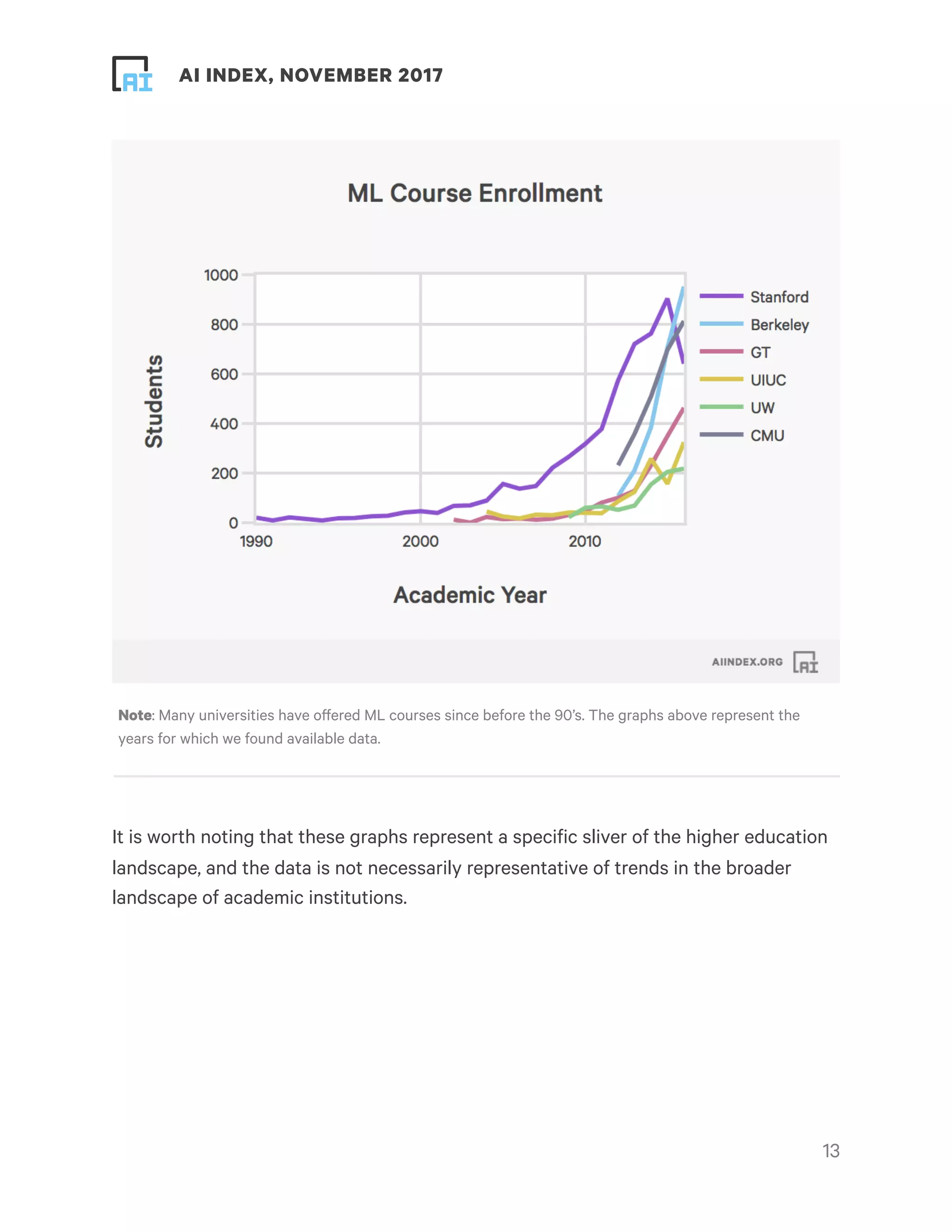
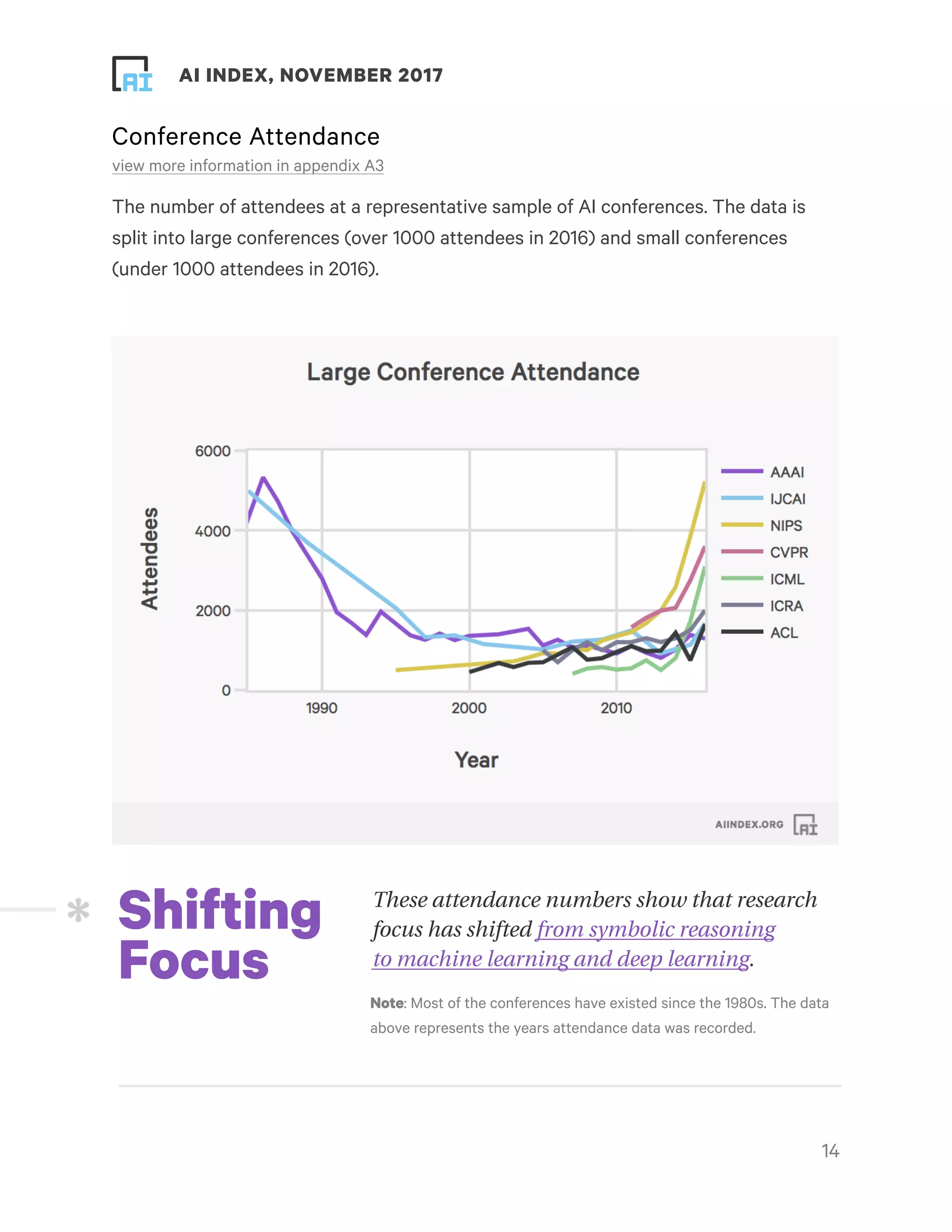
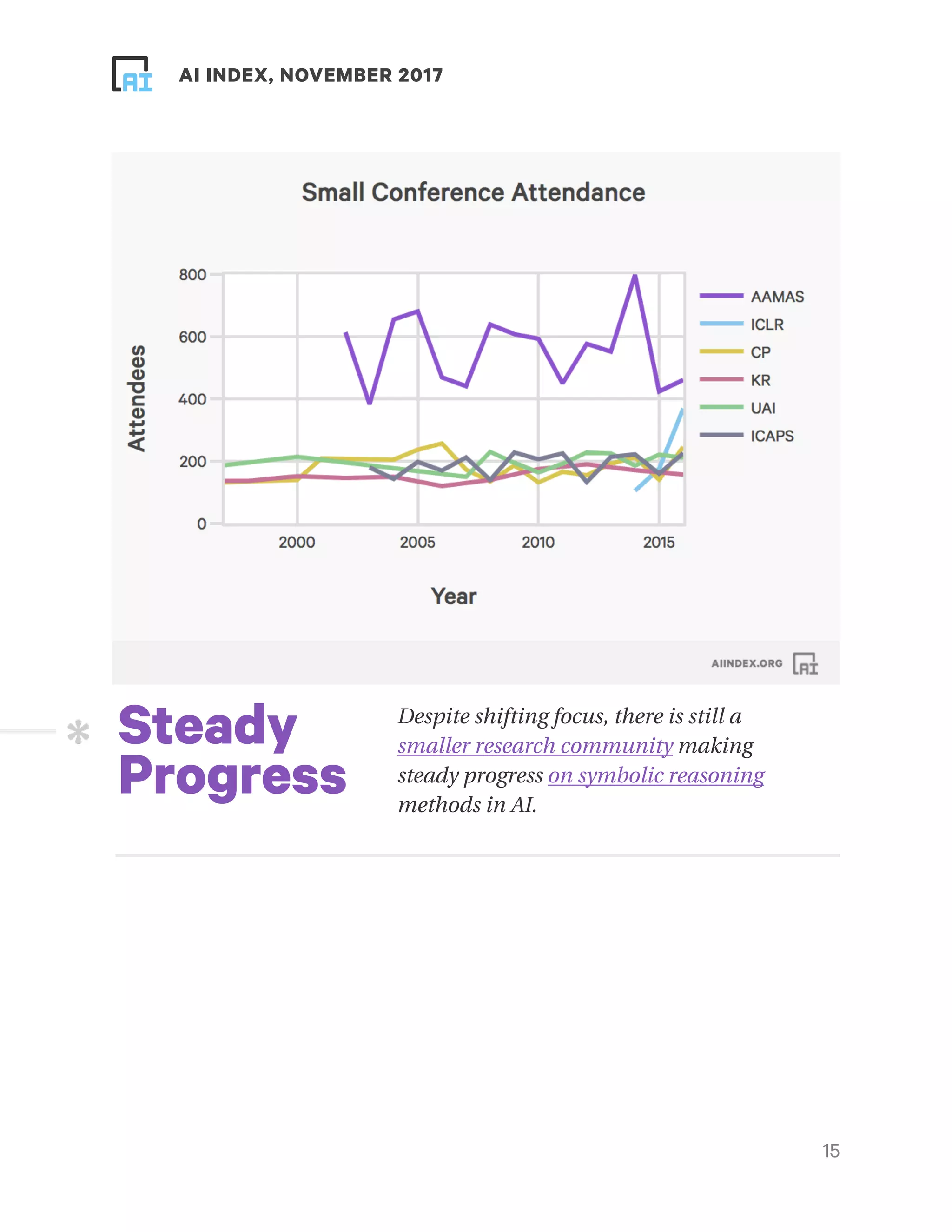
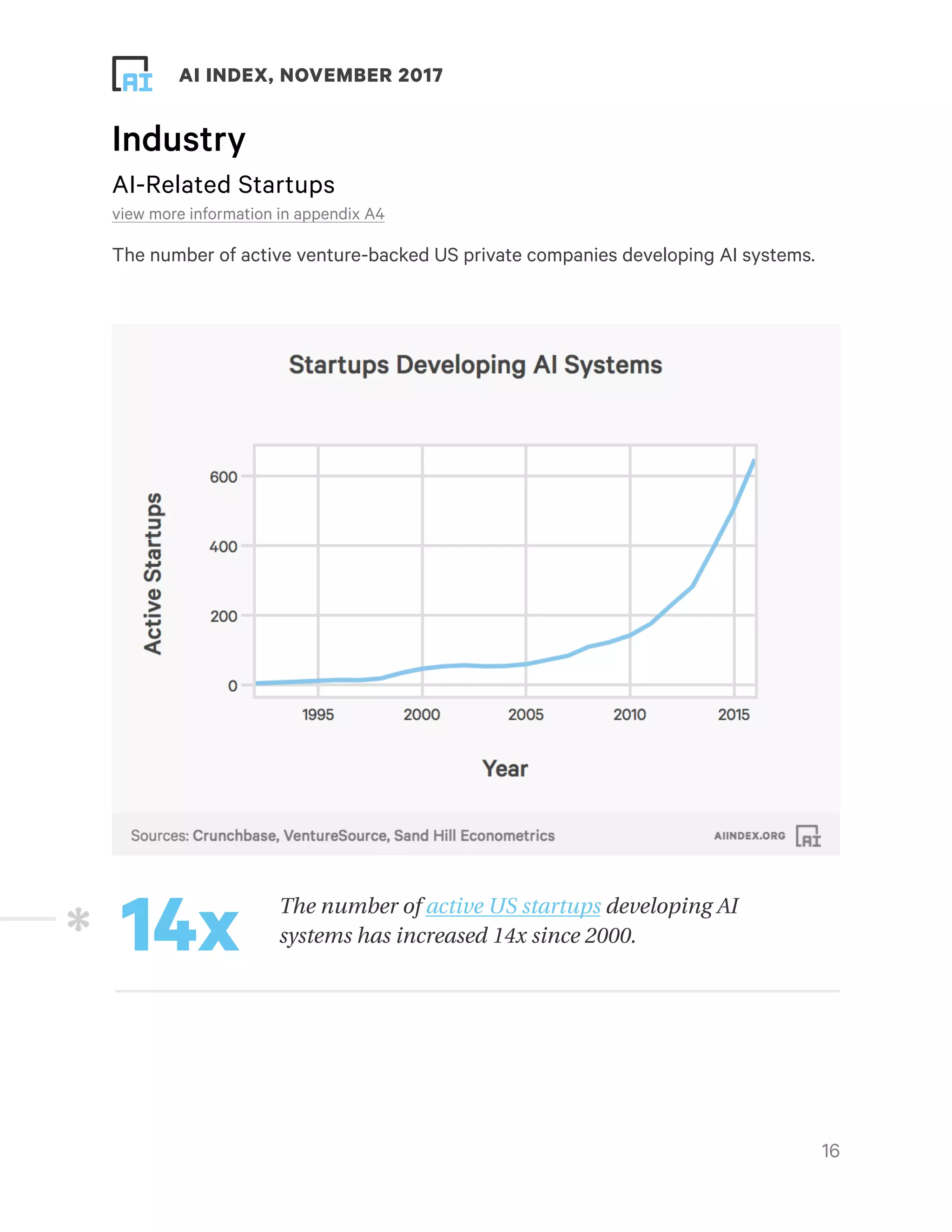
This document provides an overview and summary of key findings from the AI Index 2017 Annual Report. It highlights increasing activity and progress in artificial intelligence as seen through metrics on academia, industry, technical performance, and efforts towards human-level performance. The number of academic papers, university course enrollment, conference attendance, startups, funding, and job openings related to AI have all increased substantially in recent years. Technical performance on tasks like object detection, machine translation, and question answering has also improved. However, the report notes that its analysis is limited and biased towards certain perspectives, and more data is needed for a complete picture of the field. It calls for community participation to help track and understand progress in AI.

































