Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
sady_nitro
PPTX, PDF
429 views
20181117 azure ml_seminar_3
20181117 Azure Machine Lerning 勉強会 in Okayama (3)
Technology
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 34
2
/ 34
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
8
/ 34
9
/ 34
10
/ 34
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
よりよい UI/UX を創るためのアクセス解析
by
Kentaro Ohkouchi
PPTX
「UI/UXデザインでサイトを改善しよう」EC-CUBE勉強会 vol.16
by
Kentaro Ohkouchi
PDF
Uguisudani
by
Moriyoshi Koizumi
PPTX
Sql world を支える技術
by
Oda Shinsuke
PDF
グラフ解析で社長の脳内さらす!
by
Kazuki Morozumi
PPTX
はじめての datadog
by
Naoya Nakazawa
KEY
Chiba pm#1 - ArangoDB for Perl
by
Hideaki Ohno
PDF
JekyllとBootstrapを使って静的なブログを作ってみたよ
by
Matsuo Obu
よりよい UI/UX を創るためのアクセス解析
by
Kentaro Ohkouchi
「UI/UXデザインでサイトを改善しよう」EC-CUBE勉強会 vol.16
by
Kentaro Ohkouchi
Uguisudani
by
Moriyoshi Koizumi
Sql world を支える技術
by
Oda Shinsuke
グラフ解析で社長の脳内さらす!
by
Kazuki Morozumi
はじめての datadog
by
Naoya Nakazawa
Chiba pm#1 - ArangoDB for Perl
by
Hideaki Ohno
JekyllとBootstrapを使って静的なブログを作ってみたよ
by
Matsuo Obu
What's hot
PPTX
Sikuli x 知っていますか?
by
Masuo Ohara
PDF
Anemoneによるクローラー入門
by
Tasuku Nakano
PDF
write once, publish anywhere ……という夢を見た。
by
Kenshi Muto
PPTX
CUI操作の履歴活用
by
iguto
PDF
Crawler Commons
by
chibochibo
PDF
苫小牧高専 ソフトウェアテクノロジー部 enchant.jsでゲーム作り 5
by
Takuya Mukohira
PDF
SaCSS vol.63 動的なサイトの開発でgulpとBrowserSyncを使ってみる
by
Masashi Murakami
PDF
WordPressで作る世界遺産サイト|カスタムフィールドとカスタム投稿編
by
Yoshinori Kobayashi
PPTX
紙の本大好き人間が送る Kindleライフのすゝめ
by
Serverworks Co.,Ltd.
PDF
20141122 デジコミュ秋田 WordPressサイト永代供養の儀
by
Seiji Akatsuka
Sikuli x 知っていますか?
by
Masuo Ohara
Anemoneによるクローラー入門
by
Tasuku Nakano
write once, publish anywhere ……という夢を見た。
by
Kenshi Muto
CUI操作の履歴活用
by
iguto
Crawler Commons
by
chibochibo
苫小牧高専 ソフトウェアテクノロジー部 enchant.jsでゲーム作り 5
by
Takuya Mukohira
SaCSS vol.63 動的なサイトの開発でgulpとBrowserSyncを使ってみる
by
Masashi Murakami
WordPressで作る世界遺産サイト|カスタムフィールドとカスタム投稿編
by
Yoshinori Kobayashi
紙の本大好き人間が送る Kindleライフのすゝめ
by
Serverworks Co.,Ltd.
