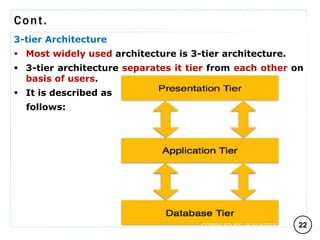
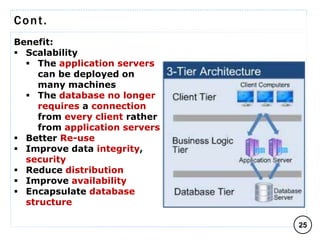
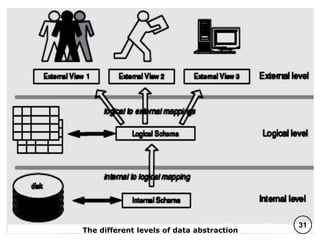
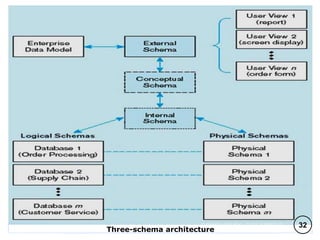
The document discusses various data models and their architectures for database management systems (DBMS), including object-based, record-based, and physical data models. It covers the evolution of data models, the structure of databases through concepts like schemas and instances, and the advantages of the relational model. Additionally, it explains DBMS architectures such as one-tier, two-tier, and three-tier models, along with the general principles of data abstraction and independence within these systems.





























![Database System Concepts AND architecture [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/databasesystemconceptsandarchitectureautosaved-230817173311-be7f8590-thumbnail.jpg?width=640&height=640&fit=bounds)













































