Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
ssuser05c366
PDF, PPTX
36 views
勉強メモ_なぜ機械学習でのアルゴリズムの選定をするのか?_k-means法を例として
機械学習の文脈で「アルゴリズムを選ぶ」という気持ちがどんなものかを理解するためのスライド。
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 37
2
/ 37
3
/ 37
4
/ 37
5
/ 37
6
/ 37
7
/ 37
8
/ 37
9
/ 37
10
/ 37
11
/ 37
12
/ 37
13
/ 37
14
/ 37
15
/ 37
16
/ 37
17
/ 37
18
/ 37
19
/ 37
20
/ 37
21
/ 37
22
/ 37
23
/ 37
24
/ 37
25
/ 37
26
/ 37
27
/ 37
28
/ 37
29
/ 37
30
/ 37
31
/ 37
32
/ 37
33
/ 37
34
/ 37
35
/ 37
36
/ 37
37
/ 37
More Related Content
PDF
論文紹介&実験
by
SHINGO MORISHITA
PPTX
機械学習基礎(3)(クラスタリング編)
by
mikan ehime
PDF
K meansによるクラスタリングの解説と具体的なクラスタリングの活用方法の紹介
by
Takeshi Mikami
PDF
クラスタリング
by
SEIICHIRO DAN
PDF
各言語の k-means 比較
by
y-uti
PPTX
ビジネスアイディアを考えるときに 押さえておきたい機械学習4種類
by
西岡 賢一郎
PDF
第四回 集合知プログラミング勉強会資料
by
Anchuuu Annaka
PPTX
エススタ 機械学習のキホン
by
Daiyu Hatakeyama
論文紹介&実験
by
SHINGO MORISHITA
機械学習基礎(3)(クラスタリング編)
by
mikan ehime
K meansによるクラスタリングの解説と具体的なクラスタリングの活用方法の紹介
by
Takeshi Mikami
クラスタリング
by
SEIICHIRO DAN
各言語の k-means 比較
by
y-uti
ビジネスアイディアを考えるときに 押さえておきたい機械学習4種類
by
西岡 賢一郎
第四回 集合知プログラミング勉強会資料
by
Anchuuu Annaka
エススタ 機械学習のキホン
by
Daiyu Hatakeyama
Similar to 勉強メモ_なぜ機械学習でのアルゴリズムの選定をするのか?_k-means法を例として
PDF
Clustering _ishii_2014__ch10
by
Kota Mori
PPTX
TECHTALK 20230131 ビジネスユーザー向け機械学習入門 第1回~機械学習の概要と、ビジネス課題と機械学習問題の定義
by
QlikPresalesJapan
PDF
データベースで始める機械学習
by
オラクルエンジニア通信
PPTX
MLaPP輪講 Chapter 1
by
ryuhmd
PDF
[AI01] いまさら聞けない、エンジニアのための機械学習のキホン
by
de:code 2017
PPTX
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
PDF
Scikit learnで学ぶ機械学習入門
by
Takami Sato
PDF
【de:code 2020】 さくっとプチ成功する機械学習プロジェクトのコツ
by
日本マイクロソフト株式会社
PDF
ユークリッド距離以外の距離で教師無しクラスタリング
by
Maruyama Tetsutaro
PPTX
人工知能概論 10
by
Tadahiro Taniguchi
PDF
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
PDF
初めての機械学習
by
Katsuhiro Morishita
PPTX
データマイニングにおける属性構築、事例選択
by
無職
PPTX
AIをあなたのツール化するための第一歩
by
Daiyu Hatakeyama
PDF
はてなインターン「機械学習」
by
Hatena::Engineering
PPTX
Webサービスを分類してみた
by
しくみ製作所
PPTX
Webサービスを分類してみた
by
Shumpei Hozumi
PDF
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PPTX
PRML1.1
by
Tomoyuki Hioki
PPTX
入門パターン認識と機械学習 1章 2章
by
hiro5585
Clustering _ishii_2014__ch10
by
Kota Mori
TECHTALK 20230131 ビジネスユーザー向け機械学習入門 第1回~機械学習の概要と、ビジネス課題と機械学習問題の定義
by
QlikPresalesJapan
データベースで始める機械学習
by
オラクルエンジニア通信
MLaPP輪講 Chapter 1
by
ryuhmd
[AI01] いまさら聞けない、エンジニアのための機械学習のキホン
by
de:code 2017
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
Scikit learnで学ぶ機械学習入門
by
Takami Sato
【de:code 2020】 さくっとプチ成功する機械学習プロジェクトのコツ
by
日本マイクロソフト株式会社
ユークリッド距離以外の距離で教師無しクラスタリング
by
Maruyama Tetsutaro
人工知能概論 10
by
Tadahiro Taniguchi
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
初めての機械学習
by
Katsuhiro Morishita
データマイニングにおける属性構築、事例選択
by
無職
AIをあなたのツール化するための第一歩
by
Daiyu Hatakeyama
はてなインターン「機械学習」
by
Hatena::Engineering
Webサービスを分類してみた
by
しくみ製作所
Webサービスを分類してみた
by
Shumpei Hozumi
Hands on-ml section1-1st-half-20210317
by
Nagi Kataoka
PRML1.1
by
Tomoyuki Hioki
入門パターン認識と機械学習 1章 2章
by
hiro5585
勉強メモ_なぜ機械学習でのアルゴリズムの選定をするのか?_k-means法を例として
1.
なぜ機械学習で アルゴリズムを 選定するのか? 2024/06/01
2.
メインテーマ 機械学習でアルゴリズムを選定するモチベを理解する そのために、以下の事例を把握する。 k-meansによる残念な結果 を見る 1つのアルゴリズムの限界 を知る ↓ 他のアルゴリズムを探す必要性
を感じる
3.