20141122 デジコミュ秋田 WordPressサイト永代供養の儀
by
Seiji Akatsuka
Similar to 20181117 azure ml_seminar_3
PPTX
推薦システムを構築する手順書 with Azure Machine Learning
by
Masayuki Ota
PPTX
Azure Machine Learning services 2019年6月版
by
Daiyu Hatakeyama
PPTX
Azure ml
by
vx-pc-club
PDF
Azure Machine Learningによるレコメンデーションの設計&実装を公開!~朝日カルチャーセンターの事例から~
by
貴志 上坂
PPTX
Azure Machine Learning Services 概要 - 2019年2月版
by
Daiyu Hatakeyama
PPTX
東北大学AIE - 機械学習入門編
by
Daiyu Hatakeyama
PDF
Azure Machine Learning getting started
by
Masayuki Ota
PDF
Azure Machine Learning Build 2020
by
Keita Onabuta
PPTX
Microsoft Open Tech Night: Azure Machine Learning - AutoML徹底解説
by
Daiyu Hatakeyama
PPTX
DLLab 2018 - Azure Machine Learning update
by
Daiyu Hatakeyama
PDF
Azure Machine Learning アップデートセミナー 20191127
by
Keita Onabuta
PDF
Azure machine learning service 最新の機械学習プラットフォーム
by
Keita Onabuta
PPTX
Azure Machine Learning Services 概要 - 2019年3月版
by
Daiyu Hatakeyama
PDF
Gpu accelerates aimodeldevelopmentandanalyticsutilizingelasticsearchandazure ai
by
Shotaro Suzuki
PPTX
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
【de:code 2020】 アマダの Azure への取り組みと DevOPS・MLOPS 環境の構築と運用
by
日本マイクロソフト株式会社
PPTX
BrainPad - Doors - A-1 - Microsoft Data and AI
by
Daiyu Hatakeyama
PPTX
0610 TECH & BRIDGE MEETING
by
健司 亀本
推薦システムを構築する手順書 with Azure Machine Learning
by
Masayuki Ota
Azure Machine Learning services 2019年6月版
by
Daiyu Hatakeyama
Azure ml
by
vx-pc-club
Azure Machine Learningによるレコメンデーションの設計&実装を公開!~朝日カルチャーセンターの事例から~
by
貴志 上坂
Azure Machine Learning Services 概要 - 2019年2月版
by
Daiyu Hatakeyama
東北大学AIE - 機械学習入門編
by
Daiyu Hatakeyama
Azure Machine Learning getting started
by
Masayuki Ota
Azure Machine Learning Build 2020
by
Keita Onabuta
Microsoft Open Tech Night: Azure Machine Learning - AutoML徹底解説
by
Daiyu Hatakeyama
DLLab 2018 - Azure Machine Learning update
by
Daiyu Hatakeyama
Azure Machine Learning アップデートセミナー 20191127
by
Keita Onabuta
Azure machine learning service 最新の機械学習プラットフォーム
by
Keita Onabuta
Azure Machine Learning Services 概要 - 2019年3月版
by
Daiyu Hatakeyama
Gpu accelerates aimodeldevelopmentandanalyticsutilizingelasticsearchandazure ai
by
Shotaro Suzuki
実践:今日から使えるビックデータハンズオン あなたはタイタニック号で生き残れるか?知的生産性UPのための機械学習超入門
by
健一 茂木
第1回 Jubatusハンズオン
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
【de:code 2020】 アマダの Azure への取り組みと DevOPS・MLOPS 環境の構築と運用
by
日本マイクロソフト株式会社
BrainPad - Doors - A-1 - Microsoft Data and AI
by
Daiyu Hatakeyama
0610 TECH & BRIDGE MEETING
by
健司 亀本
More from sady_nitro
PDF
What's new with Amazon SageMaker
by
sady_nitro
PPTX
20181117 azure ml_seminar_2
by
sady_nitro
PPTX
20181117 azure ml_seminar_1
by
sady_nitro
PPTX
座駆動LT Surface Go 実機レビュー
by
sady_nitro
PPTX
組合せ最適化問題と解法アルゴリズム
by
sady_nitro
PPTX
オカヤマ コンピュータサイエンス ラボ についてのおはなし
by
sady_nitro
PPTX
RubyとRのおいしい関係
by
sady_nitro
PPTX
Try Azure Machine Learning
by
sady_nitro
PPTX
Comcamp 2016 Okayama VSTS
by
sady_nitro
PPTX
RubySeminar16_Analyze
by
sady_nitro
PPTX
OITEC19_TFS
by
sady_nitro
PPTX
みんな大好き機械学習
by
sady_nitro
What's new with Amazon SageMaker
by
sady_nitro
20181117 azure ml_seminar_2
by
sady_nitro
20181117 azure ml_seminar_1
by
sady_nitro
座駆動LT Surface Go 実機レビュー
by
sady_nitro
組合せ最適化問題と解法アルゴリズム
by
sady_nitro
オカヤマ コンピュータサイエンス ラボ についてのおはなし
by
sady_nitro
RubyとRのおいしい関係
by
sady_nitro
Try Azure Machine Learning
by
sady_nitro
Comcamp 2016 Okayama VSTS
by
sady_nitro
RubySeminar16_Analyze
by
sady_nitro
OITEC19_TFS
by
sady_nitro
みんな大好き機械学習
by
sady_nitro
20181117 azure ml_seminar_3
1.
