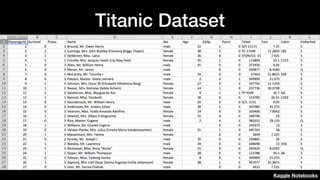
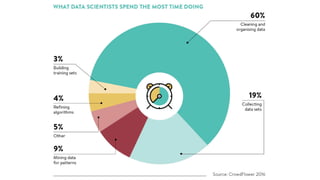
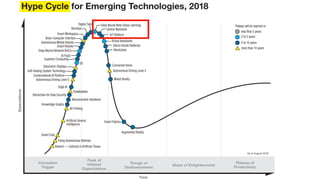
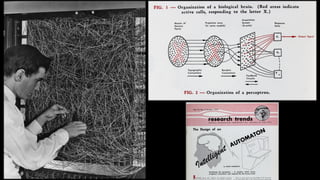
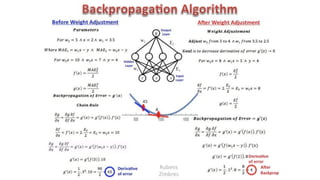
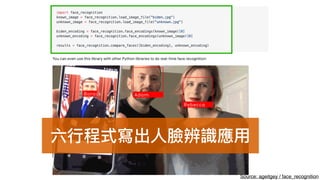
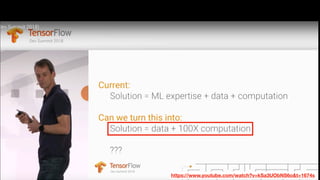
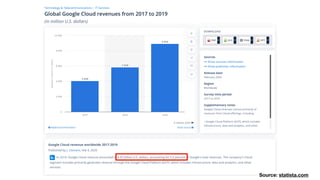
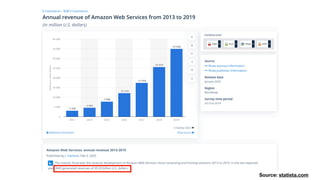
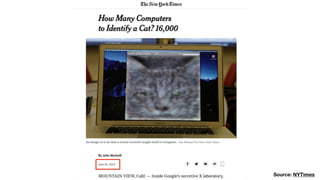
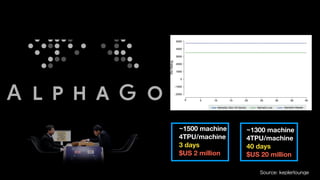
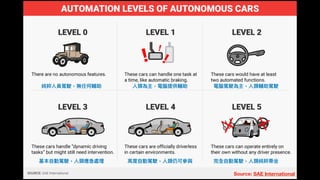
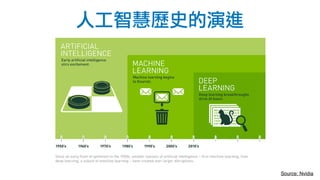
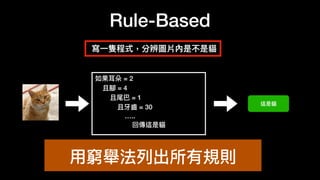
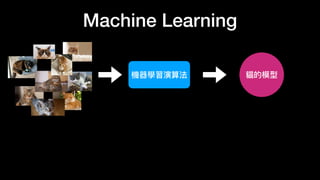
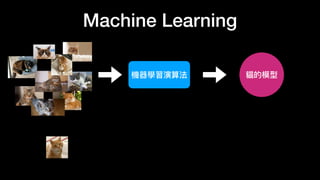
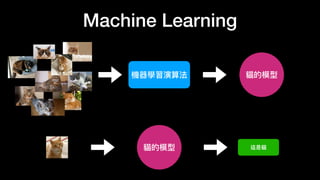
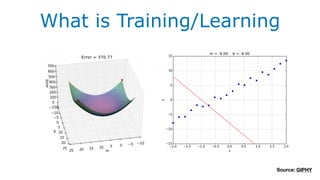
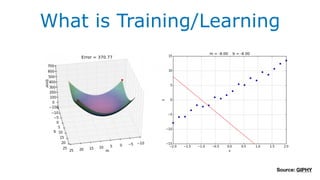
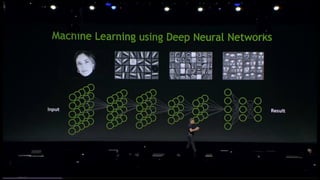
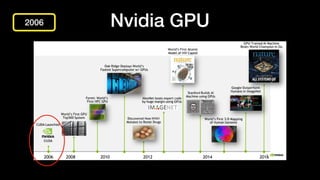
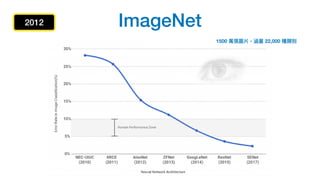
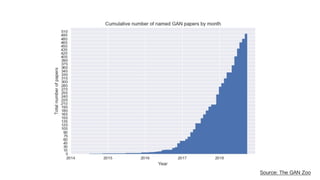
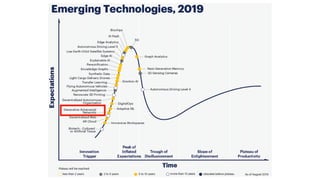
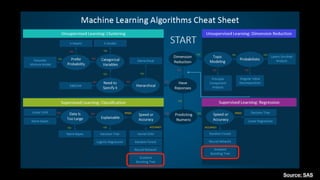
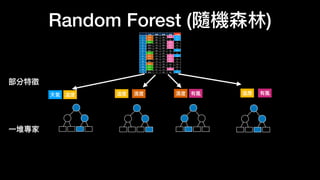
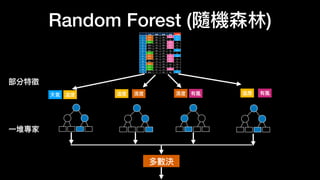
该文档讨论了人工智能和机器学习的历史、发展和应用,包括深度学习、决策树和集成方法等技术。文中提到了一些关键的技术概念、工具和数据质量对算法效果的重要性。还引用了多位专家的观点,分析了人工智能对未来职业的影响。























