Arrays
• a collectionof items stored at contiguous memory locations.
The idea is to store multiple items of the same type together.
3.
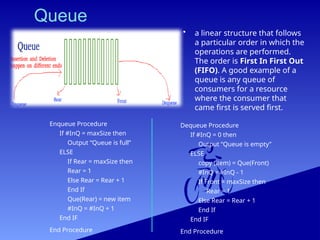
Queue
• a linearstructure that follows
a particular order in which the
operations are performed.
The order is First In First Out
(FIFO). A good example of a
queue is any queue of
consumers for a resource
where the consumer that
came first is served first.
Enqueue Procedure
If #InQ = maxSize then
Output “Queue is full”
ELSE
If Rear = maxSize then
Rear = 1
Else Rear = Rear + 1
End If
Que(Rear) = new item
#InQ = #InQ + 1
End IF
End Procedure
Dequeue Procedure
If #InQ = 0 then
Output “Queue is empty”
ELSE
copy (item) = Que(Front)
#InQ = #InQ - 1
If Front = maxSize then
Rear = 1
Else Rear = Rear + 1
End If
End IF
End Procedure
4.
Stack
• Linear datastructure in which elements can be
inserted and deleted only from one side of the list,
called the top. A stack follows the LIFO (Last In
First Out) principle
Push Procedure
If Top = maxSize then
Output “stack is full”
ELSE
Top = Top + 1
Stack(Top) = new item
End IF
End Procedure
Pop Procedure
If Top =0 then
Output “stack is empty”
ELSE
copy (item) = Stack(Top)
Top = Top - 1
End IF
End Procedure
5.
Records and Pointers
1.Records
• Definition:
• A record is a collection of related data items, often of
different data types. Think of it as a way to group variables
together under a single name.
• Each data item within a record is called a "field."
• For example, a record representing a student might contain
fields for their name (string), ID (integer), and GPA (floating-
point number).
• Purpose:
– Records provide a structured way to organize complex data,
making it easier to manage and access.
– They are essential for representing real-world entities in
computer programs.
6.
Records and Pointers
2.Pointers
• Definition:
– A pointer is a variable that stores the memory address of another
variable or data structure.
– Instead of holding the actual data, a pointer "points" to where the data is
located in memory.
• Purpose:
– Pointers enable dynamic memory allocation, allowing you to create and
destroy data structures as needed during program execution.
– They are crucial for implementing linked data structures, such as linked
lists, trees, and graphs, where elements are connected by references
rather than stored in contiguous memory locations.
– They enable the creation of data structures that can change size during
program execution.
7.
Pointers
• Imagine apointer referencing an integer:
• C
• int num = 42; //Actual data
• int ptr = # //Pointer storing the address of
'num'
• You can access `num` indirectly via `ptr`:
• C
• printf("%d", *ptr); // Outputs: 42
8.
LISTS
• A listis an ordered, mutable data
structure that holds a collection of
items, allowing for duplicate
elements, lists are important for
efficient data storage and retrieval,
employing indices to access elements
directly.
• There are array lists and linked lists.
9.
LINKED LISTS
• Adynamic data structure
• Allows non contiguous memory
allocation
• Can be used to make stacks, graphs
and queues
• Efficient insertion and deletion
• Access is sequential
Start = 5
NextFree = 6
10.
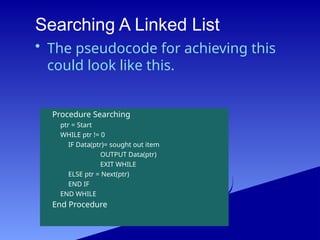
Searching A LinkedList
Procedure Searching
ptr = Start
WHILE ptr != 0
IF Data(ptr)= sought out item
OUTPUT Data(ptr)
EXIT WHILE
ELSE ptr = Next(ptr)
END IF
END WHILE
End Procedure
• The pseudocode for achieving this
could look like this.
11.
