Downloaded 15 times








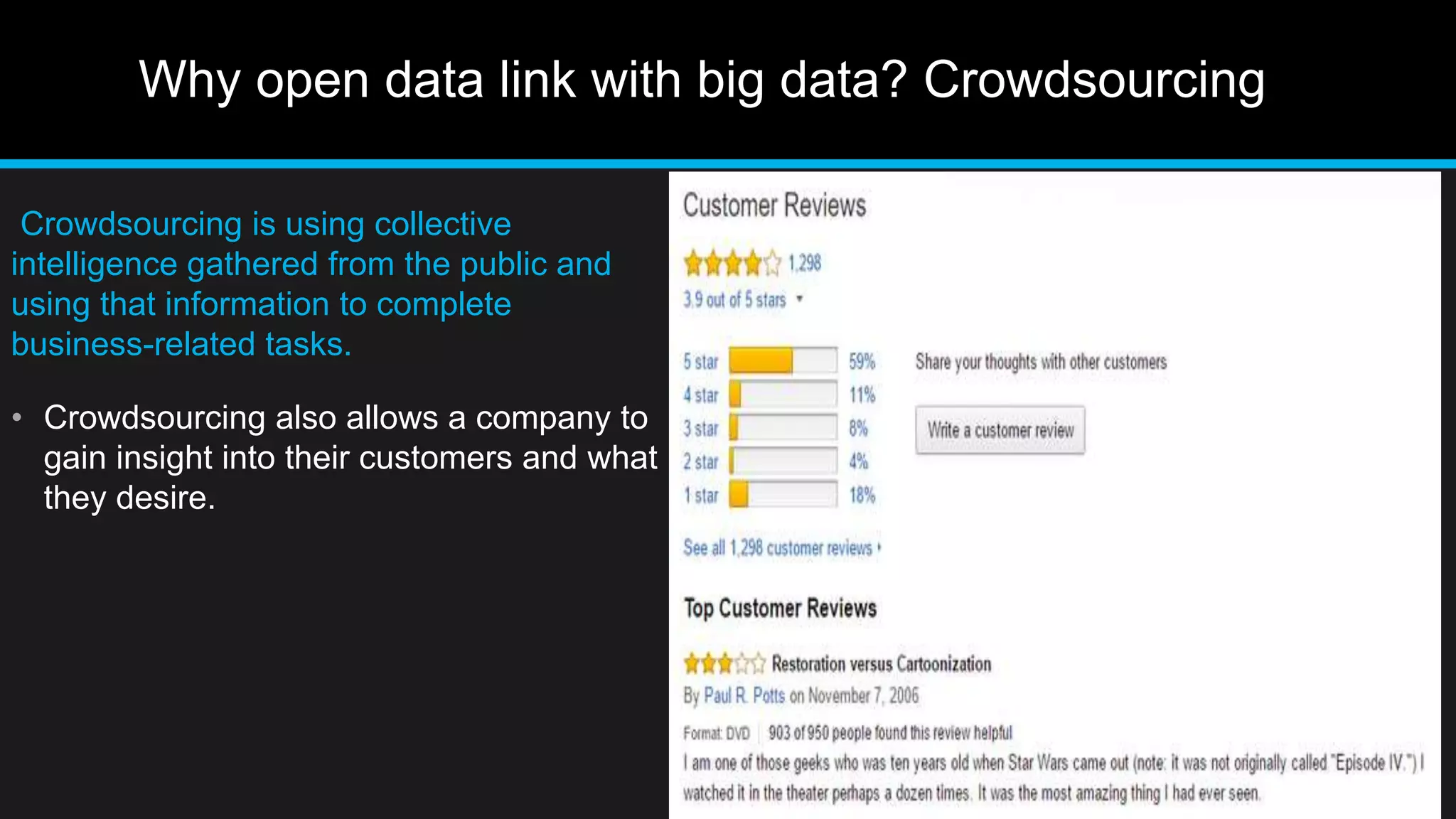
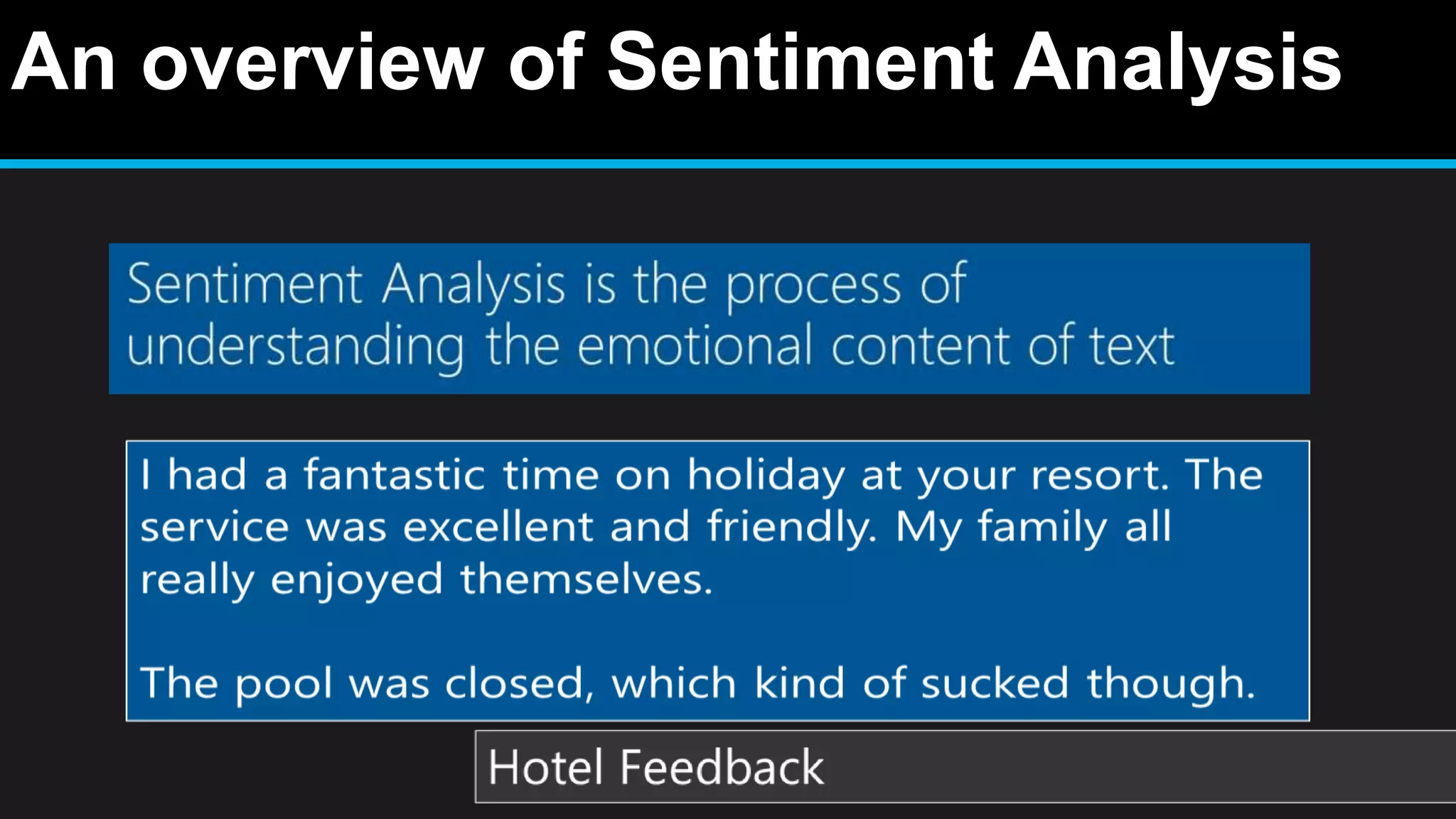


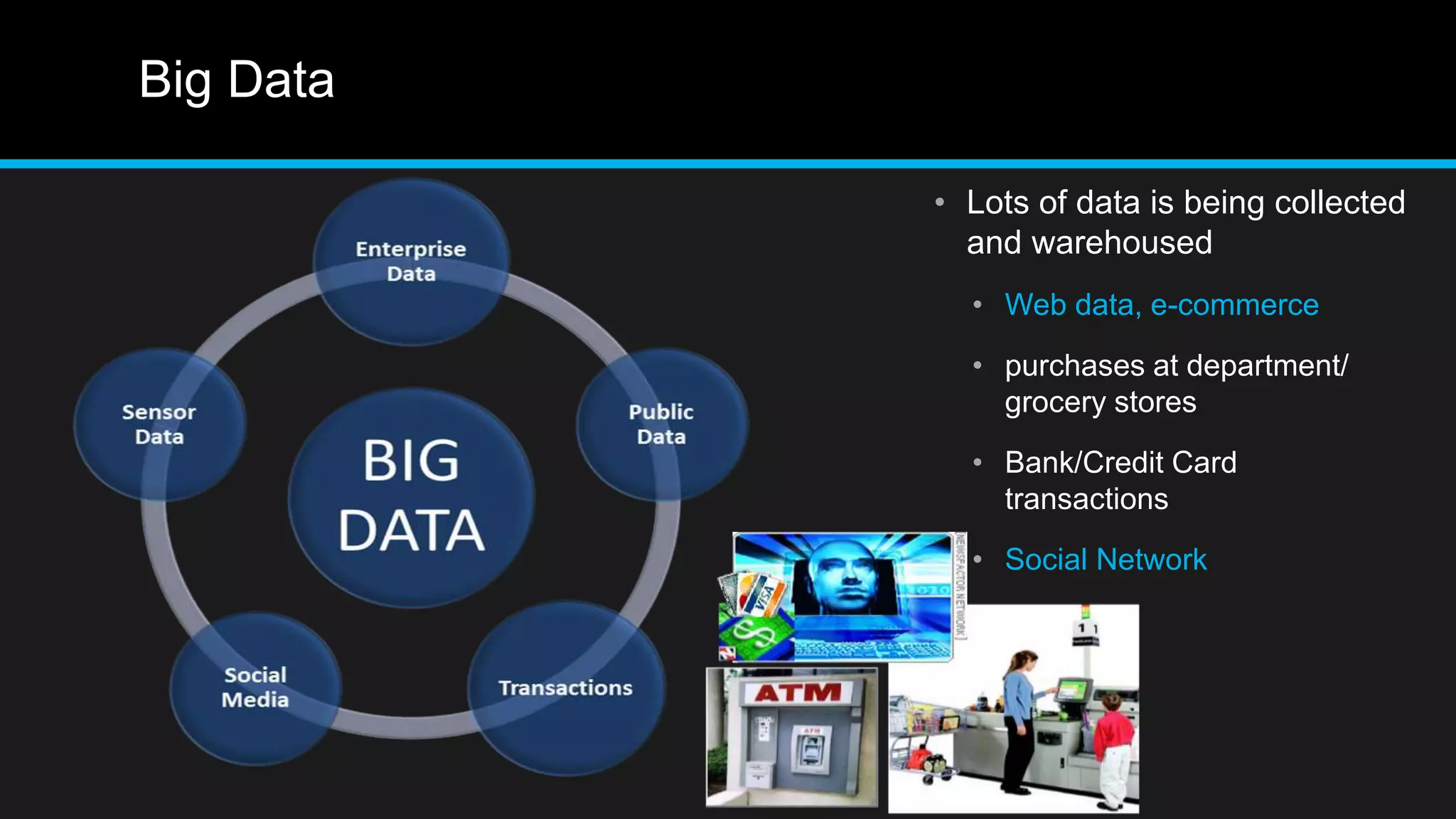