- 教師なし学習 >
クラスタリング > k-means法 - クラスタリング= 似た性質を持つデータをグルーピングすること。 - そのためのアルゴリズムの 1つがk-means法 - k-means法の説明の前に、まずはクラスタリングの目的を見ていく - ※アルゴリズム= 問題を解くための手順 今回見ていくアルゴリズム
4.
クラスタリングの目的は?(前置き) ユースケース - ある回転ずし店、スシ○ーでは、新しいサービスを考えている。 - この時、もしも「中程度の所得者にはラーメンが人気だ」という情報があったら...? -
中程度の所得者ならば、クーポンを配布したら店に来る頻度が増えるかもしれな い、、、そんなアイデアを得られる
5.
クラスタリングの目的は?(前置き) ユースケース - 1か月の所得額 累 計 ラ ー メ ン 注 文 数 「中程度の所得者にはラーメンが人気 だ」という情報はどう入手するか? ーここでクラスタリングの出番 アンケート調査の結果を収集 →クラスタリング →データの傾向を発見する
6.
クラスタリングの目的は?(前置き) ユースケース - 1か月の所得額 累 計 ラ ー メ ン 注 文 数 これが、 クラスタリング の目的の1つ もっと買え クーポン
7.
クラスタリング はどうやって実現?
8.
k-means法 それはk-means法というアルゴリズム ここからはそれを説明します。 アルゴリズムは4ステップからなります。 k-means 君
9.
k-means法 1.クラスター数を指定 k-means 君 4個のクラスタにして イエッサー
10.
k-means法 2.ランダムに点をクラスタ数だけ、設置する これがクラスタの代表点となる k-means 君 設置シマシタ A B C D 点A, B,
C, Dとする
11.
k-means法 3.全てのデータ点と代表点との距離を計算する。 各データ点は最も近い代表点のクラスタに 属する 4つにワケマシタ k-means 君 A B C D
12.
k-means法 4.クラスターごとに重心を計算する その重心が次のクラスターの代表点となる 重心を求める式は以下 (i:クラスタを指定する値, X:データ数, x:データ) k-means 君 代表点 動カシマシタ 重心の式は高校数学 で習ったものの拡張版 かな
13.
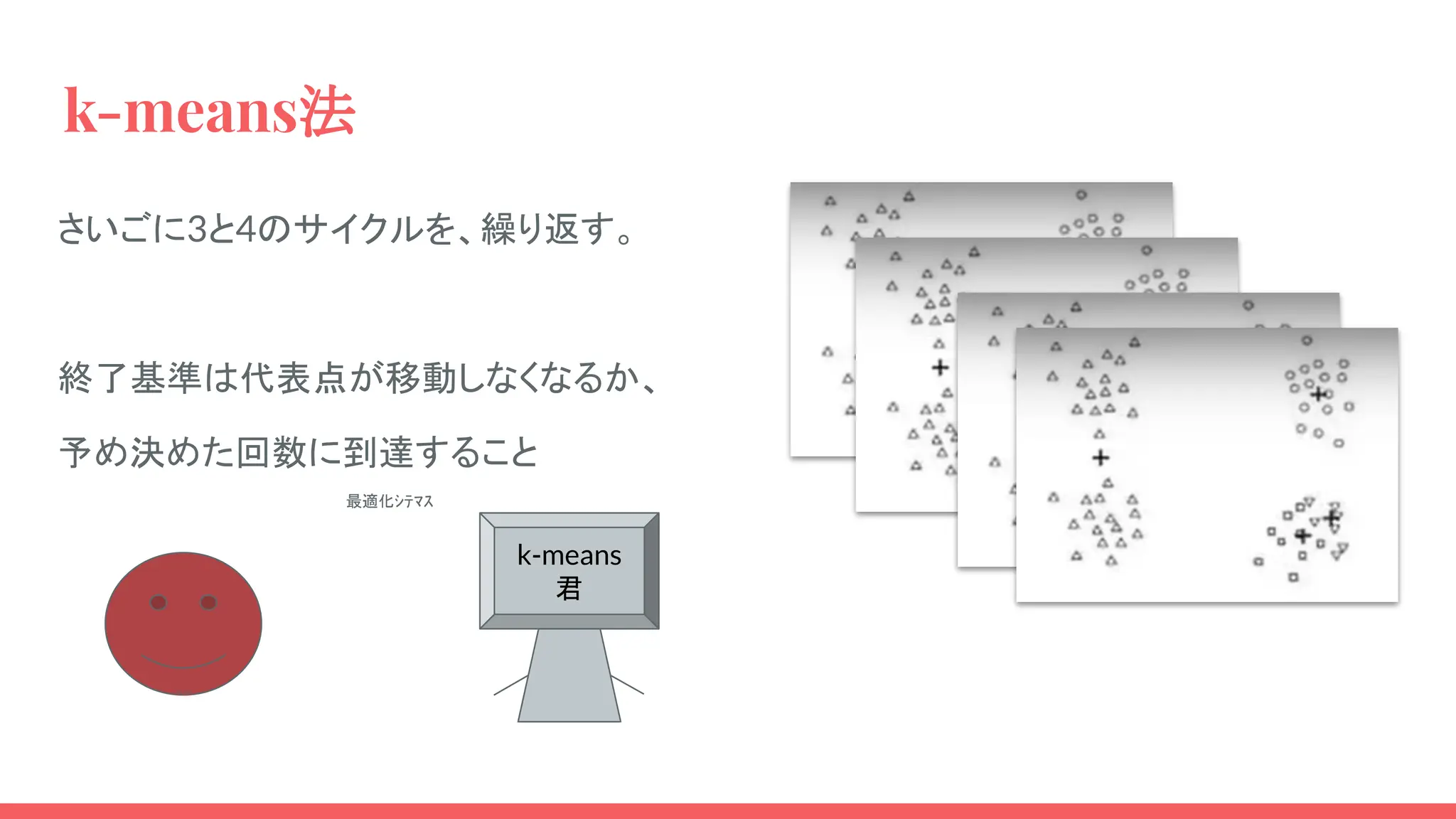
k-means法 さいごに3と4のサイクルを、繰り返す。 終了基準は代表点が移動しなくなるか、 予め決めた回数に到達すること k-means 君 最適化シテマス
14.
k-means法の 失敗ケース
15.