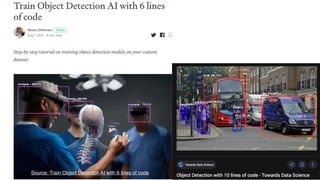


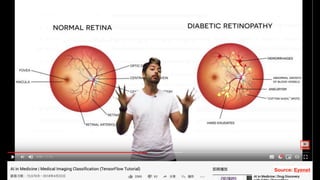



















































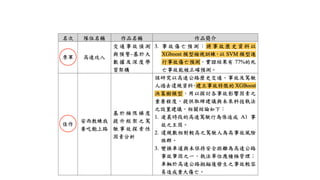


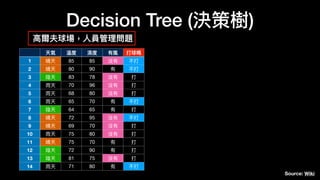
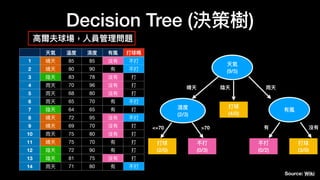
![# imports
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# prepare dataset
iris = load_iris()
X = iris.data
Y = iris.target
# split
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# training
model = DecisionTreeClassifier(max_depth=2)
model.fit(X_train, y_train)
# prediction
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluation
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))](https://image.slidesharecdn.com/20200226aioverview-240319092856-67a4efee/85/20200226-AI-Overview-126-320.jpg)



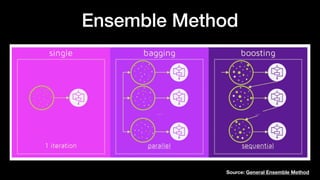


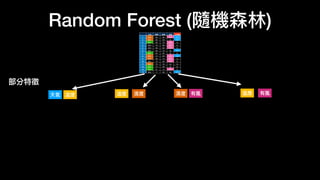










![# imports
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# prepare dataset
iris = load_iris()
X = iris.data
Y = iris.target
# split
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# training
model = DecisionTreeClassifier(max_depth=2)
model.fit(X_train, y_train)
# prediction
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluation
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))](https://image.slidesharecdn.com/20200226aioverview-240319092856-67a4efee/85/20200226-AI-Overview-146-320.jpg)
![# imports
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# prepare dataset
iris = load_iris()
X = iris.data
Y = iris.target
# split
seed = 7
test_size = 0.33
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# training
model = DecisionTreeClassifier(max_depth=2)
model.fit(X_train, y_train)
# prediction
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# evaluation
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
model = XGBClassifier()
from xgboost import XGBClassifier](https://image.slidesharecdn.com/20200226aioverview-240319092856-67a4efee/85/20200226-AI-Overview-147-320.jpg)