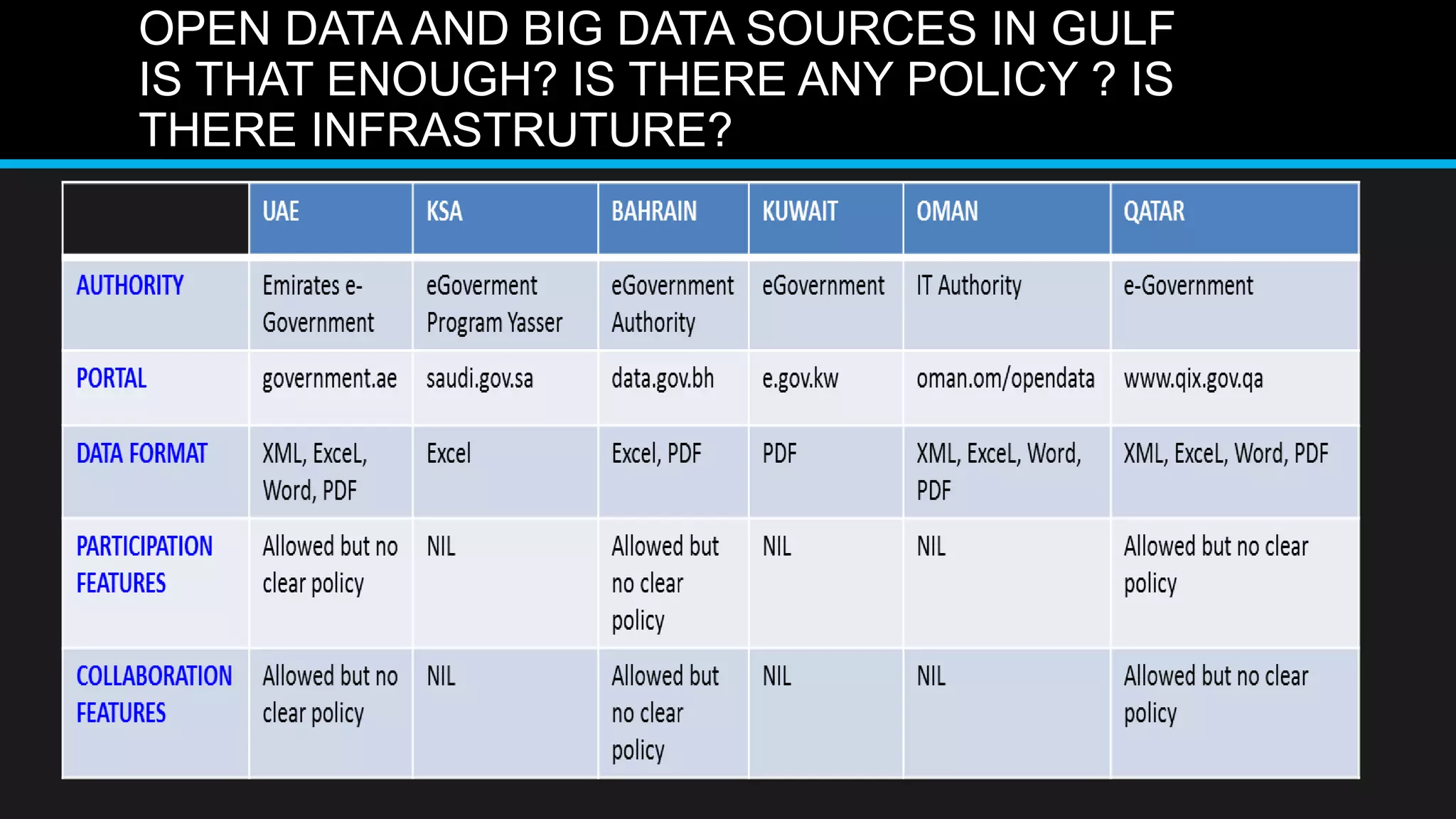
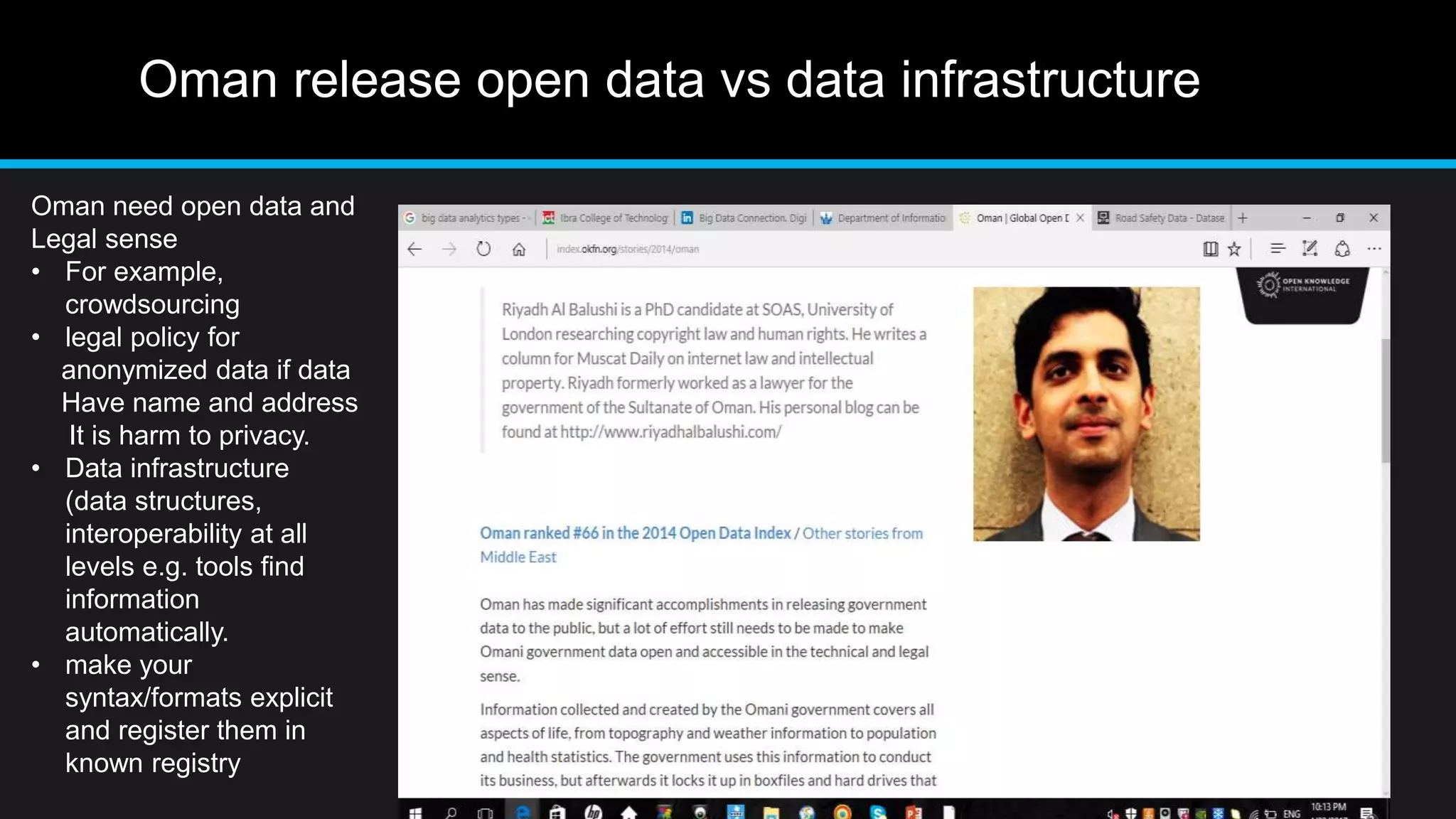


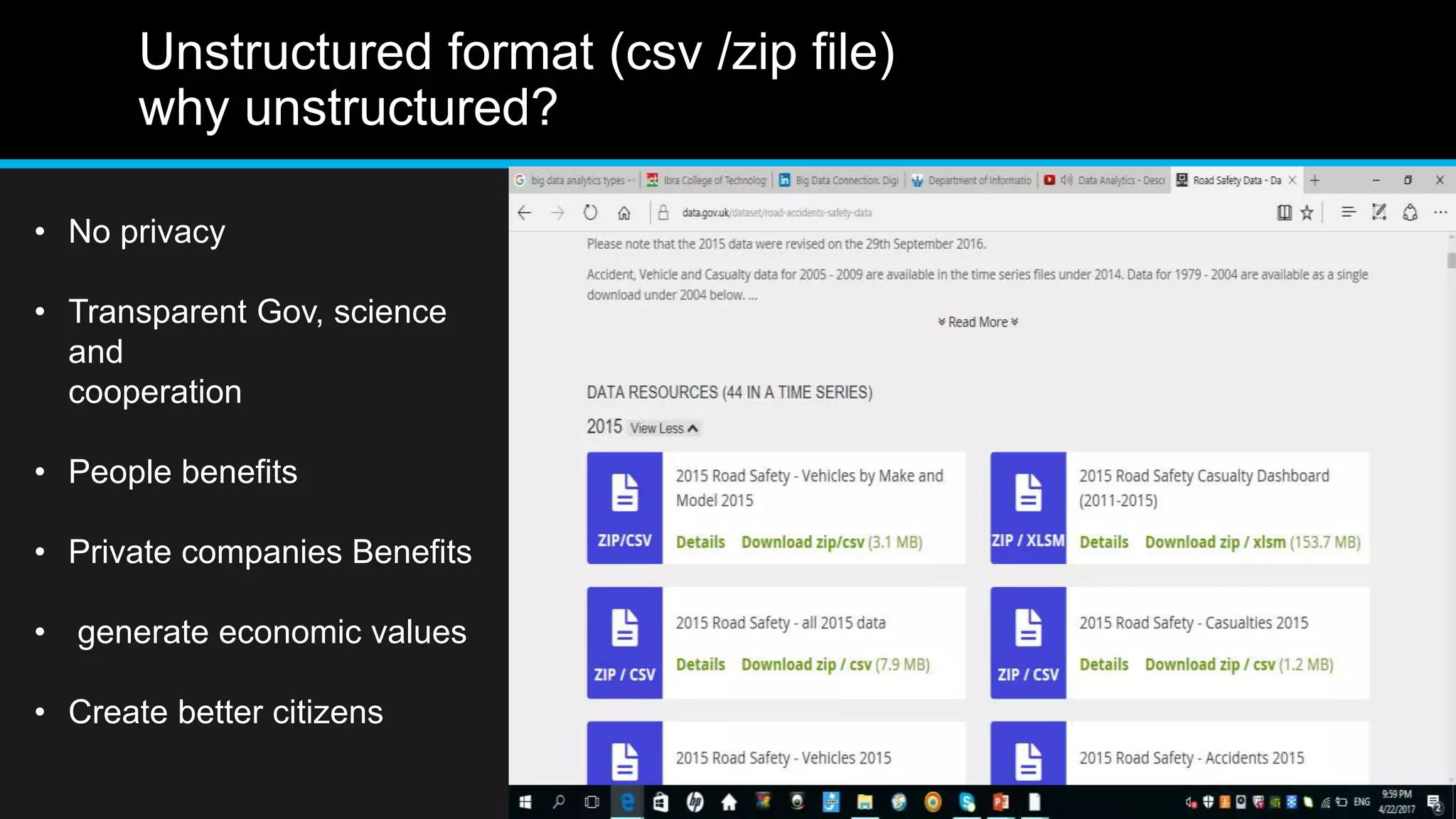