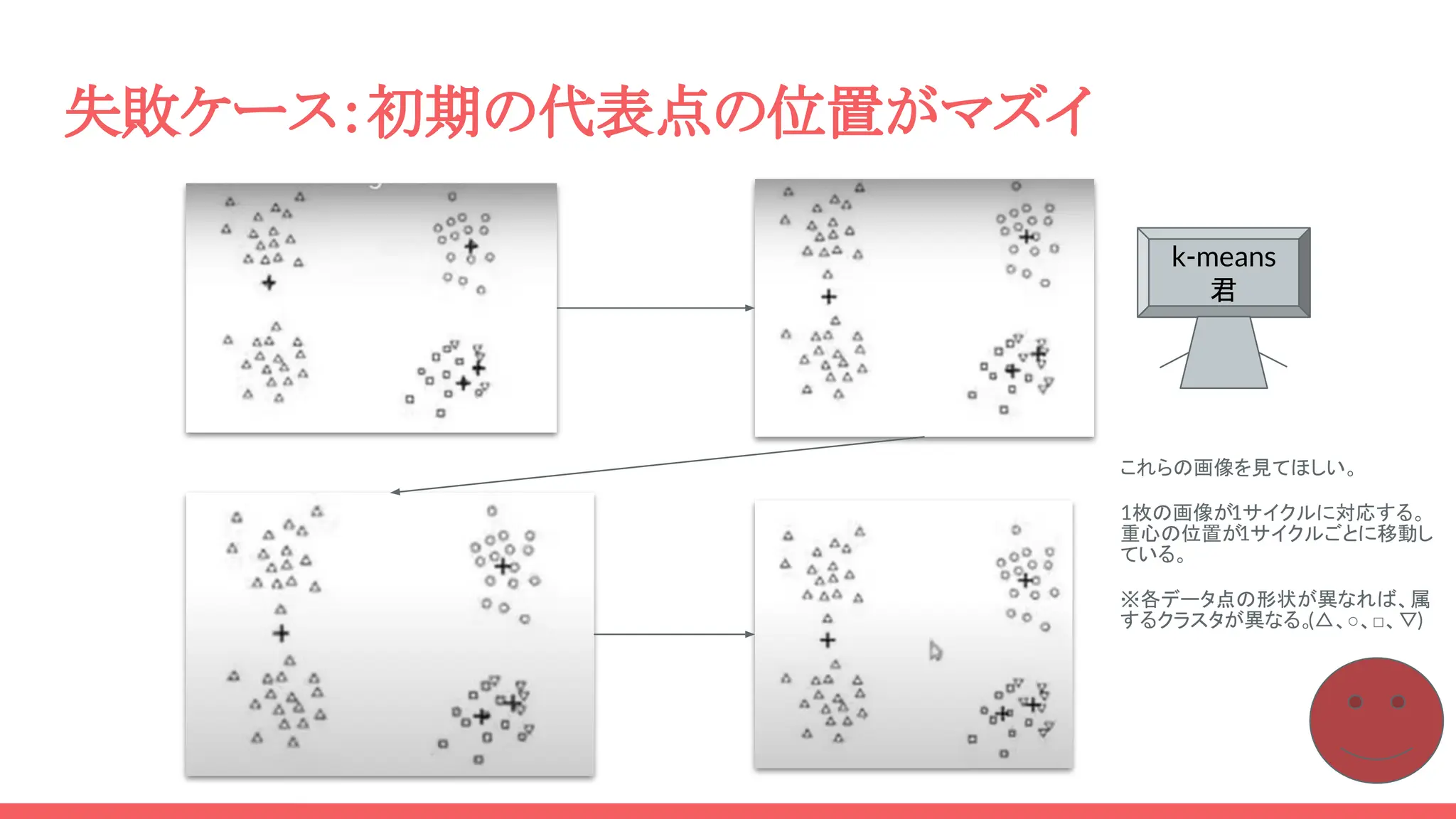
失敗ケース:初期の代表点の位置がマズイ これらの画像を見てほしい。 1枚の画像が1サイクルに対応する。 重心の位置が1サイクルごとに移動し ている。 ※各データ点の形状が異なれば、属 するクラスタが異なる。 (△、○、□、▽) k-means 君
16.
