Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
ryuz88
PPTX, PDF
2,006 views
LUT-Network ~Edge環境でリアルタイムAIの可能性を探る~
夏のAI EdgeハードウェアMeetup in 福岡 2019/07/10 https://connpass.com/event/136350/
Data & Analytics
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 21 times
1
/ 62
2
/ 62
Most read
3
/ 62
4
/ 62
5
/ 62
6
/ 62
7
/ 62
8
/ 62
9
/ 62
10
/ 62
11
/ 62
12
/ 62
13
/ 62
14
/ 62
15
/ 62
16
/ 62
17
/ 62
18
/ 62
19
/ 62
20
/ 62
21
/ 62
Most read
22
/ 62
23
/ 62
24
/ 62
25
/ 62
26
/ 62
27
/ 62
28
/ 62
29
/ 62
30
/ 62
31
/ 62
32
/ 62
33
/ 62
34
/ 62
35
/ 62
36
/ 62
37
/ 62
38
/ 62
39
/ 62
40
/ 62
41
/ 62
42
/ 62
Most read
43
/ 62
44
/ 62
45
/ 62
46
/ 62
47
/ 62
48
/ 62
49
/ 62
50
/ 62
51
/ 62
52
/ 62
53
/ 62
54
/ 62
55
/ 62
56
/ 62
57
/ 62
58
/ 62
59
/ 62
60
/ 62
61
/ 62
62
/ 62
More Related Content
PDF
こわくない Git
by
Kota Saito
PPTX
位置データもPythonで!!!
by
hide ogawa
PPTX
【Unity道場スペシャル 2017大阪】クォータニオン完全マスター
by
Unity Technologies Japan K.K.
PPTX
【Unity道場スペシャル 2017博多】クォータニオン完全マスター
by
Unity Technologies Japan K.K.
PDF
SAT/SMTソルバの仕組み
by
Masahiro Sakai
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
SpectreBustersあるいはLinuxにおけるSpectre対策
by
Masami Hiramatsu
PPTX
Effective Modern C++ 勉強会 Item 22
by
Keisuke Fukuda
こわくない Git
by
Kota Saito
位置データもPythonで!!!
by
hide ogawa
【Unity道場スペシャル 2017大阪】クォータニオン完全マスター
by
Unity Technologies Japan K.K.
【Unity道場スペシャル 2017博多】クォータニオン完全マスター
by
Unity Technologies Japan K.K.
SAT/SMTソルバの仕組み
by
Masahiro Sakai
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
SpectreBustersあるいはLinuxにおけるSpectre対策
by
Masami Hiramatsu
Effective Modern C++ 勉強会 Item 22
by
Keisuke Fukuda
What's hot
PDF
いつやるの?Git入門
by
Masakazu Matsushita
PDF
TRICK 2022 Results
by
mametter
PDF
いつやるの?Git入門 v1.1.0
by
Masakazu Matsushita
PPTX
Nreal Lightハンズオン
by
Takashi Yoshinaga
PDF
【CEDEC2018】CPUを使い切れ! Entity Component System(通称ECS) が切り開く新しいプログラミング
by
Unity Technologies Japan K.K.
PDF
あなたはPO?PM?PdM?PjM?
by
大貴 蜂須賀
PDF
x86とコンテキストスイッチ
by
Masami Ichikawa
PPTX
A-Frameで始めるWebXRとハンドトラッキング (HoloLens2/Oculus Quest対応)
by
Takashi Yoshinaga
PDF
例外設計における大罪
by
Takuto Wada
PPTX
DXとかDevOpsとかのなんかいい感じのやつ 富士通TechLive
by
Tokoroten Nakayama
PDF
Yahoo! JAPANのデータパイプラインで起きた障害とチューニング - Apache Kafka Meetup Japan #5 -
by
Yahoo!デベロッパーネットワーク
PDF
楽天トラベルとSpring(Spring Day 2016)
by
Rakuten Group, Inc.
