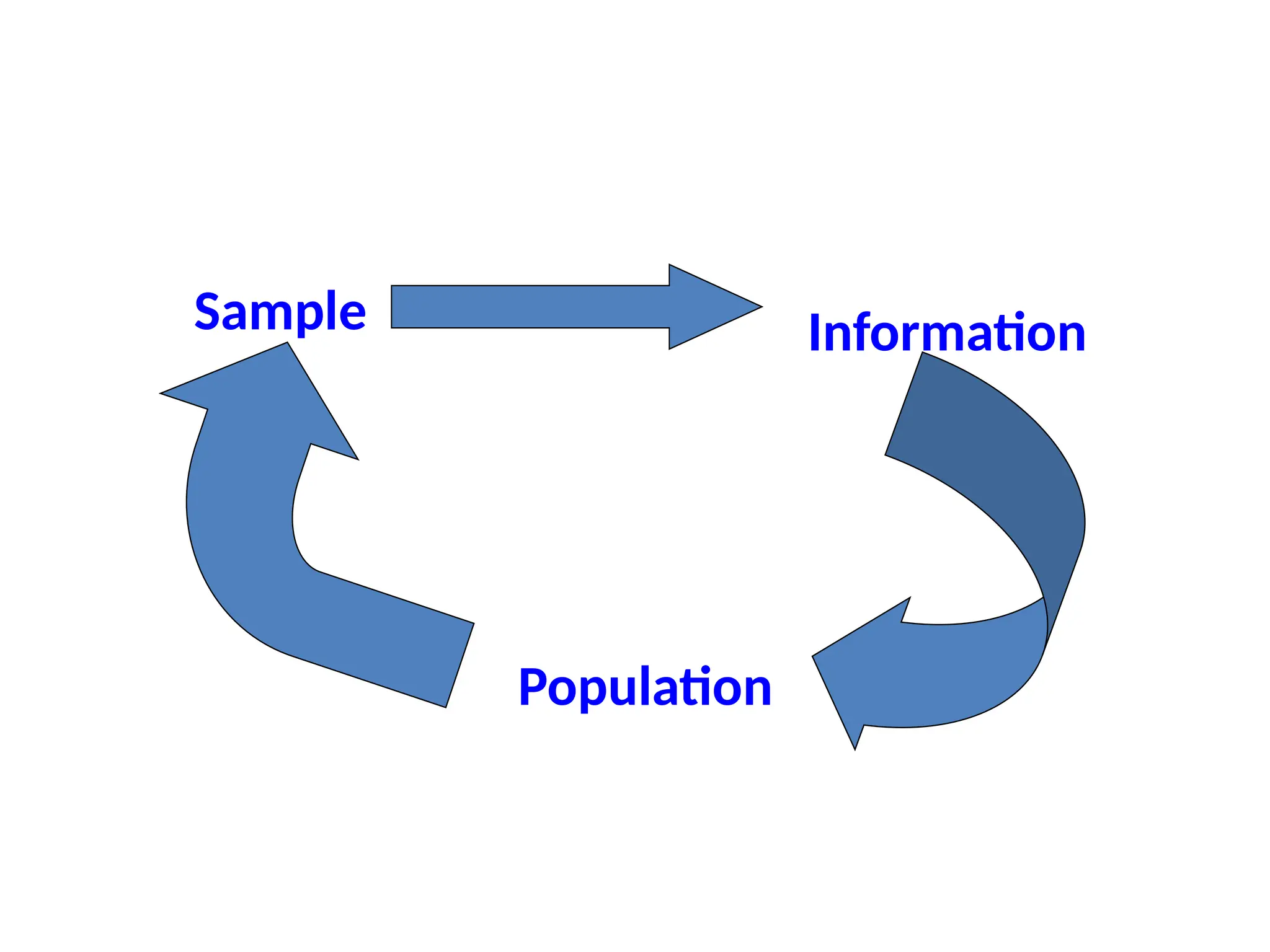
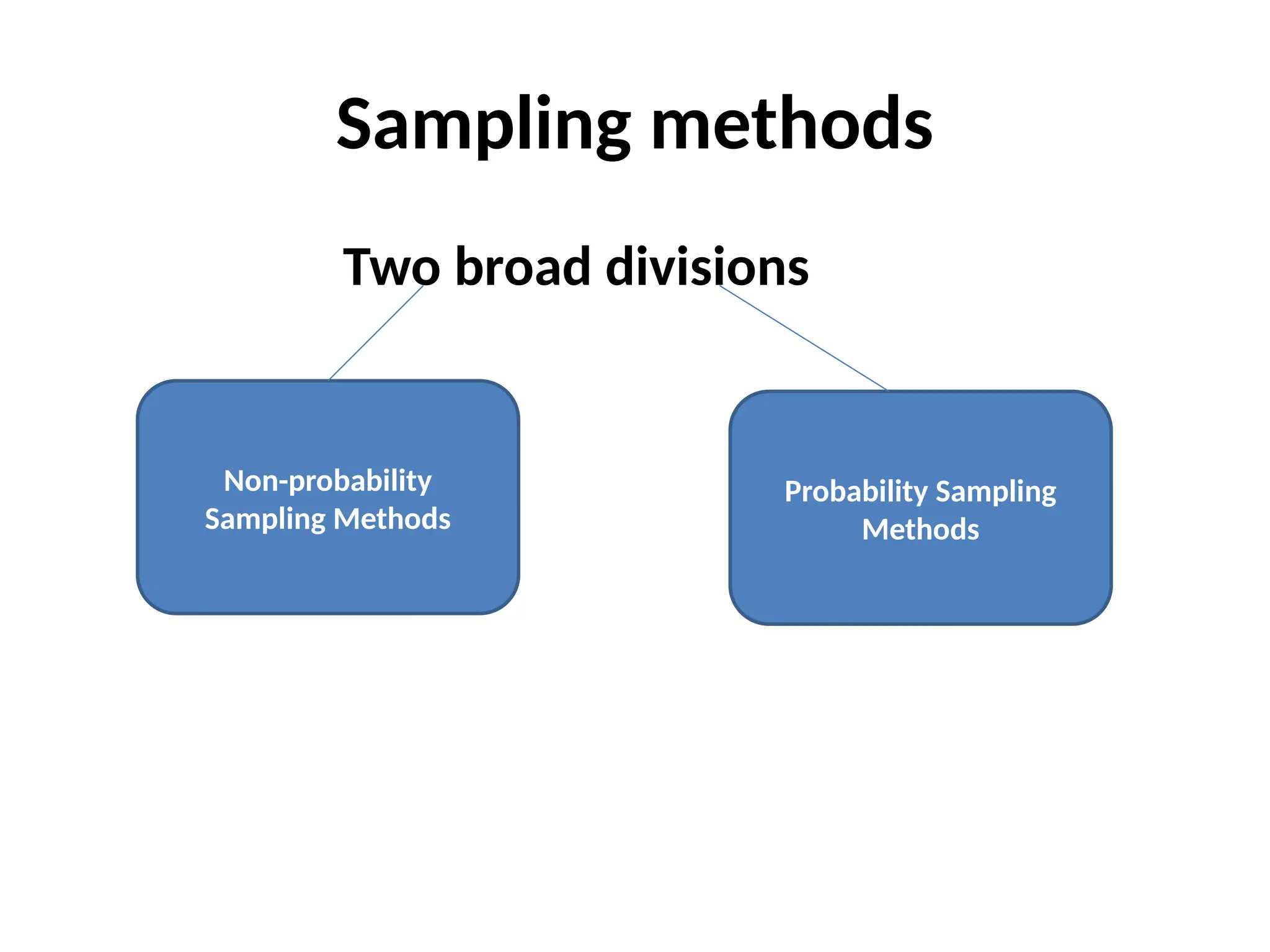
The document provides an overview of elementary sampling theory, defining key concepts such as population, sample, and different sampling methods, including probability and non-probability techniques. It discusses the importance of selecting a representative sample, advantages and limitations of various sampling methods, and outlines the typical procedures involved in probability sampling methods. Additionally, the document emphasizes the necessity of careful planning in designing sample surveys to avoid errors and biases in research outcomes.