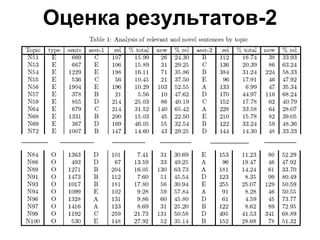
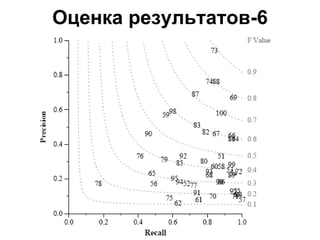
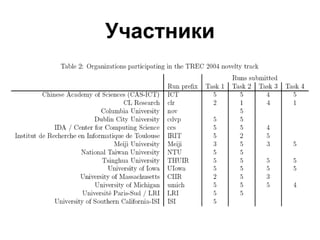
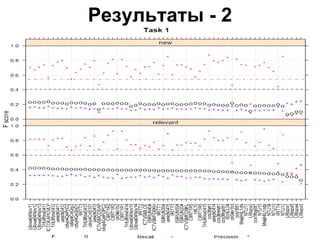
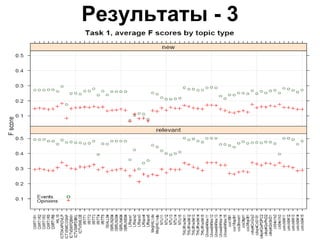
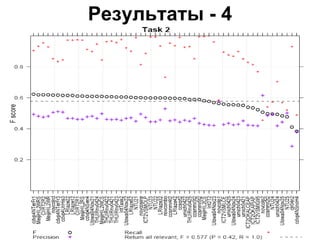
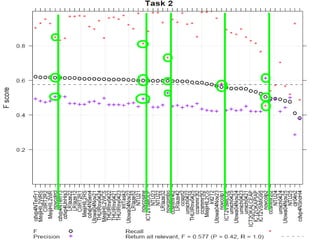
Документ обсуждает определение новизны информации в новостном кластере и сложности, связанные с извлечением новой информации из потока документов. Он описывает задачи и подходы, используемые в конференции TREC для оценки релевантности и новизны предложений в новостных текстах, а также результаты экспериментов с различными методами и системами. Акцентируется внимание на необходимости доработки векторно-пространственной модели для более эффективного обнаружения новых идей и информации.