>
</xsl:template>
84 lines
of XSLT](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-67-320.jpg)
![<xsl:template name="intervention">
<xsl:param name="intervention-group-key"/>
<xsl:param name="intervention-name" />
<intervention>
<id>
<xsl:copy-of select="normalize-space($intervention-group-key)"/>
</id>
<displayName><xsl:value-of select="$intervention-name" /></displayName>
<xsl:copy-of select="current-group()[1]/shouldAvoid"/>
<hasOutcomes>
<xsl:value-of select="exists(current-group()/outcomes/outcomeContainer/outcome)" />
</hasOutcomes>
<hasGuidelines>
<xsl:value-of select="exists(current-group()/guidelines/guideline)" />
</hasGuidelines>
<scopes>
<xsl:for-each-group select="current-group()"
group-by="concat(local:canonicalize-field-value-ids(., 'careSetting'), '_', local:canonicalize-field-value-ids(., 'ageGroup'))">
<xsl:sort>
<xsl:variable name="care-setting-names" select="local:canonicalize-field-values-for-sorting(., 'careSetting')" />
<xsl:variable name="age-group-names" select="local:canonicalize-field-values-for-sorting(., 'ageGroup')" />
<xsl:value-of select="concat($care-setting-names, '__', $age-group-names)" />
</xsl:sort>
<xsl:variable name="sub-group-key" select="current-grouping-key()"/>
<scope>
<xsl:variable name="first-si" select="current-group()[1]"/>
<ageGroupName>
<xsl:value-of select="local:format-field-values-for-display($first-si, 'ageGroup')"/>
</ageGroupName>
<careSettingName>
<xsl:value-of select="local:format-field-values-for-display($first-si, 'careSetting')"/>
</careSettingName>
<id>
<xsl:value-of select="$intervention-group-key"/>
<xsl:text>__</xsl:text>
<xsl:value-of select="$sub-group-key"/>
</id>
<scopedInterventions>
<xsl:for-each select="current-group()">
<xsl:copy-of select="." />
</xsl:for-each>
</scopedInterventions>
</scope>
</xsl:for-each-group>
</scopes>
</intervention>
</xsl:template>
Generating the View
function makeScopeSubGroups(group, interventionGroupKey) {
var result = [];
var scopeSubGroups = [];
var makePredicate = function (scopedIntervention) {
return function (scopeSubGroup) {
if (scopeSubGroup.id === makeScopeSubGroupKey(scopedIntervention)) {
scopeSubGroup.members.push(scopedIntervention);
return true;
}
else {
return false;
}
}
};
section.scopedInterventions.forEach(function (si) {
if (! scopeSubGroups.some(makePredicate(si))) {
scopeSubGroups.push({
id: makeScopeSubGroupKey(si),
members: [si]
});
}
});
scopeSubGroups.sort(function (first, second) {
var firstCanonical =
canonicalizeFieldValuesForSorting(first.careSettings) + '__' +
canonicalizeFieldValuesForSorting(first.ageGroups);
var secondCanonical =
canonicalizeFieldValuesForSorting(second.careSettings) + '__' +
canonicalizeFieldValuesForSorting(second.ageGroups);
return first.localeCompare(second);
});
scopeSubGroups.forEach(function (subGroup) {
var firstSi = subGroup.members[0];
var realSubGroup = {
ageGroupName: formatFieldValuesForDisplay(firstSi.ageGroups),
careSettingName: formatFieldValuesForDisplay(firstSi.careSettings),
id: interventionGroupKey + '__' + subGroup.id,
scopedInterventions: []
};
subGroup.members.forEach(function (si) {
realSubGroup.scopedInterventions.push(si);
});
result.push(realSubGroup);
});
return result;
}
118 lines of
JavaScript](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-68-320.jpg)
![<xsl:with-param name="intervention-group-key">
<xsl:text>section-</xsl:text>
<xsl:value-of select="normalize-space(current-group()[1]/sections/section[1]/id)"/>
<xsl:text>-intervention-</xsl:text>
<xsl:value-of select="normalize-space(current-group()[1]/intervention/id)"/>
</xsl:with-param>
var key = "section-" + interventionGroup.members[0].sections[0].id +
"-intervention-" + interventionGroup.id;
In XSLT, concatenating values
happens to be wordy:
VS.](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-69-320.jpg)
![<xsl:for-each-group select="scopedInterventions/scopedIntervention"
group-by="normalize-space(intervention/id)">
var result = [];
var interventionGroups = [];
var makePredicate = function (scopedIntervention) {
return function (interventionGroup) {
if (interventionGroup.id === scopedIntervention.intervention.id) {
interventionGroup.members.push(scopedIntervention);
return true;
}
else {
return false;
}
}
};
section.scopedInterventions.forEach(function (si) {
if (! interventionGroups.some(makePredicate(si))) {
interventionGroups.push({
id: si.intervention.id,
members: [si]
});
}
});
interventionGroups.forEach(function (interventionGroup) {
var key = "section-" + interventionGroup.members[0].sections[0].id + "-intervention-" + interventionGroup.id;
result.push(
makeInterventionGroup(interventionGroup.members, key, interventionGroup.members[0].scopedInterventionName)
);
});
But JavaScript lacks
transformation features like
"for-each-group" that reduce real
complexity:
VS.](https://image.slidesharecdn.com/agile-xml-130509131528-phpapp02/85/Agile-xml-70-320.jpg)




































