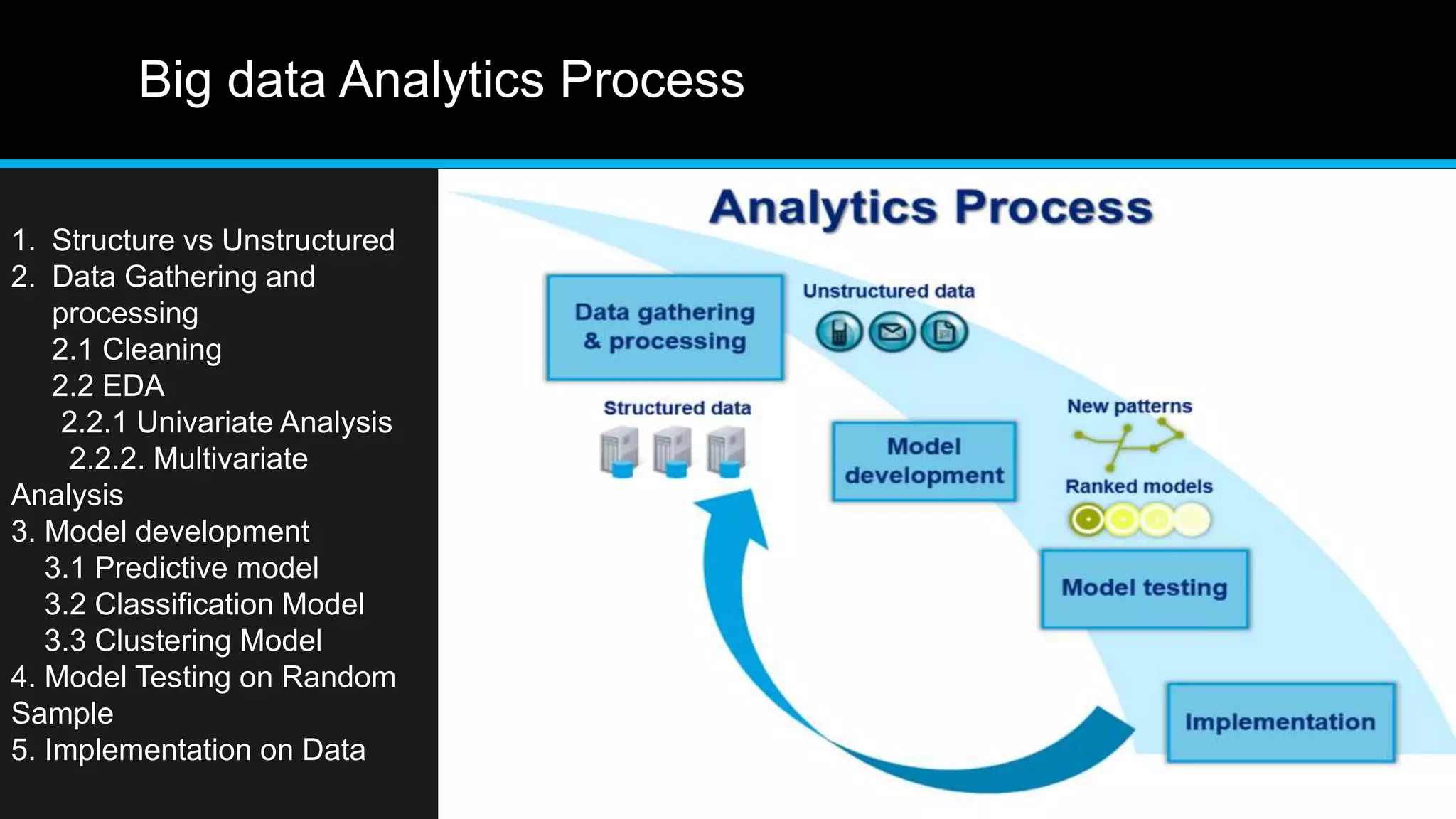
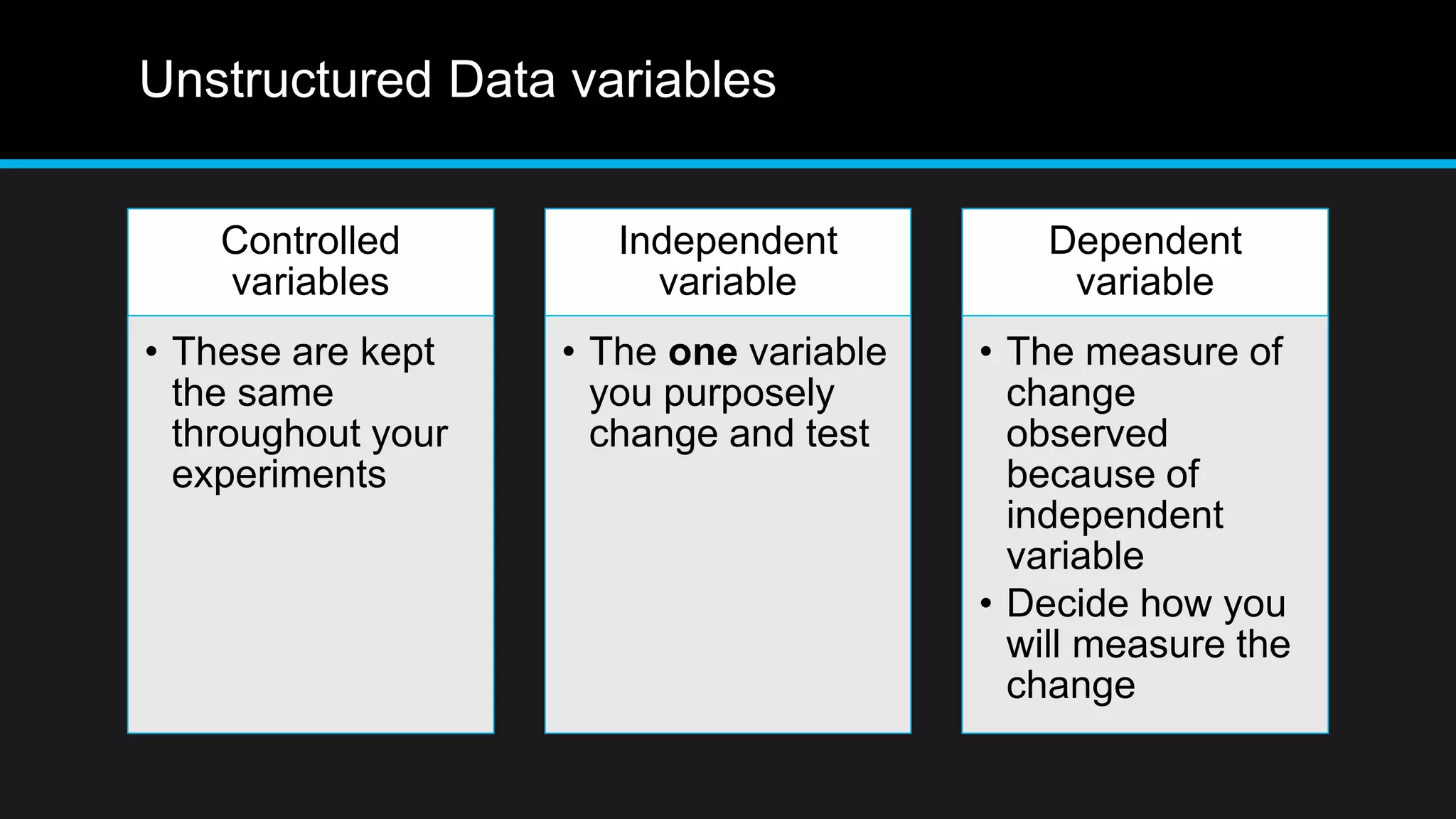


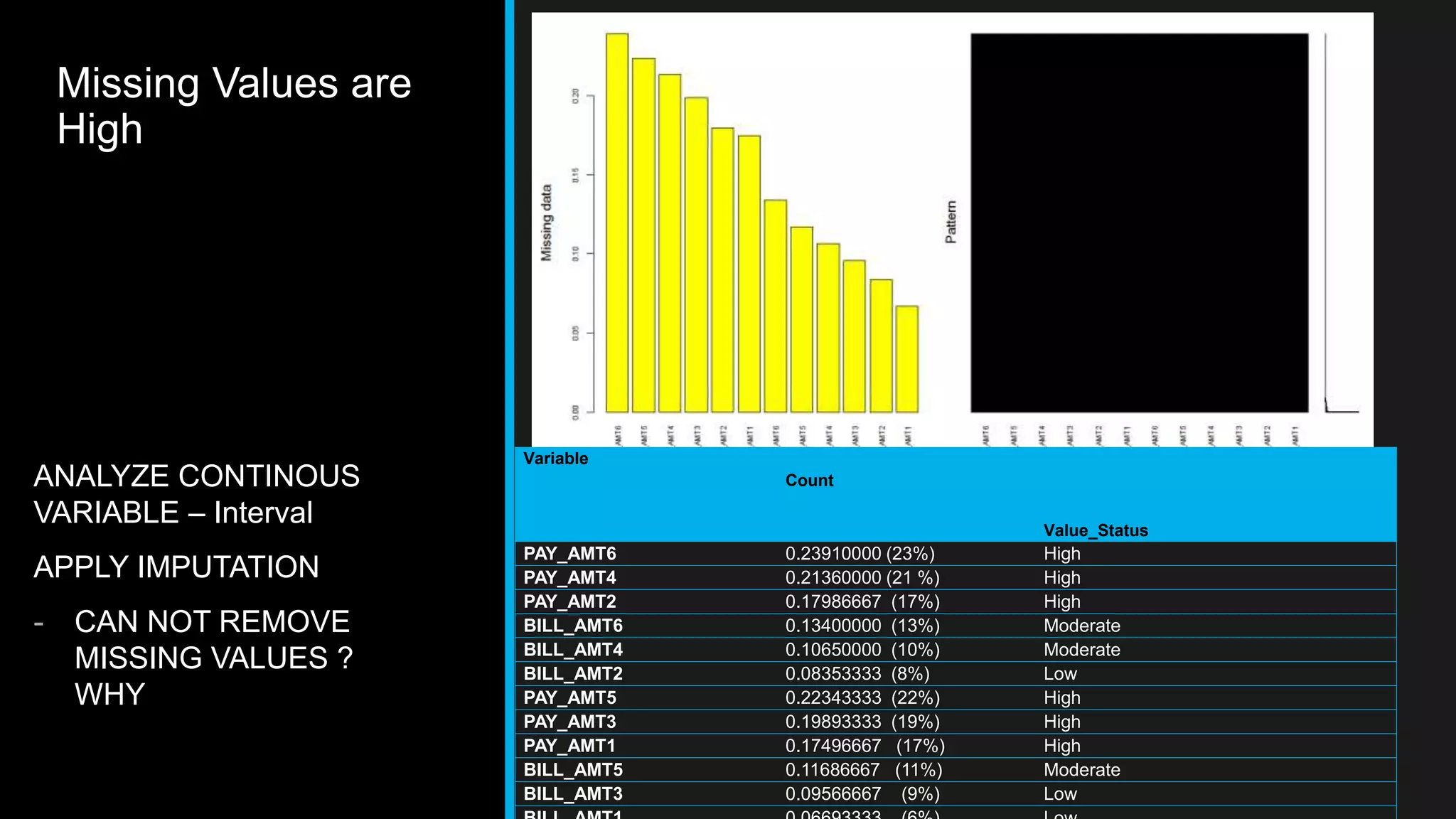