PDF
Dockerfileを改善するためのBest Practice 2019年版
by
Masahito Zembutsu
PDF
実践イカパケット解析
by
Yuki Mizuno
PDF
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
PDF
組み込みLinuxでのGolangのススメ
by
Tetsuyuki Kobayashi
PDF
【Unite 2018 Tokyo】60fpsのその先へ!スマホの物量限界に挑んだSTG「アカとブルー」の開発設計
by
UnityTechnologiesJapan002
PPTX
Openconfigを用いたネットワーク機器操作
by
Hirofumi Ichihara
PDF
【Unite Tokyo 2019】大量のアセットも怖くない!~HTTP/2による高速な通信の実装例~
by
UnityTechnologiesJapan002
PDF
組み込みでこそC++を使う10の理由
by
kikairoya
いつやるの?Git入門
by
Masakazu Matsushita
TRICK 2022 Results
by
mametter
いつやるの?Git入門 v1.1.0
by
Masakazu Matsushita
Nreal Lightハンズオン
by
Takashi Yoshinaga
【CEDEC2018】CPUを使い切れ! Entity Component System(通称ECS) が切り開く新しいプログラミング
by
Unity Technologies Japan K.K.
あなたはPO?PM?PdM?PjM?
by
大貴 蜂須賀
x86とコンテキストスイッチ
by
Masami Ichikawa
A-Frameで始めるWebXRとハンドトラッキング (HoloLens2/Oculus Quest対応)
by
Takashi Yoshinaga
例外設計における大罪
by
Takuto Wada
DXとかDevOpsとかのなんかいい感じのやつ 富士通TechLive
by
Tokoroten Nakayama
Yahoo! JAPANのデータパイプラインで起きた障害とチューニング - Apache Kafka Meetup Japan #5 -
by
Yahoo!デベロッパーネットワーク
楽天トラベルとSpring(Spring Day 2016)
by
Rakuten Group, Inc.
Dockerfileを改善するためのBest Practice 2019年版
by
Masahito Zembutsu
実践イカパケット解析
by
Yuki Mizuno
GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]
by
Kohei KaiGai
組み込みLinuxでのGolangのススメ
by
Tetsuyuki Kobayashi
【Unite 2018 Tokyo】60fpsのその先へ!スマホの物量限界に挑んだSTG「アカとブルー」の開発設計
by
UnityTechnologiesJapan002
Openconfigを用いたネットワーク機器操作
by
Hirofumi Ichihara
【Unite Tokyo 2019】大量のアセットも怖くない!~HTTP/2による高速な通信の実装例~
by
UnityTechnologiesJapan002
組み込みでこそC++を使う10の理由
by
kikairoya
Similar to LUT-Network ~Edge環境でリアルタイムAIの可能性を探る~
PPTX
深層学習の数理
by
Taiji Suzuki
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
PPTX
LUT-Network ~本物のリアルタイムコンピューティングを目指して~
by
ryuz88
PDF
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
PDF
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
PDF
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
深層学習入門
by
Danushka Bollegala
PDF
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
PPTX
Efficient Deep Reinforcement Learning with Imitative Expert Priors for Autono...
by
harmonylab
PPTX
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
PPTX
LUT-Network Revision2
by
ryuz88
PDF
Deep learning入門
by
magoroku Yamamoto
PPTX
令和元年度 実践セミナー - Deep Learning 概論 -
by
Yutaka KATAYAMA
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
PDF
Deep Learningの基礎と応用
by
Seiya Tokui
PDF
MANABIYA Machine Learning Hands-On
by
陽平 山口
PDF
機械学習工学と機械学習応用システムの開発@SmartSEセミナー(2021/3/30)
by
Nobukazu Yoshioka
深層学習の数理
by
Taiji Suzuki
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
LUT-Network ~本物のリアルタイムコンピューティングを目指して~
by
ryuz88
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化
by
marsee101
東大大学院 電子情報学特論講義資料「深層学習概論と理論解析の課題」大野健太
by
Preferred Networks
DEEP LEARNING、トレーニング・インファレンスのGPUによる高速化
by
RCCSRENKEI
Deep Learningの技術と未来
by
Seiya Tokui
深層学習入門
by
Danushka Bollegala
深層学習(岡本孝之 著) - Deep Learning chap.1 and 2
by
Masayoshi Kondo
Efficient Deep Reinforcement Learning with Imitative Expert Priors for Autono...
by
harmonylab
Image net classification with Deep Convolutional Neural Networks
by
Shingo Horiuchi
LUT-Network Revision2
by
ryuz88
Deep learning入門
by
magoroku Yamamoto
令和元年度 実践セミナー - Deep Learning 概論 -
by
Yutaka KATAYAMA
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
Deep Learningの基礎と応用
by
Seiya Tokui
MANABIYA Machine Learning Hands-On
by
陽平 山口
機械学習工学と機械学習応用システムの開発@SmartSEセミナー(2021/3/30)
by
Nobukazu Yoshioka
More from ryuz88
PDF
Fast and Light-weight Binarized Neural Network Implemented in an FPGA using L...