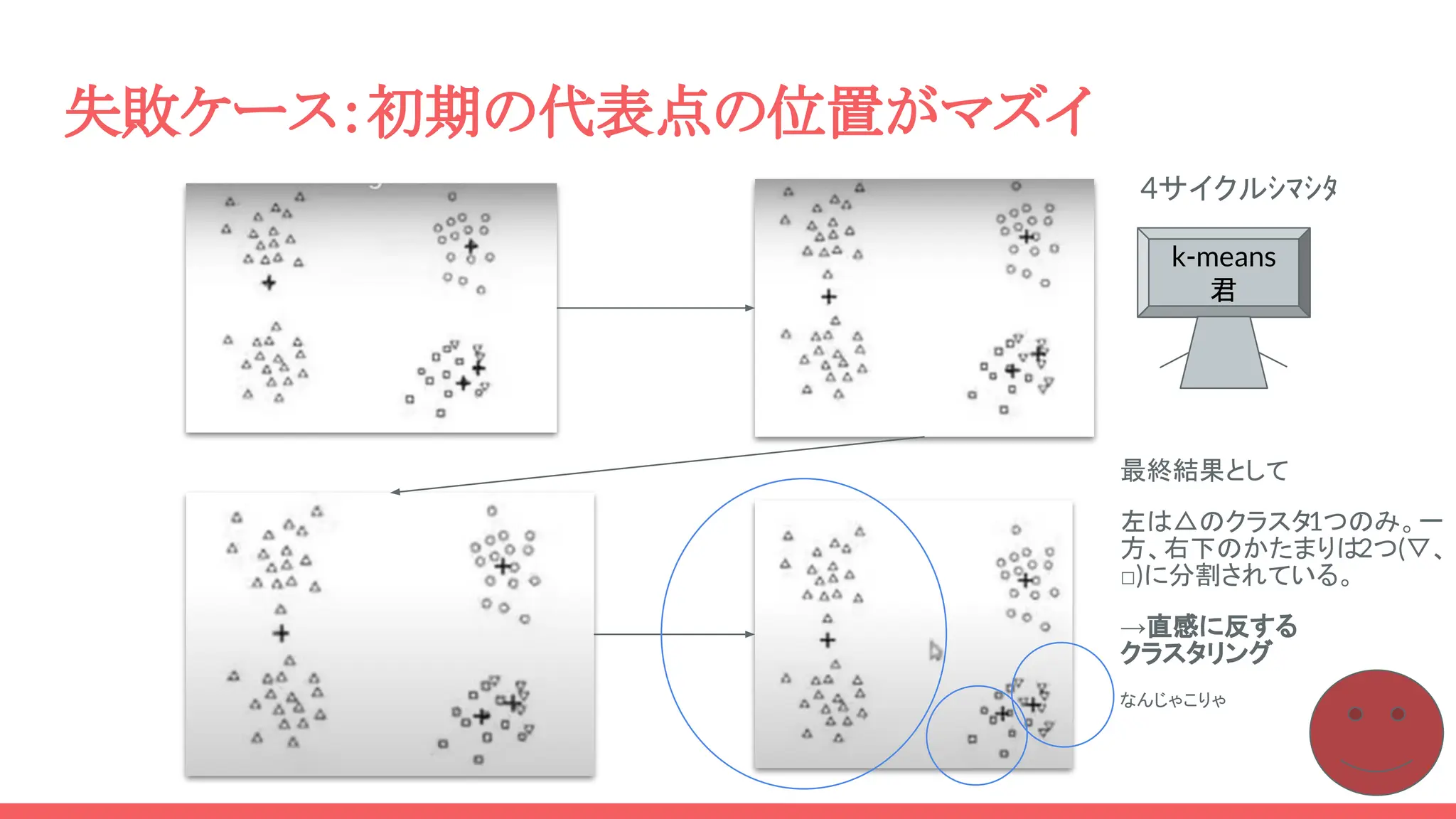
失敗ケース:初期の代表点の位置がマズイ 最終結果として 左は△のクラスタ1つのみ。一 方、右下のかたまりは2つ(▽、 □)に分割されている。 →直感に反する クラスタリング なんじゃこりゃ k-means 君 4サイクルシマシタ
17.
失敗ケース:初期の代表点の位置がマズイ なぜ直感に反するクラスタリングになったか? 初期の重心の位置がマズかったから。 (1つのかたまりの中に2点が密接していた) k-means 君 こら アルゴリズム ドオリ ヤリマシタヨ
18.
失敗ケース:初期の代表点の位置がマズイ このk-means君の弱点を克服したアルゴリズムがありました。 k-means++ 君です。 k-means 君 k-means++君 k-meansトハ 一味チガウ アルゴリズムダゼ
19.
k-means++ のアルゴリズム
20.