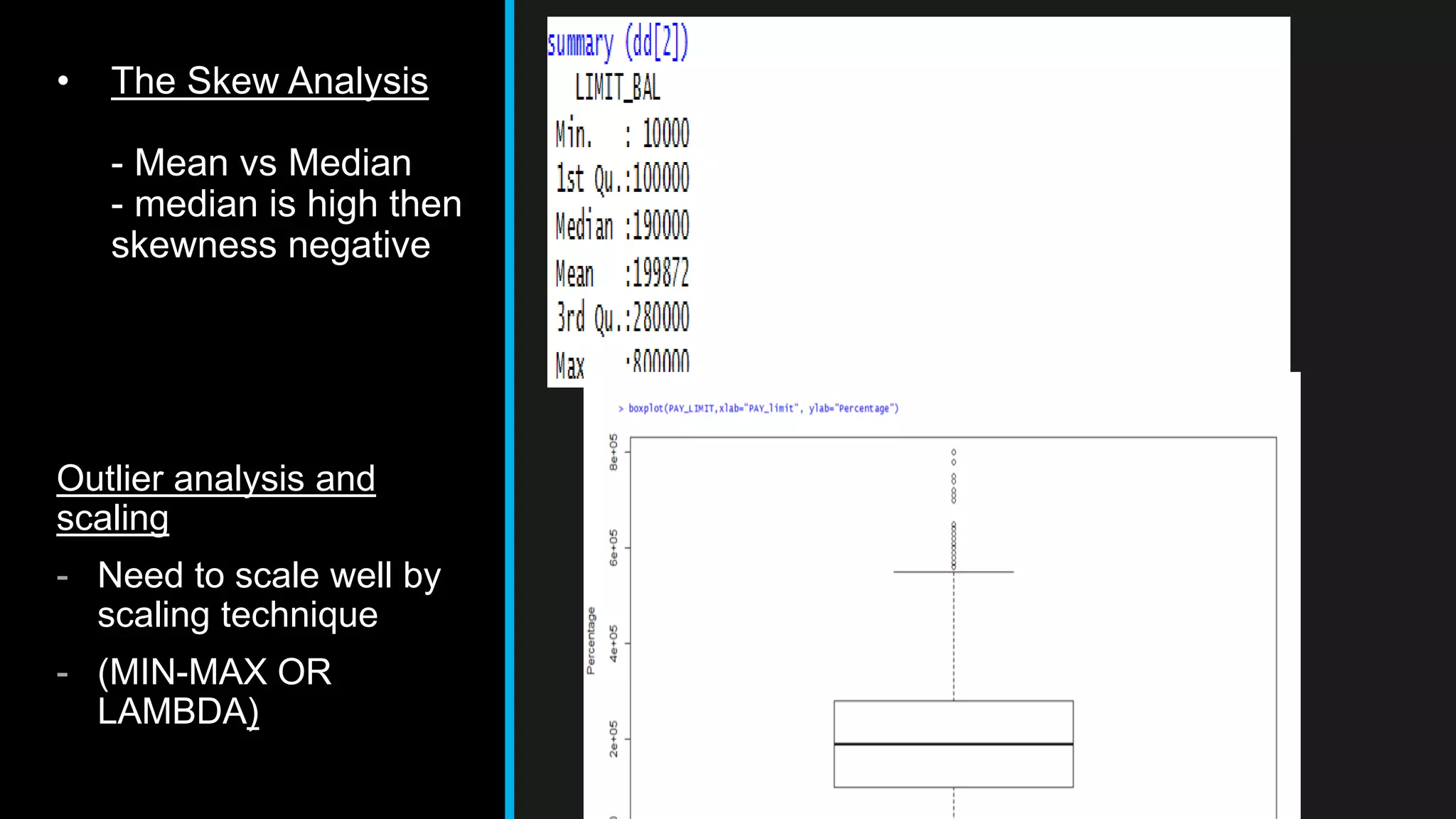
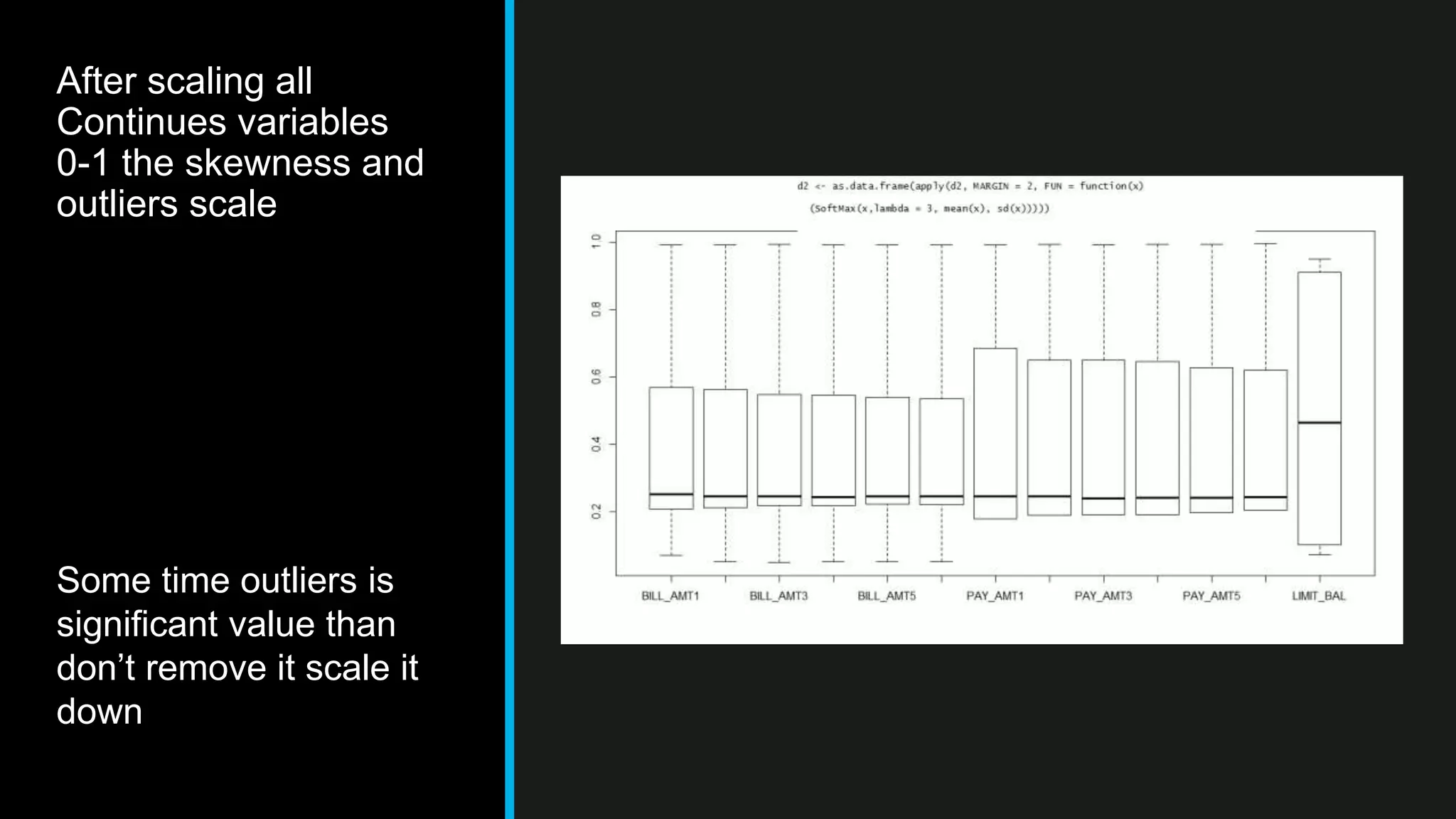

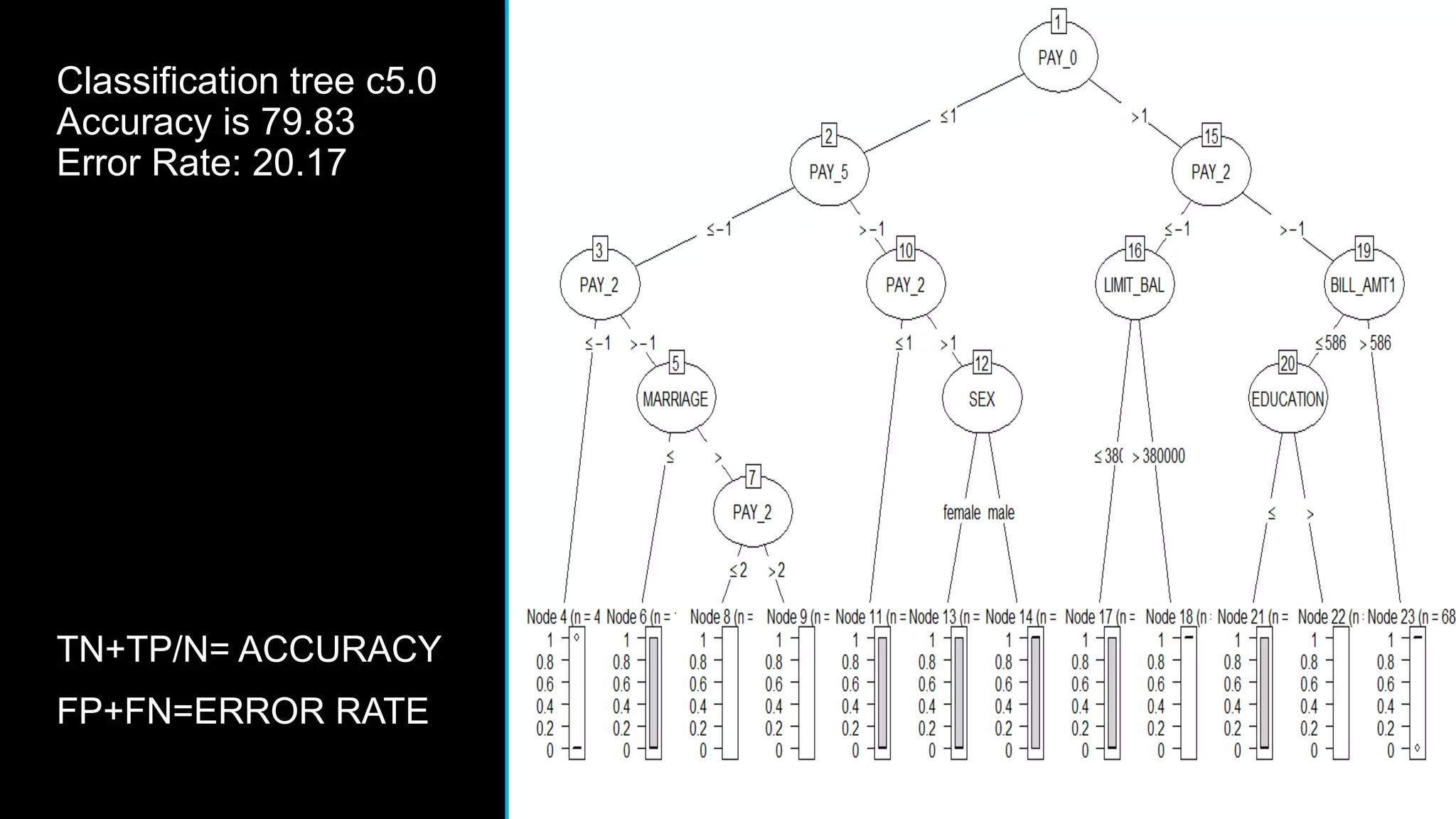



This document discusses big data analytics, including its definition, challenges, and applications, particularly in the context of Oman and open data. It emphasizes the importance of crowdsourcing for understanding customer insights and highlights case studies, such as sentiment analysis related to IKEA and Amazon. Additionally, it outlines the processes for big data analytics, including data gathering and modeling, while stressing the need for data infrastructure and legal policies for effective big data utilization.
















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)