by
ryuz88
PPTX
LUT-Network その後の話(2022/05/07)
by
ryuz88
PDF
Rust で RTOS を考える
by
ryuz88
PPTX
Verilator勉強会 2021/05/29
by
ryuz88
PPTX
LUT-Network Revision2 -English version-
by
ryuz88
PPTX
FPGA勉強会資料 20210516
by
ryuz88
PPTX
Deep Learning development flow
by
ryuz88
Fast and Light-weight Binarized Neural Network Implemented in an FPGA using L...
by
ryuz88
LUT-Network その後の話(2022/05/07)
by
ryuz88
Rust で RTOS を考える
by
ryuz88
Verilator勉強会 2021/05/29
by
ryuz88
LUT-Network Revision2 -English version-
by
ryuz88
FPGA勉強会資料 20210516
by
ryuz88
Deep Learning development flow
by
ryuz88
LUT-Network ~Edge環境でリアルタイムAIの可能性を探る~
1.
LUT-Network ~EDGE環境でリアルタイムAIの可能性を探る~ 夏のAI EDGEハードウェアMEETUP IN
福岡 2019/07/10 Ryuji Fuchikami 渕上 竜司
2.
自己紹介 • 基本的にサンデープログラマ(平日はサラリーマンやってる2児の父親) • 1976年生まれ
全国転々としつつも結局、福岡が一番長く、今も福岡在住 • 1998~ μITRON仕様 Real-Time OS HOS-80 をリリース • 現在 HOS-V4a にて各種組み込みCPUに対応 (ARM,H8,SH,MIPS,x86,Z80,AM,V850,MicroBlaze, etc.) • 2008~ FPGA用ソフトコアSoC環境 Jelly をリリース(MIPS互換コア) • 現在 Zynq 上にて Real-Time GPU や LUT-Network の実験など 各種 Real-Time コア開発の実験場と化す • 2018~ LUT-Network用の環境 BinaryBrain を開発中 • 本日のお題 • リアルタイムコンピューティング(当然Edgeコンピュータ)が大好き • 電脳メガネ計画(いつかやりたい電脳コイルの世界) • Real-Time 画像I/O (カメラ[IMX219] & OLED 1000fps駆動) • Real-Time GPU開発 (frame buffer無し、ゼロ遅延描画) • Real-Time DNN開発 (超低遅延DNN認識) 2
3.
LUT-Network とは? FPGAのLUTで作っ た Binary-DNN (バイナリ・ディープ・ニューラル・ネットワーク) 3
4.
4 本題に入る前に
5.
FPGAでEdge-AIが出来ると 何が嬉しいのか? 5
6.
FPGAのメリット その1 6 デバイスのバリエーション豊富 Digi-Keyで価格ソートしたところ1チップ 130円~895万円まで存在 一番安いFPGAからLUT-Networkは適用可能!
7.
FPGAのメリット その2 7 低消費電力/低コスト CPU/GPUは高クロックで浮動小数点演算できる専用回路を多数持っている これらが有効利用できるアルゴリズム以外は、無駄なトランジスタに電力とコストを食われる ディープラーニングにそこまで高度な演算器は不要なのに気がつき始めて、各社FP16と かINT8とかINT4 とかINT1とかやり始めた でも従来アプリも動かさないといけないので、やれることに限界がある ディープラーニング専用LSIを作るにもボリュームゾーンしか狙えないし、Edge向けI/Oが弱い FPGA有利な領域が多数生まれる FPGA有利な領域内でのNo.1
効率を狙っているのが LUT-Network
8.
FPGAのメリット その3 8 FPGA センサー1 アクチュエータ1 センサー2 センサー3 センサーN アクチュエータ2 アクチュエータ3 アクチュエータ4 通信 PROM 自己書き換え 一般的なSoCに備えられるI/Fの個数や種類を超えて様々なデバイスが接続可能 その気になればクラウドから回路情報のPROMを書き換えも可能 (SOTA/FOTAならぬ
Bitstream Over The Airか?) I/Oの拡張が極めて容易。何でも何個でもつながる マルチモーダル・インターフェース向け、そして Field Programmable AIが無いと活かせないような特殊センサーも自在に活用できる
9.