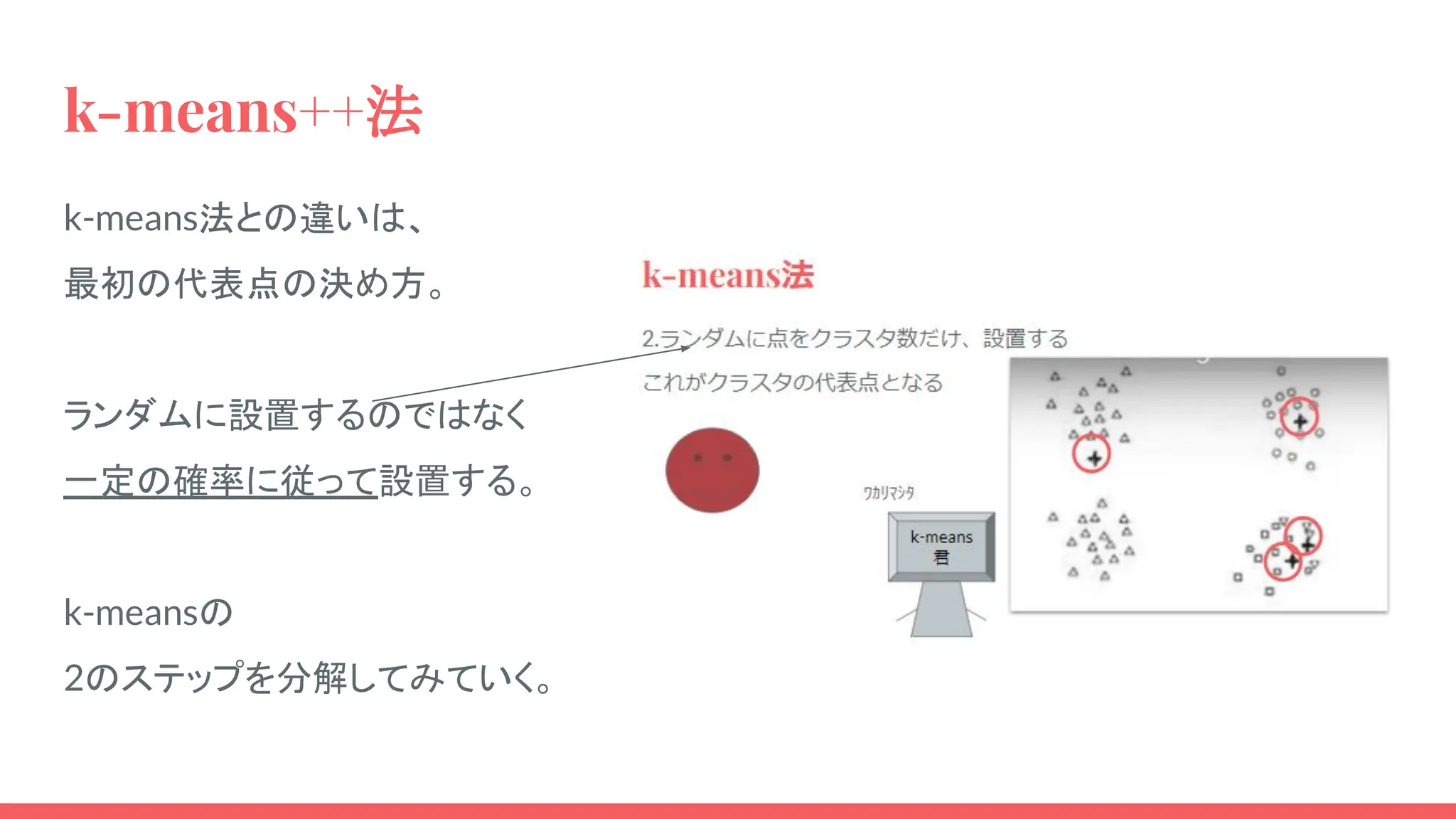
k-means++法 k-means法との違いは、 最初の代表点の決め方。 ランダムに設置するのではなく 一定の確率に従って設置する。 k-meansの 2のステップを分解してみていく。
21.
k-means++法 クラスター数 = 4として 初期に4つの点を打つことを目指す。 2-1.
1個目の代表点をランダムに選ぶ。 (ここでは青点) 2-2. 2個目を選ぶ。 そのために、 各データ点が2個目の代表点に選ばれる確率を算出。 確率の定義は 青点との距離の2乗 / 青点と各データ点との距離の 2乗の和 k-means++君
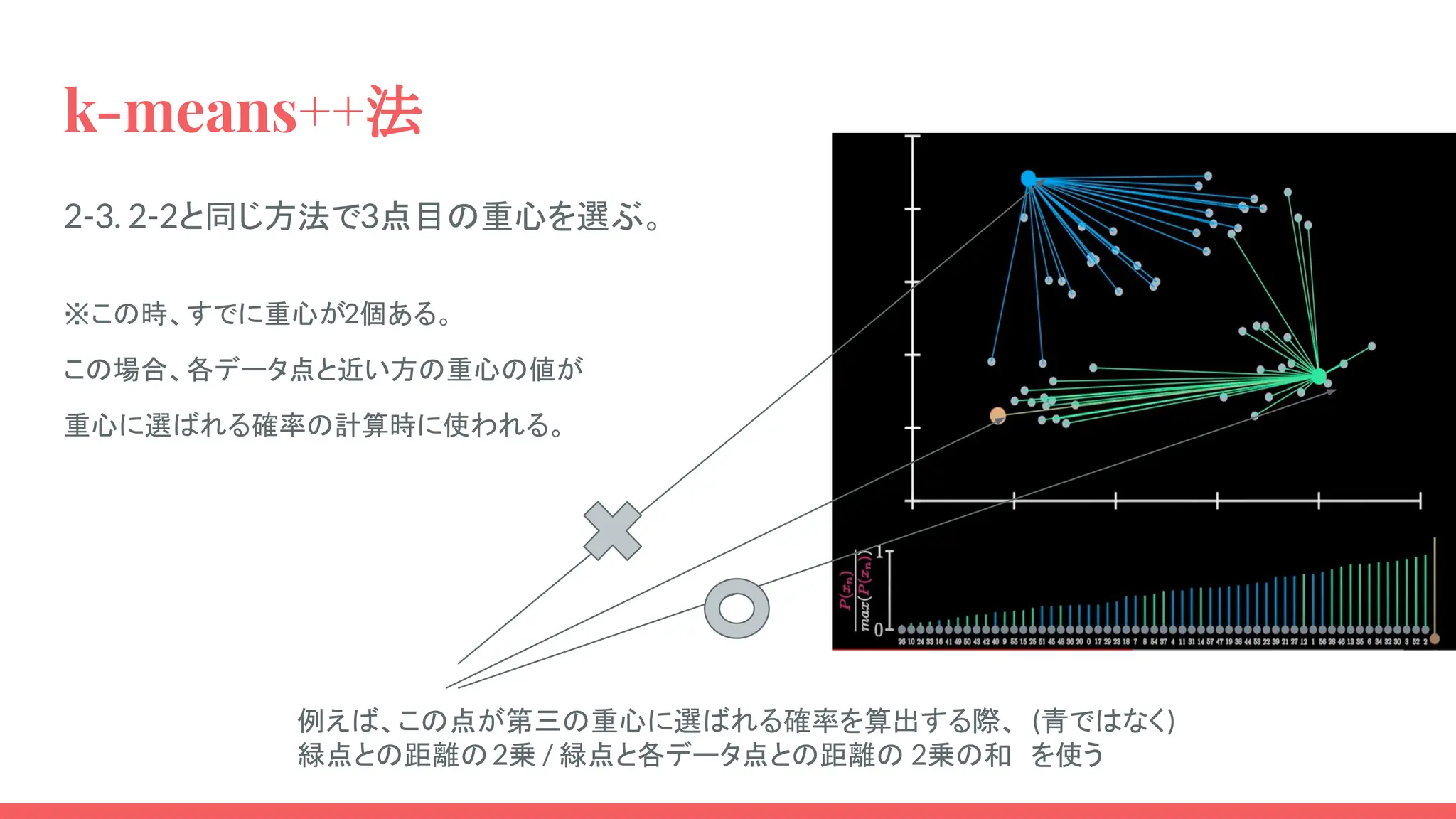
22.