Azure Machine Learningで 機械学習の実験をやってみよう ~レコメンド編~ 2018.11.17 Azure
Machine Learning勉強会 in Okayama
2.
本セッションについて • Azure Machine
Learning Studioで機械学習の実験をデモ • レコメンドのモデルを学習させて評価する • 学習済みモデルを保存する
3.
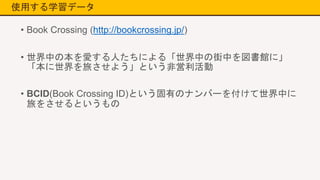
使用する学習データ • Book Crossing
(http://bookcrossing.jp/) • 世界中の本を愛する人たちによる「世界中の街中を図書館に」 「本に世界を旅させよう」という非営利活動 • BCID(Book Crossing ID)という固有のナンバーを付けて世界中に 旅をさせるというもの
4.
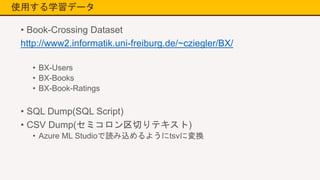
使用する学習データ • Book-Crossing Dataset http://www2.informatik.uni-freiburg.de/~cziegler/BX/ •
BX-Users • BX-Books • BX-Book-Ratings • SQL Dump(SQL Script) • CSV Dump(セミコロン区切りテキスト) • Azure ML Studioで読み込めるようにtsvに変換
5.
使用する学習データ User-ID ISBN Book-Rating User-ID Location Age ISBN Book-Title Book-Author Year-Of-Publication Publisher Image-URL-S Image-URL-M Image-URL-L BX-Book-Ratings BX-Users BX-Books
6.
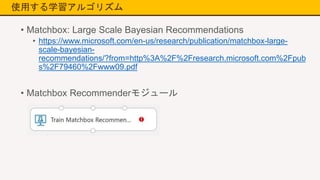
使用する学習アルゴリズム • Matchbox: Large
Scale Bayesian Recommendations • https://www.microsoft.com/en-us/research/publication/matchbox-large- scale-bayesian- recommendations/?from=http%3A%2F%2Fresearch.microsoft.com%2Fpub s%2F79460%2Fwww09.pdf • Matchbox Recommenderモジュール
7.
使用する学習アルゴリズム レーティングデータ UserId ItemId Rating ユーザーデータ UserId UserFeature1 UserFeature2 … アイテムデータ ItemId ItemFeature1 ItemFeature2 … Required Optional Optional
8.
使用する学習アルゴリズム • 協調フィルタリング • アイテムベース •
Amazonとかの「これを買った人は他にこれを買っています」 • ユーザーの属性や購買傾向は考えずアイテム同士の”買い回り”とか”併売”を見る • 推薦の精度はそこそこで学習に必要なデータ量や処理時間は少なめ • ユーザーベース • ユーザーの属性や購買傾向を考慮する • 似た傾向を持つユーザーのまとまりから推薦するアイテムを抽出する • 推薦の精度は上がるが学習に必要なデータ量や処理時間が多め
9.