リアルタイム性の高い演算が容易(私がFPGAやる理由) メモリ プロセッサ入力装置 出力装置 間に合わなければコマ落ち(fps低下) 一度メモリに入らないと演算できない 命令フロー型のプログラミング(ノイマン型) データフロー型のプログラミング メモリ プロセッサ入力装置 出力装置 ・入出力装置と直結できる ・入力から出力までの遅延が小さい ・定時性のある演算が可能 9 FPGAのメリット
その4 FPGAはどちらも出来る。もちろんLUT-Networkも両方適用可能!
10.
技術的な話の前に LUT-Network の簡単な紹介 10
11.
LUT-Network のコンセプト • 通常のDNN 1.
パーセプトロンを配置して結線を定義 2. 学習を実施 3. パーセプトロンの重み係数が得られる • LUT-Network 1. LUT素子を配置して結線を定義 2. 学習を実施 3. 各LUTのテーブルが得られる θ x1 x2 x3 xn ・・・ w1 w2 w3 wn y 11
12.
Network Design Learning (e.g. Tensor
Flow) Convert to C++ network parameter C++ source code High Level Synthesis (e.g. Vivado HLS) RTL(behavior) Synthesis (e.g. Vivado) Complete (many LUTs, 100~200MHz) Network Circuit Design network (FPGA Circuit) Learning (BinaryBrain) RTL(net-list) Complete (few LUTs, 300~400MHz) Synthesis (e.g. Vivado) LUT Networkのデザインフロー 【従来】 【LUT-Network】 12 パーセプトロンモデルを合成 そのまま学習するだけ
13.
手書き数字(MNIST)認識の実験事例紹介 13 xc7z020clg400-1 こんな微小リソース量で 認識が1ミリ秒の遅延でできてます MNISTコア単体性能 CNN時318,877fps カメラも含めたシステム動作1000fps
14.
今実験できていること 14 分類器(Classification) MNIST 手書き文字 認識率 99% CIFAR-10 一般物体10種 認識率60% Auto Encoder
Regression 特徴化とそこからの画像生成 重回帰分析のフィッティング
15.
それでは LUT-Networkの技術的な話 15
16.
LUT素子をパーセプトロン素子の代替におくので •バイナリネットワークであり、 •疎結合ネットワークとなる 16
17.
•パーセプトロン(Frank Rosenblatt 1958年発表)は 単独でXORを学習できない(Marvin
MinskyとSeymour Papert がPerceptronsという書籍で1969年に指摘) 17 LUTならできる!
18.
LUTの学習方法 • LUTテーブルの学習方法 • 直接学習(力技での学習実験) •
Micro-MLPによるバイナリ値で学習する方法 (2018/02/02 fpgaxで発表) • Stochastic-LUTによる確率値で学習する方法 [New!] • Stochastic-LUTモデルを Micro-MLP的に使ってバイナリ値で学習する方法 [New!] • バイナリ学習の底上げ • バイナリ変調を行う方法 [Update] • 番外(新モデルの非バイナリ応用) • Stochastic-LUTモデルをStochasticガン無視で、浮動小数点の学習として、パーセプト ロンの変わりに使う方法 [New!] 18 まだまだ試行錯誤中ですが、いろいろな知見が得られてきました
19.
[直接学習] 学習方法 入力値 発生回数
0出力時の損失 1出力時の損失 0 37932 47813.7 48233.9 1 39482 50001.3 49692.9 2 37028 44698.9 44845.7 3 40640 49257.1 49331.0 4 27156 33998.4 33891.0 5 23930 29538.6 29495.2 6 29002 35197.3 35451.4 7 27786 33390.9 33466.9 8 43532 52741.1 52993.5 9 41628 49985.9 50388.5 10 49176 56521.4 56026.1 11 46542 54215.4 54284.9 ・・・・ ・・・・ ・・・・ ・・・・ 59 34268 41152.9 41215.8 60 22872 28852.4 29000.0 61 17930 22068.9 22112.9 62 24156 28213.2 28227.1 63 24194 28367.0 28450.4 新しいテーブル値 0 1 0 0 1 1 0 0 0 0 1 0 ・・・・ 0 0 0 0 0 1. LUTテーブルを一旦乱数で埋める 2. ある1個のLUTの出力を0と1それぞれに固定して学習データ全部流す 3. LUTの入力値毎に損失関数の総和を取っておき、損失が減る方向にテーブルを更 新 19
20.
