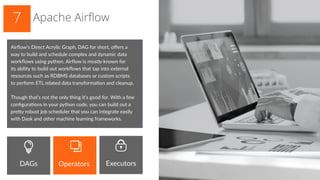
The document discusses 7 different ways to execute scheduled jobs with Python including Apscheduler, crontab, AWS cron jobs, Celery periodic tasks, Timeloop, queue-based decoupled scheduling, and Apache Airflow. It provides details on how each option works and when it would be best to use each one. For example, it notes that Apscheduler is easy to use and supports various backends for job storage, while crontab allows managing cron jobs programmatically from Python code. The document aims to outline options for automating Python and data science solutions through job scheduling.














































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
