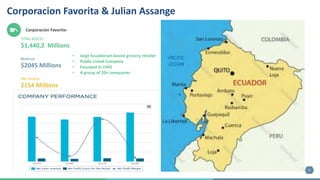
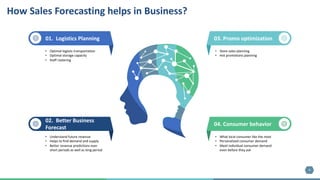
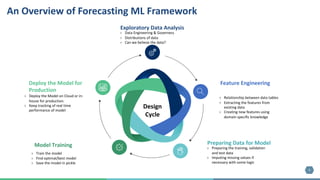
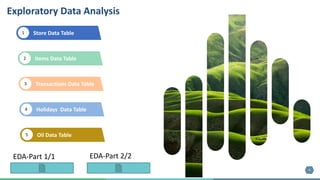
The document outlines the development of a machine learning pipeline for retail sales forecasting at Corporacion Favorita, a major Ecuadorian grocery retailer. It emphasizes the importance of sales forecasting for better business decisions, detailing the model development, feature engineering, and deployment process. Future improvements include enhancing model features, scaling using Spark, and creating a monitoring framework for model consistency.







































![[DSC Europe 22] Data-driven transformation: Use case in demand forecasting @ ...](https://cdn.slidesharecdn.com/ss_thumbnails/martinmozinapetrahajdukovic-221129232413-e1d4c93e-thumbnail.jpg?width=640&height=640&fit=bounds)




















![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











