Download to read offline



















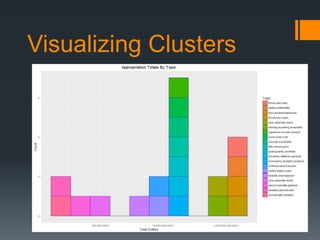



This document discusses unsupervised machine learning techniques like k-means clustering and its application to natural language processing. It provides examples of how k-means clustering can be used to group text documents by transforming them into numeric feature vectors using techniques like bag-of-words modeling. The document suggests that combining machine learning, news articles, and clustering could provide insights and generate business value, for example by discovering trends in news stories or visualizing topic clusters.























































