Downloaded 38 times


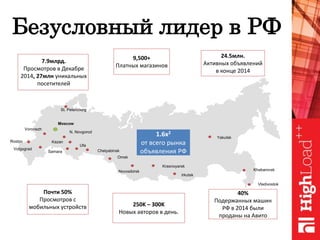
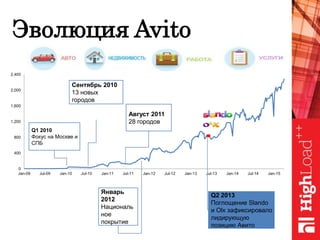

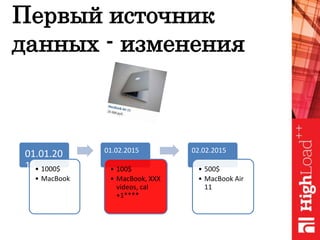
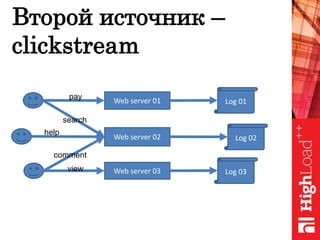
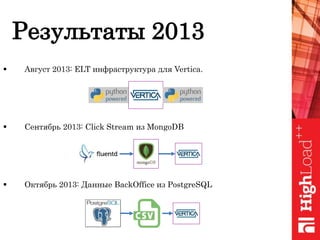
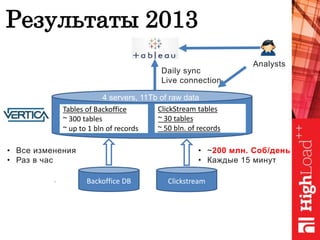






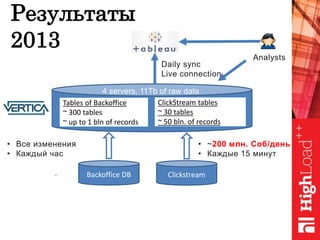

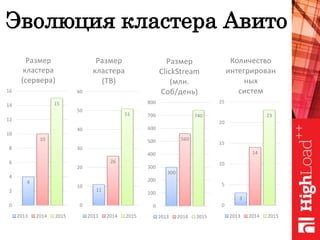


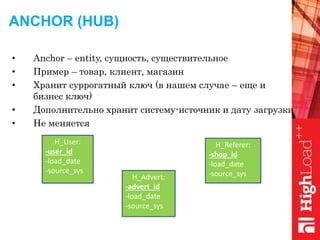
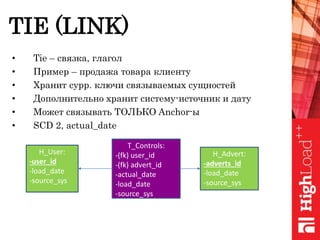
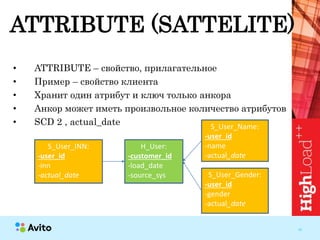
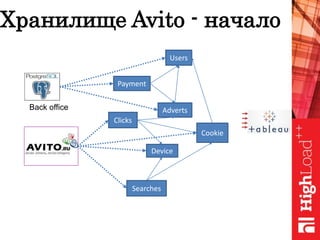
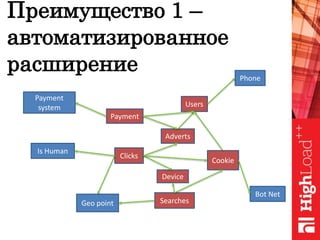

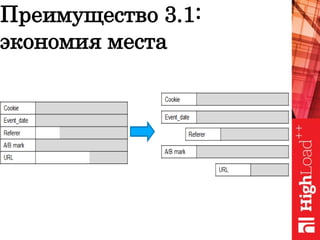
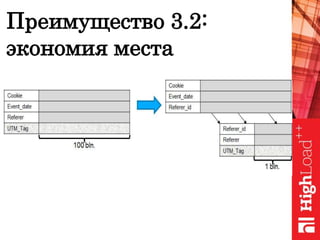
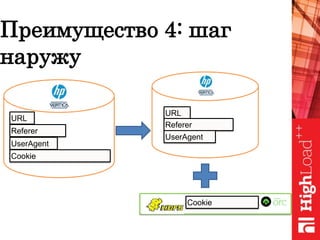


Документ обсуждает важность нормализации в работе с большими данными на примере компании Авито, выделяя ее лидирующую позицию на российском рынке. Приведены данные о росте объема данных и эффективности аналитики, а также о современных методах обработки данных и внедрении автоматизации в процессы. Отмечаются достижения в области обнаружения мошенничества и нелегального контента с использованием искусственного интеллекта.




















































