![! ! AI INDEX, NOVEMBER 2017
• Universal Declaration of Human Rights
• Declaration on Rights of Indigenous Peoples
• Beijing Declaration and Platform for Action on women’s human rights
• Convention on the Rights of Persons with Disabilities
• International Covenant on Economic, Social and Cultural Rights
• IEEE Ethically Aligned Design General Principles - esp Principle 1 on Human
Benefit lists (p16)
At MIT’s Commencement June 2017 Tim Cook, CEO of Apple Computer, said:
“I’m not worried about artificial intelligence giving computers the ability to think like
humans. I’m more concerned about people thinking like computers without values or
compassion, without concern for consequences. That is what we need you to help us
guard against. Because if science is a search in the darkness, then the humanities are
a candle that shows us where we’ve been and the danger that lies ahead. As Steve
[Jobs] once said, technology alone is not enough. It is technology married with the
liberal arts married with the humanities that make our hearts sing. When you keep
people at the center of what you do, it can have an enormous impact.”
We need to be broadly aware of leadership work by organizations, associations and
individuals collaborating to take action - for example:
• The Algorithmic Justice League (www.ajlunited.org/), which highlights
algorithmic bias, provides space for people to voice concerns and experiences
with coded bias, and develops practices for accountability.
• The petition to the UN urging rapid action on weaponized AI to compel us to
globally engage asap on this topic.
• The Computer Science for All Movement (CSforAll - csforallconsortium.org/) for
tech inclusion in the U.S. and in other countries.
• The AI4All initiative (ai-4-all.org/), to train a new and more diverse generation of
future AI technologists, thinkers, and leaders.
!62](https://image.slidesharecdn.com/2017-report2-171227174203/75/2017-AI-Index-report-62-2048.jpg)




















![! ! AI INDEX, NOVEMBER 2017
SELECT
project,
YEAR(star_date) as yearly,
MONTH(star_date) as monthly,
SUM(daily_stars) as monthly_stars
FROM (
SELECT
repo.name as project,
DATE(created_at) as star_date,
COUNT(*) as daily_stars
FROM
TABLE_DATE_RANGE(
[githubarchive:day.],
TIMESTAMP(“20160101"),
TIMESTAMP(“20161231"))
WHERE
repo.name IN (
“tensorflow/tensorflow",
“fchollet/keras",
“apache/incubator-mxnet",
“scikit-learn/scikit-learn",
"caffe2/caffe2", "pytorch/pytorch",
"Microsoft/CNTK", “Theano/Theano",
"dmlc/mxnet", "BVLC/caffe")
AND type = ‘WatchEvent’
GROUP BY project, star_date
)
GROUP BY project, yearly, monthly
ORDER BY project, yearly, monthly
!85](https://image.slidesharecdn.com/2017-report2-171227174203/75/2017-AI-Index-report-85-2048.jpg)






































![iSkysoft Data Recovery 5.0.1.3 Crack + Serial Key [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligence22-250528111409-7bb27b53-thumbnail.jpg?width=640&height=640&fit=bounds)

![Directory Lister Pro 2.42 Enterprise + Crack Download [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligence22-250528124124-08bcb9e9-thumbnail.jpg?width=640&height=640&fit=bounds)
![NIUBI Partition Editor 7.3.7 + License Key [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligence22-250529151611-84713241-thumbnail.jpg?width=640&height=640&fit=bounds)
![GridinSoft Anti-Malware 4.1.74 Crack + Activation Code [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligence22-250529091117-4735c160-thumbnail.jpg?width=640&height=640&fit=bounds)
![TuneFab Spotify Music Converter 3.1.3 + Crack [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligence22-250529070550-59b281b6-thumbnail.jpg?width=640&height=640&fit=bounds)

![EndNote Crack 20 Build 14672 + Serial Key Free Download [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligence22-250602144051-91223e8c-thumbnail.jpg?width=640&height=640&fit=bounds)


![Prism Video Converter Plus 6.91 Crack + Registration Code [Latest]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligence24-250528124915-f42662af-thumbnail.jpg?width=640&height=640&fit=bounds)



