実験の流れ • データのアップロード • モジュールの配置と接続 •
データの配置 • データの加工 • 学習アルゴリズムの接続 • 学習の結果と評価用モジュールを接続 • 学習の実行 • 学習結果の確認と評価 • 学習モデルを保存
10.
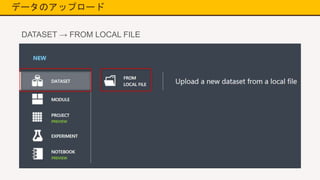
データのアップロード 「+NEW」ボタンをクリック
11.
データのアップロード DATASET → FROM
LOCAL FILE
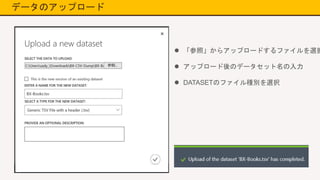
12.
データのアップロード 「参照」からアップロードするファイルを選択 アップロード後のデータセット名の入力
DATASETのファイル種別を選択
13.
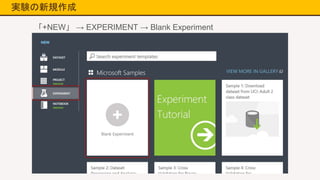
実験の新規作成 「+NEW」 → EXPERIMENT
→ Blank Experiment
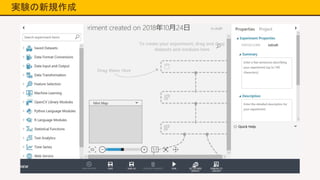
14.
実験の新規作成
15.
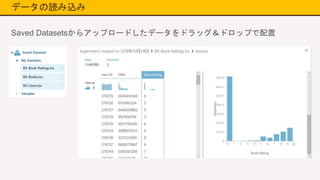
データの読み込み Saved Datasetsからアップロードしたデータをドラッグ&ドロップで配置
16.
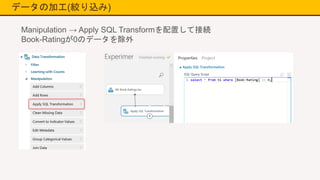
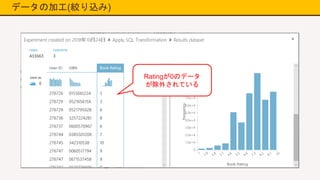
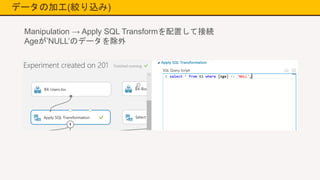
データの加工(絞り込み) Manipulation → Apply
SQL Transformを配置して接続 Book-Ratingが0のデータを除外
17.
データの加工(絞り込み) Ratingが0のデータ が除外されている
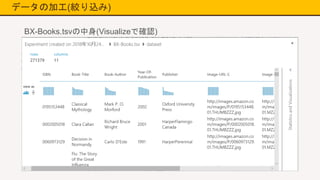
18.
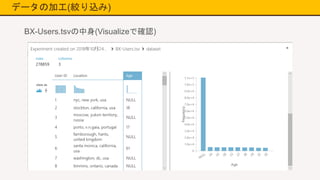
データの加工(絞り込み) BX-Users.tsvの中身(Visualizeで確認)
19.
データの加工(絞り込み) Manipulation → Apply
SQL Transformを配置して接続 Ageが’NULL’のデータを除外
20.
データの加工(絞り込み) BX-Books.tsvの中身(Visualizeで確認)
21.
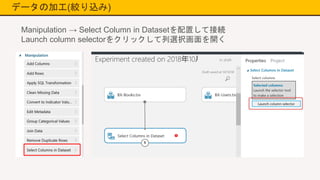
データの加工(絞り込み) Manipulation → Select
Column in Datasetを配置して接続 Launch column selectorをクリックして列選択画面を開く
22.
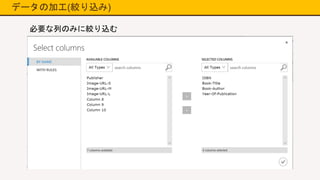
データの加工(絞り込み) 必要な列のみに絞り込む
23.
