perlsub - Perlのサブルーチン
http://perldoc.jp/docs/perl/5.22.1/perlsub.pod
Any arguments passed in show up in the array @_. (They may also show
up in lexical variables introduced by a signature; see "Signatures"
below.) Therefore, if you called a function with two arguments, those
would be stored in $_[0] and $_[1]. The array @_ is a local array,
but its elements are aliases for the actual scalar parameters. In
particular, if an element $_[0] is updated, the corresponding
argument is updated (or an error occurs if it is not updatable).
ルーチンに渡されるすべての引数は配列 @_ に置かれます。 (シグネチャに
よって導入されたレキシカル変数にも現れることがあります; 後述する
"Signatures" を参照してください。) したがって、ある関数を二つの引数を
付けて呼び出したならば、 その引数は $_[0] と $_[1] に格納されます。
配列 @_ は local 配列ですが、その要素は実際の スカラパラメータの別名
です。 たとえば $_[0] が更新された場合、対応する引数が更新されます
(更新できない場合にはエラーとなります)。



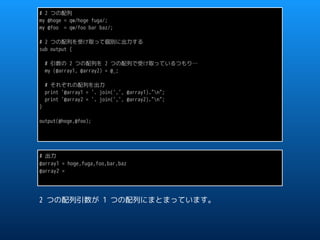


![sub output {
my (@array1, @array2) = @_;
# @_ の値は “hoge”,”fuga”,”foo”,”bar”,”baz"
# つまり
# $_[0] = hoge
# $_[1] = fuga
# $_[2] = foo
# $_[3] = bar
# $_[4] = bat
・・・
これを回避するためには、サブルーチンの引数を「 リファレンス 」と
して渡します。](https://image.slidesharecdn.com/20170401alias-170401143247/85/20170401-alias-7-320.jpg)
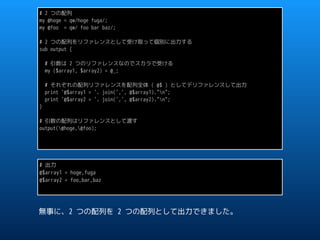




![perlsub - Perl のサブルーチン
http://perldoc.jp/docs/perl/5.22.1/perlsub.pod
Any arguments passed in show up in the array @_. (They may also show
up in lexical variables introduced by a signature; see "Signatures"
below.) Therefore, if you called a function with two arguments, those
would be stored in $_[0] and $_[1]. The array @_ is a local array,
but its elements are aliases for the actual scalar parameters. In
particular, if an element $_[0] is updated, the corresponding
argument is updated (or an error occurs if it is not updatable).
ルーチンに渡されるすべての引数は配列 @_ に置かれます。 (シグネチャに
よって導入されたレキシカル変数にも現れることがあります; 後述する
"Signatures" を参照してください。) したがって、ある関数を二つの引数を
付けて呼び出したならば、 その引数は $_[0] と $_[1] に格納されます。
配列 @_ は local 配列ですが、その要素は実際の スカラパラメータの別名
です。 たとえば $_[0] が更新された場合、対応する引数が更新されます
(更新できない場合にはエラーとなります)。](https://image.slidesharecdn.com/20170401alias-170401143247/85/20170401-alias-14-320.jpg)







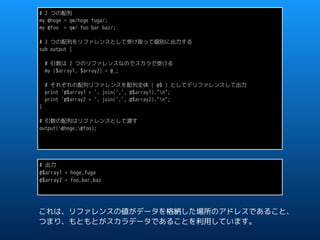
![use Data::Dumper;
my %hash = (key1 => 'val1', key2 => 'val2');
my @arry = qw/elm1 elm2 elm3/;
output4(%hash, @arry);
sub output4 {
# @_ のデータ構造を出力
print Dumper @_;
}
ためしにハッシュと配列を引数として渡してみると、
$VAR1 = [
'key2',
'val2',
'key1',
'val1',
'elm1',
'elm2',
'elm3'
];
@_ のデータ構造は次のような単純なリストデータとして扱われます。](https://image.slidesharecdn.com/20170401alias-170401143247/85/20170401-alias-22-320.jpg)

![use Data::Dumper;
my %hash = (key1 => 'val1', key2 => 'val2');
my @arry = qw/elm1 elm2 elm3/;
# 引数はリファレンス
output4(%hash, @arry);
sub output4 {
# @_ のデータ構造を出力
print Dumper @_;
}
ハッシュと配列のリファレンスを引数として渡すと、
$VAR1 = [
{
'key2' => 'val2',
'key1' => 'val1'
},
[
'elm1',
'elm2',
'elm3'
]
];
@_ のデータ構造は、元のデータ構造を保持します。](https://image.slidesharecdn.com/20170401alias-170401143247/85/20170401-alias-24-320.jpg)


![Perl ユーザは、ある程度のレベルから「リファレンス/デリファレン
ス」および無名配列リファレンス ( [ ] )、無名ハッシュリファレン
ス ( { } )、無名コードリファレンス ( sub{ } ) などを空気のよう
に扱うようになります。
また、サブルーチンの応用形である各種ライブラリ・モジュールの作
成・利用などでは、任意のデータ構造を適切に扱うために「リファレ
ンス/デリファレンス」の利用がほとんど必須になっています。](https://image.slidesharecdn.com/20170401alias-170401143247/85/20170401-alias-27-320.jpg)
























