k-means++法 2-3. 2-2と同じ方法で3点目の重心を選ぶ。 ※この時、すでに重心が2個ある。 この場合、各データ点と近い方の重心の値が 重心に選ばれる確率の計算時に使われる。 例えば、この点が第三の重心に選ばれる確率を算出する際、 (青ではなく) 緑点との距離の2乗
/ 緑点と各データ点との距離の 2乗の和 を使う
23.
k-means++法 2-3を、定義したクラスタ数分の 重心が定まるまで繰り返す。 第三ノ重心、君ニ決メタ ! k-means++君
24.
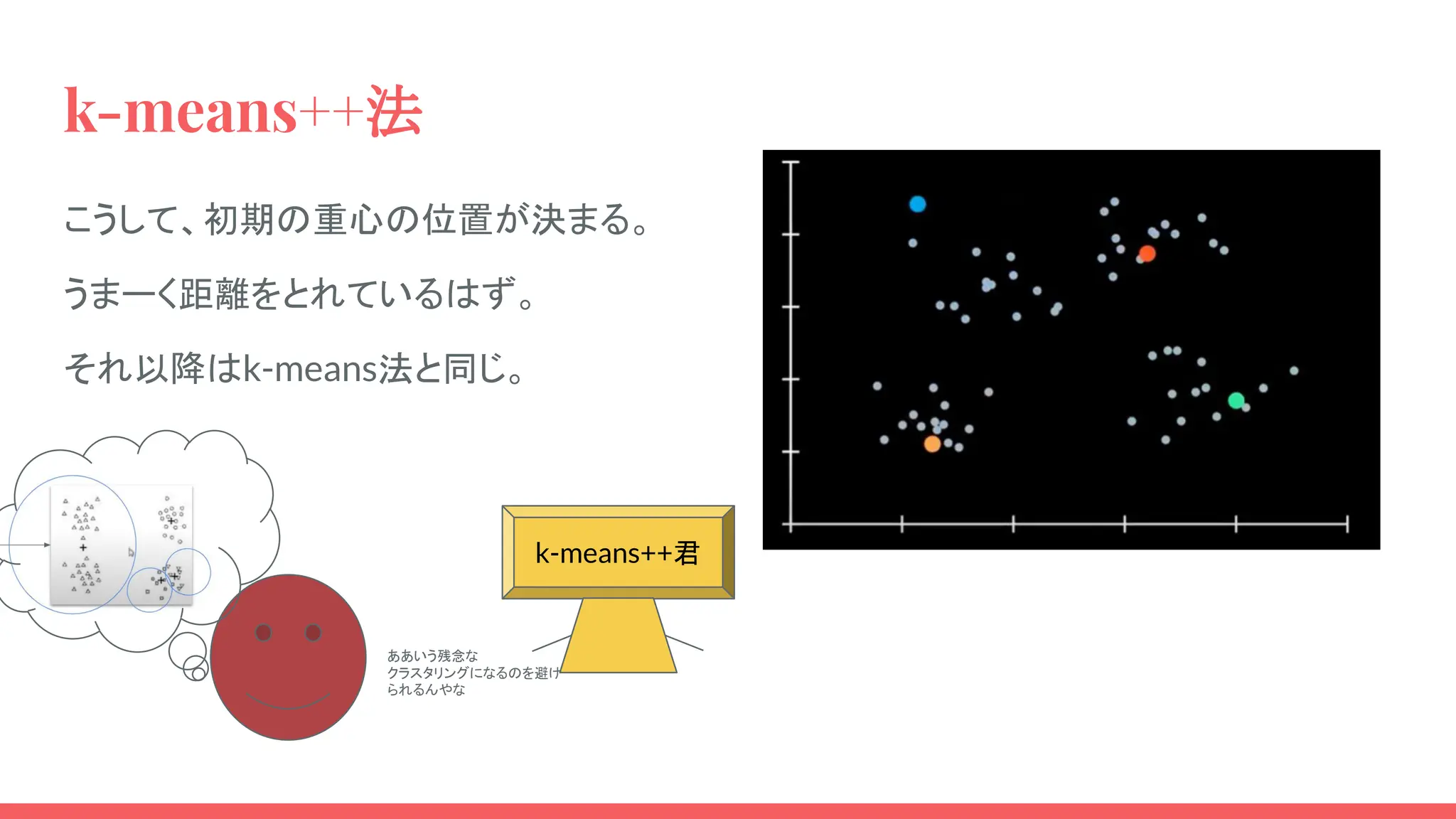
k-means++法 こうして、初期の重心の位置が決まる。 うまーく距離をとれているはず。 それ以降はk-means法と同じ。 k-means++君 ああいう残念な クラスタリングになるのを避け られるんやな
25.
k-means++法 以上がk-means++法でした。 k-meansでの失敗、すなわち初期の代表点が近接してしまうことを 回避しやすそうですね。 ここからk-meansとk-means++の アルゴリズムとしての差を感じられると幸いです。 k-means++君 k-means 君 やるやん
26.
k-meansが失敗するケース (さらに)
27.