Removing an Itemfrom A Linked List
Procedure Traversal
ptr = Start
Nextptr = Start
IF Data(ptr) = itemtoRemove THEN
START = Next(ptr)
EXIT Procedure
END IF
WHILE ptr != 0
IF Data(ptr)= itemtoRemove THEN
Next(Prevptr) = Next(Ptr)
EXIT Procedure
END IF
Prevptr = ptr
Ptr = Next(ptr)
END IF
END WHILE
End Procedure
• Simply a matter of adjusting a pointer to effectively remove the item
12.
Building A linkedlist
Store new itematNextFree pointer
Identify new item’s place in list
If new start
Set new item’s pointer to previous start value
Reset start to new item
ELSE
Temporarily store preceding item’s pointer
Set preceding item’s pointer to point to the new item
Set new item’s pointer to predecing item’s old pointer
End if
Increment NextFree pointer
• Simply a matter of adjusting a pointer to effectively remove the item
13.
Disjoint Set Structures
•is a data structure that stores a collection of disjoint (non-
overlapping) sets.
• Equivalently, it stores a partition of a set into disjoint subsets. It
provides operations for adding new sets, merging sets
(replacing them with their union), and finding a representative
member of a set.
• Each node in a disjoint-set forest consists of a pointer and some
auxiliary information, either a size or a rank (but not both). The
pointers are used to make parent pointer trees, where each
node that is not the root of a tree points to its parent.
Operations
• Making a new set containing a new element
• Finding the representative of the set containing a given element
• Merging two sets.
14.
Making new sets
TheMakeSet operation adds a new element into a new set
containing only the new element
function MakeSet(x) is
if x is not already in the forest then
x.parent := x
x.size := 1 // if nodes store size
x.rank := 0 // if nodes store rank
end if
end function
This operation has linear time complexity. In particular,
initializing a disjoint-set forest with n nodes requires O(n) time.
15.
Merging two sets
Theoperation Union(x, y) replaces the set containing x and the set
containing y with their union.
Union first uses Find to determine the roots of the trees containing
x and y. If the roots are the same, there is nothing more to do.
Otherwise, the two trees must be merged.
This is done by either setting the parent pointer of x's root to y's, or
setting the parent pointer of y's root to x's.
Union by size
a node stores its size, which is simply its number of descendants
(including the node itself). When the trees with roots x and y are
merged, the node with more descendants becomes the parent.
16.
function Union(x, y)is
// Replace nodes by roots
x := Find(x)
y := Find(y)
if x = y then
return // x and y are already in the same set
end if
// If necessary, swap variables to ensure that
// x has at least as many descendants as y
if x.size < y.size then
(x, y) := (y, x)
end if // Make x the new root y.parent := x
// Update the size of x
x.size := x.size + y.size
end function
17.
Associative table datastructures
data structures that allow you to associate keys with values. This
enables
efficient retrieval of values based on their corresponding keys.
Core Concept: Associative Arrays
• Key-Value Pairs:
– The fundamental idea is to store data as pairs, where each pair consists of
a "key" and a "value."
– The "key" acts as a unique identifier for the "value."
– This allows you to look up a "value" quickly by providing its "key."
• Terminology:
– Associative arrays are also commonly known as:
• Dictionaries (in Python)
• Maps (in C++, Java)
• Hash maps
• Symbol tables
18.
Hash Tables:
– Thisis the most common and generally most efficient implementation.
– A "hash function" is used to map keys to indices in an array (the "hash
table").
– This allows for very fast average-case lookups (O(1)).
– However, in worst-case scenarios (hash collisions), performance can
degrade.
• Binary Search Trees:
– Specifically, self-balancing binary search trees (like AVL trees or red-black
trees).
– These maintain a sorted order of keys, allowing for efficient searches.
– Lookups, insertions, and deletions typically have a time complexity of O(log
n).
• Association Lists:
– A simple implementation using a list of key-value pairs.
– Lookups involve iterating through the list, which can be slow (O(n)).
– Generally used for small datasets where performance is not critical.