[直接学習] MNISTの学習実験 0.6 0.65 0.7 0.75 0.8 0.85 1 2
3 4 5 6 7 8 9 10 11 12 13 14 15 16 MNIST学習実験 学習データ(6万個) 評価データ(1万個) 小規模実験ではあるが、学習に用いたデータでの認識率とほぼ対応する 形で、評価用のデータセットでも認識率の向上が見られた。 層構成:360-180-30 の570個のLUTを利用 結線 :全層ともランダム結線 20 思いの外、過学習的な挙動を示さない
21.
yxwvu tsrqp onmlk jihgf edcba 000 000 000 000 000 wv ts ok gf db Dense-Affine (Fully Connection) Sparse-Affine
(最初のアイデア) ・ ・ ・ synthesis LUT LUT LUT LUT LUT LUT LUTmapping BatchNormalization Binary-Activation BatchNormalization Binary-Activation Deep Logic (Low-speed and Middle Performance) 同じくXORはだめ でも高速(300MHz~400MHz) 1層ではXORは学習できない 100MHz~200MHz micro-MLPを束ねた層 LUTmapping BatchNormalization Binary-Activation 1層でXORも学習できる 高速(300MHz~400MHz) ・ ・ ・ Simple Logic (High-speed and Low Performance) Simple Logic (High-speed and High Performance) BNもLUT内に含める 隠れ層もLUT内に含める この単位を micro-MLP として定義 [誤差逆伝播] Micro-MLPのアイデア 21
22.
[誤差逆伝播] バイナリ活性層 (binary
activation layer) • forward • Sign() • 𝑦 = 1 𝑖𝑓 𝑥 ≥ 0, 0 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒, • 符号見るだけ • backward • hard-tanh() • 𝑔 𝑥 = 1 𝑥 ≤1 • 小さい値の時のみ伝播 Binary Connect の方法をそのまま拝借(先人の知恵に感謝) 重みは実数なので Batch Normalization はオリジナルの実数版を使う 22 BatchNormalization Binary-Activation ・ ・ ・
23.
[誤差逆伝播] micro-MLP の学習 Affine
Layer (16~64 perceptron) Activation Layer Sigmoid or ReLU ・・・・ ・・・・ Affine Layer (1 perceptron) Batch Normalization Activation Layer Binarize 6 signals input (0.0 or 1.0) 【Learning (FP32) [CPU/GPU]】 1 signal output (0.0 or 1.0) ×16~64 (FP32) ×1 (FP32) 【Prediction (Binary) [FPGA)]】 LUT (64bit Look-up Table) 6 signals input (H or L) 1 signal output (H or L) Affine Layer (16~64 perceptron) Activation Layer Sigmoid or ReLU ・・・・ ・・・・ Affine Layer (1 perceptron) Batch Normalization Activation Layer hard-tanh 1 gradient input (FP32) 6 gradients output (FP32) <Forward> <Backward> <Forward> logic synthesis × 16~64 (FP32) ×1 (FP32) ×6 (Binary) ×1 (Binary) ×1 (FP32) ×1 (FP32) ×6 (FP32) ×16~64 (FP32) × 16~64 (FP32) ×1 (FP32) 23
24.
中間層の個数を変えて、直接学習と比較 LUT数570個小さなMLPにおける直接学習と誤差逆伝播法の比較 適用可能な範囲においては直接学習は優秀 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 2 3
4 5 6 7 8 9 10 11 12 13 14 15 16 17 学習方式比較 (360-180-30 MLPでのMNIST) 直接学習 SparseAffine μMLP<4> μMLP<8> μMLP<16> μMLP<32> μMLP<64> 24
25.
ここで次の学習方法に行く前に バイナリ変調の話 25
26.
オーバーサンプリングによるバイナリ変調モデル • オーバーサンプリングと量子化による変調 • PWM(Pulse
Width Modulation)変調 • 1bitADC(⊿Σ変調), ディザ, etc. • 変調を行うことで値に応じて確率的に1/0が現れる信号列に変換される • 計算はバイナリだが、LPFでノイズは取り除かれ階調が回復する • 階調が回復するので回帰分析など多値へのフィッティングアプリケーションにも応用できる • 例えば高速度カメラの映像などノイズを含む画像は そのまま量子化すれば元々確率的に1/0が現れる 変調 バイナリDNN ノイズや 局部発振器 LPF 26 人間で代替も可能 (人の感覚自体がLPFとしても機能する)
27.