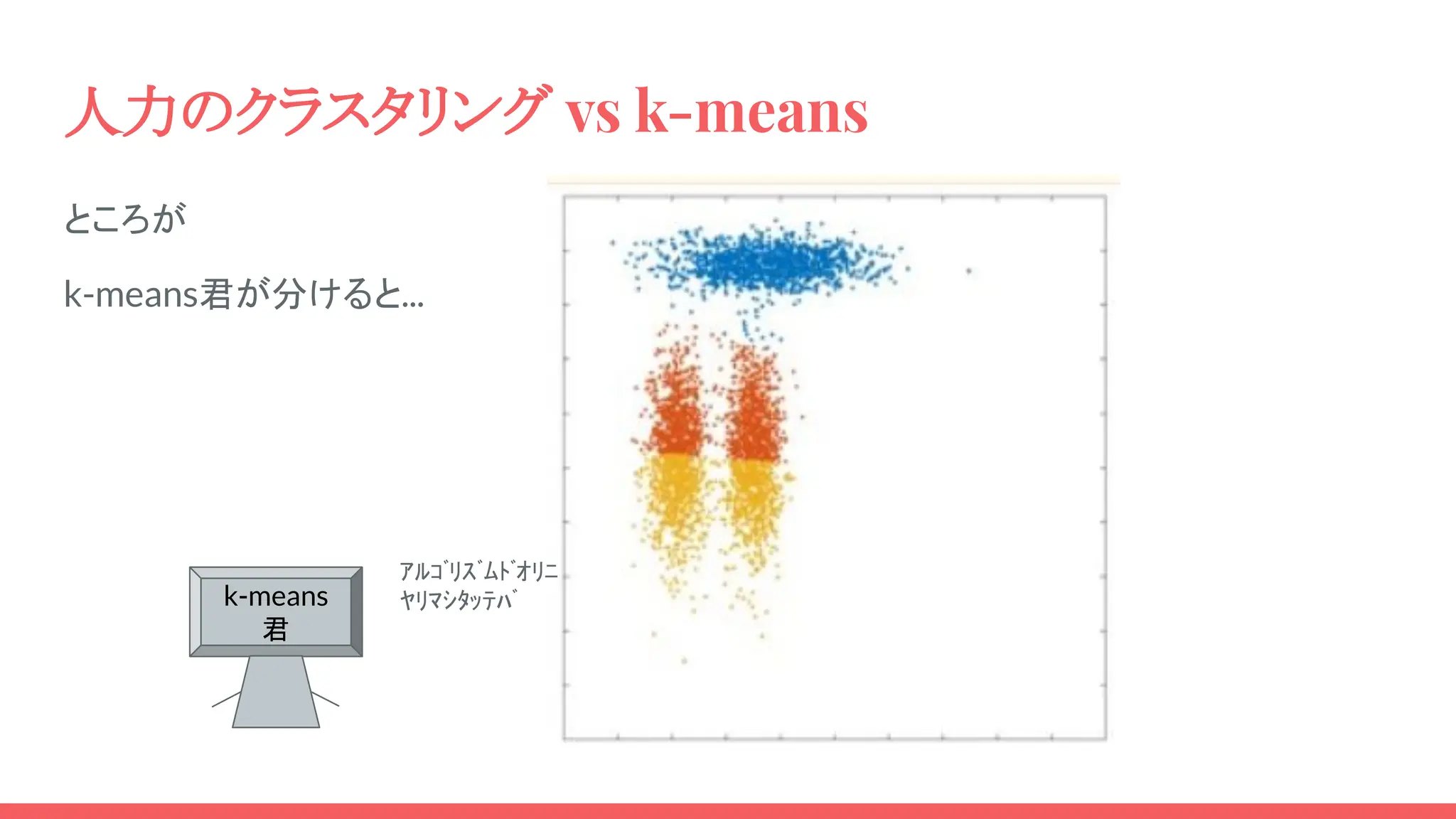
人力のクラスタリング vs k-means ケース1: 右図のデータ点があり、 3つのクラスターに分けるなら? 右図のとおりに分けますよね? ※色の違いはクラスターの違いを示す 3つの塊に分ける
28.
人力のクラスタリング vs k-means ところが k-means君が分けると.. 残念な結果になりました k-means 君 ワタシハ アルゴリズムドオリニ ヤリマシタ
29.
人力のクラスタリング vs k-means ケース2: こちらはどうでしょうか。 楕円3つに分ける
30.
人力のクラスタリング vs k-means ところが k-means君が分けると... k-means 君 アルゴリズムドオリニ ヤリマシタッテバ
31.