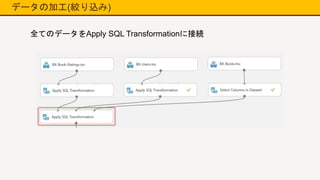
データの加工(絞り込み) 全てのデータをApply SQL Transformationに接続
24.
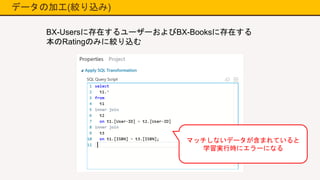
データの加工(絞り込み) BX-Usersに存在するユーザーおよびBX-Booksに存在する 本のRatingのみに絞り込む マッチしないデータが含まれていると 学習実行時にエラーになる
25.
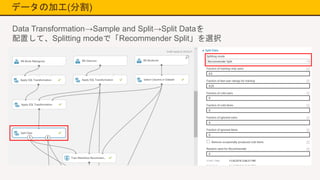
データの加工(分割) Data Transformation→Sample and
Split→Split Dataを 配置して、Splitting modeで「Recommender Split」を選択
26.
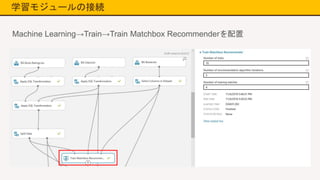
学習モジュールの接続 Machine Learning→Train→Train Matchbox
Recommenderを配置
27.
評価モジュールの接続 Machine Learning→Score→Score Matchbox
Recommenderを配置して Recommender prediction kindで「Item Recommendation」を選択
28.
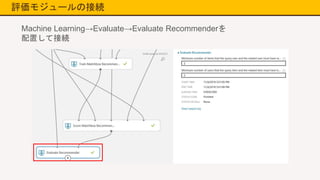
評価モジュールの接続 Machine Learning→Evaluate→Evaluate Recommenderを 配置して接続
29.
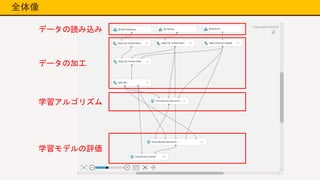
全体像 データの読み込み データの加工 学習アルゴリズム 学習モデルの評価
30.
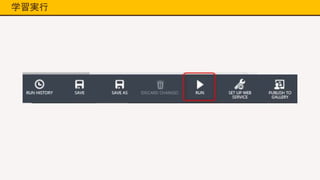
学習実行
31.
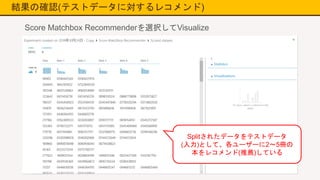
結果の確認(テストデータに対するレコメンド) Score Matchbox Recommenderを選択してVisualize Splitされたデータをテストデータ (入力)として、各ユーザーに2~5冊の 本をレコメンド(推薦)している
32.
結果の確認(レコメンドの精度) Evaluate Recommenderを選択してVisualize Normalized Discounted
Cumulative Gain (NDCG) 0~1の値で1に近いほど正しい予測結果
33.
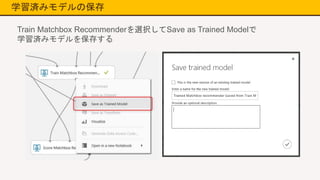
学習済みモデルの保存 Train Matchbox Recommenderを選択してSave
as Trained Modelで 学習済みモデルを保存する
34.
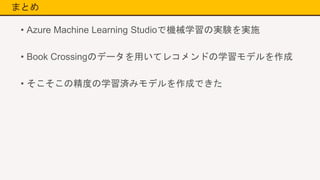
まとめ • Azure Machine
Learning Studioで機械学習の実験を実施 • Book Crossingのデータを用いてレコメンドの学習モデルを作成 • そこそこの精度の学習済みモデルを作成できた
Download