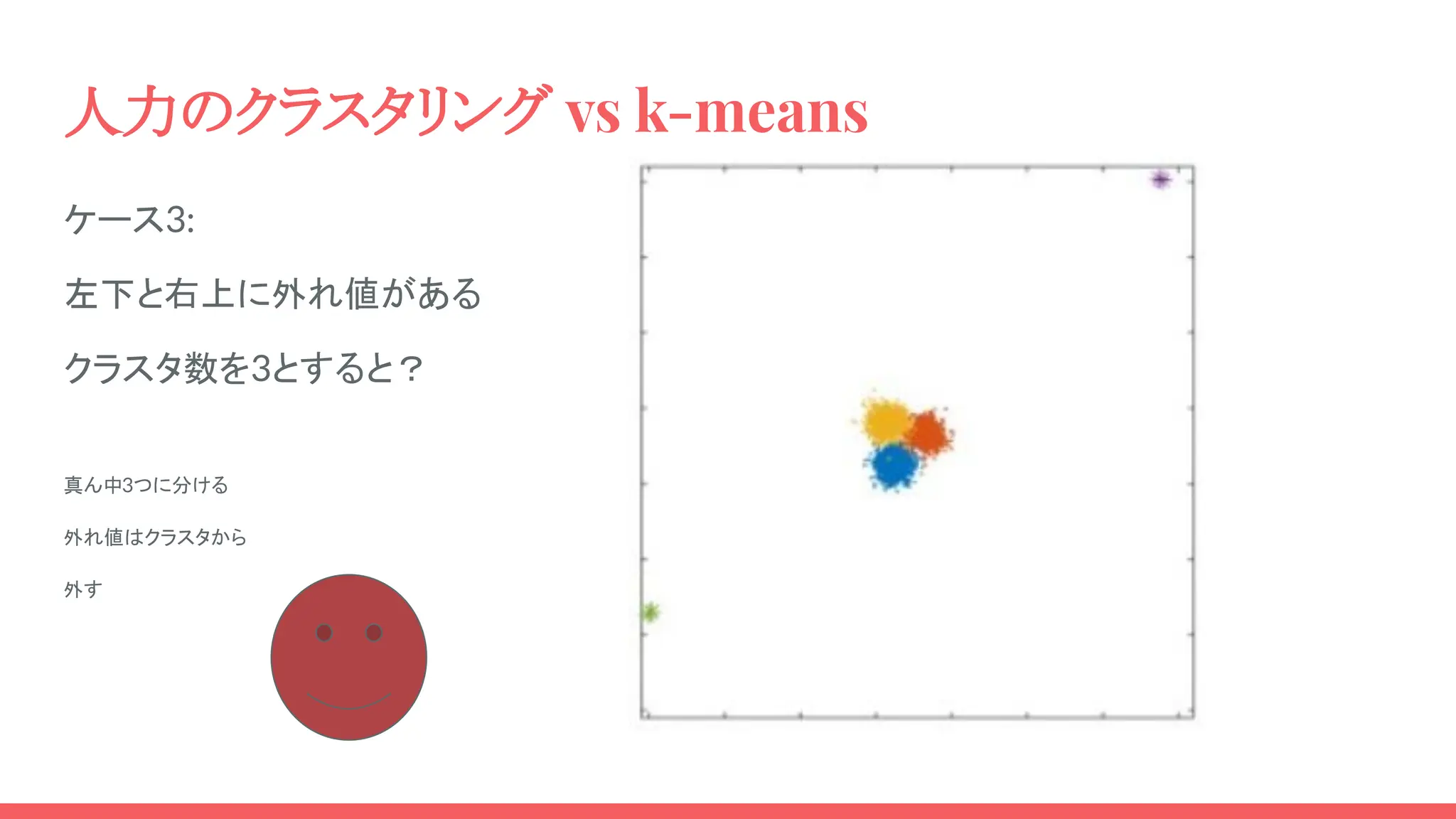
人力のクラスタリング vs k-means ケース3: 左下と右上に外れ値がある クラスタ数を3とすると? 真ん中3つに分ける 外れ値はクラスタから 外す
32.
人力のクラスタリング vs k-means k-means君は左下の外れ値で 1クラスタ消費しました 一方、中央部は2クラスタに。 k-means 君 アルゴリズムドオリデ ナニガワルインデスカ ウエーン
33.
なぜ直感に反するクラスタリングになるのか? ケース1, 2の理由: k-meansのアルゴリズムには仮定があります データセットがその仮定を満たさなかったためです 仮定1. クラスタ同士の密度は同じ (面積あたりのデータ点の数はクラスタ間で同じ) 仮定2.
クラスタは球体である (楕円ではない)
34.
なぜ直感に反するクラスタリングになるのか? ケース3の理由: k-meansは外れ値に弱いです (理由になってませんが) 解決策の1つは、学習前に外れ値を除去すること
35.
なぜ直感に反するクラスタリングになるのか? 以上が失敗ケースです k-meansの限界をおわかりいただけたでしょうか。 あらゆるデータセットをクラスタリングしてくれるとは 限りません。 そのため、データを工夫するか、 k-means以外のアルゴリズムを使う必要性が発生します。
36.
さいごに これで終わりです 最初に掲げたメインテーマを達成できていたら幸いです。 機械学習でアルゴリズムを選定するモチベを理解する k-meansによる残念な結果 を見る 1つのアルゴリズムの限界 を知る ↓ 他のアルゴリズムを探す必要性
を感じる
37.
参考 アルゴリズムの解説動画。短いが、めっちゃ分かりやすい https://youtu.be/4qJWhvFQb9g?si=jcrJ2sZcCnnO9ZSF k-meansがどういう前提条件のもとで失敗するかがわかる論文 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5036949/
Download









































![[AI01] いまさら聞けない、エンジニアのための機械学習のキホン](https://cdn.slidesharecdn.com/ss_thumbnails/ai01ai09-170602095348-thumbnail.jpg?width=640&height=640&fit=bounds)