バイナリ変調の例 • 最も簡単なPWM変調は三角波と比較するだけ 27
28.
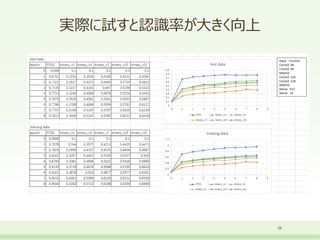
実際に試すと認識率が大きく向上 28
29.
空間方向の拡張で効果が飽和しても変調は効果あり 29
30.
という前提の元、ここから急に Stochastic演算の話 30
31.
Stochastic演算とは 31 1110111101 0100111010 0100111000 1の出現率0.8 1の出現率0.5 0.8×05 = 0.4 お互いに相関無く確率的にのみ1/0が現れるデータであれば、 ANDゲート1個で出現確率の乗算が出来る 1の出現率0.4 バイナリ変調済みデータ列はゲート一個で乗算できる可能性がある
32.
[新アイデア] Stochastic-LUTモデル 32 - * - x0 x1 * W0 binarize * * W1 * * W2 * * W3 1 1 + y 2入力LUTの例
x0-x1 を入力する確率変数. W0-W3 をテーブル値とする W0 が参照される確率 : (1 - x1) * (1 - x0) W1 が参照される確率 : (1 - x1) * x0 W2 が参照される確率 : x1 * (1 - x0) W3 が参照される確率 : x1 * x0 y = W0 * (1 - x1) * (1 - x0) + W1 * (1 - x1) * x0 + W2 * x1 * (1 - x0) + W3 * x1 * x0 値をすべて観測時に0と1のどちらかの値に決まる確率変数として確率値をFP32で扱います。 この計算グラフは微分可能であるため、誤差逆伝播が可能です。 6入力LUTのグラフは図示すると巨大になるので作成していませんが、同様に作成可能です。 確率的LUTモデルを用いることで、一度に非常に多くのバイナリ値を計算したのと同じ効果が得られるた め、micro-MLPよりも高速/高精度な結果が得られます。W値はそのままLUT化できます。 これだけでLUTを完全モデル化 Batch-Normalization不要 Activationも不要
33.
確率的LUTモデルの内部のパラメータ 33 input[n-1:0] output LUTテーブルは入力数nに対してn次元を持ち、その中で連続体として振舞いま す。 上記は2入力LUTにXORを学習させた場合の模式図です。 内部の状態テーブルを参照する形式を取るために、パーセプトロン素子と違って 内部テーブルがXOR形状に学習することも可能です
34.
34 確率的LUTモデルでのMNISTの学習 MNIST程度であれば割りと問題なく 機能する模様 計算後バイナリ化するとほぼ同じス コアを出す → 学習計算が超高速! ただし、CIFAR-10レベルでは単純に バイナリ化すると性能が出ない 間にランダムシャッフルを入れると 回復するので、相関の問題と思われ る。 確率値で計算 結果を変調バイナリで実際に計算
35.
35 現状もっとも性能の出ている汎用学習方法 Micro-MLPの代わりにStochastic-LUT素子を入れてバイナリを学習 学習時間はMicro-MLPよりマシだが元通りに…. ただし認識精度はとてもよくなった (実験してないけど、直接学習並みじゃないかな) BatchNormalization Binary-Activation Stochastic-LUT この素子は名前はまだ無い 渕上素子とでも呼べばいいのか? (草薙さんが発明すべきだろ) CIFAR-10 で 60%達成できました
(^^)
36.
疎結合の方の話は どこにいった? 36
37.
疎結合で層数は増えるが、計算量は同じオーダー 37 従来のパーセプトロン 演算量 O(n) 今回作ったモデル 演算量 O(n) n/2
+ 4/n + n/8 + ・・・・ < n フルに繋いでも演算量のオーダーは変わらない n対mで繋ぐ場合、後者の方が繋ぎ方の工夫がいろいろ出来て面白い 入力数 n の場合の演算量のオーダー
38.
まとめに入ります 38
39.
LUT-Networkの特徴まとめ • 基本的にはエッジでの推論を効率化する技術 • 学習時はGPU使います •
バイナリ・ニューラル・ネットワークの一種である • BDNNで可能なものは(原理的には)学習可能(な筈) • LUT単位の学習なので高密度&高速(300~400MHz) • ネットワーク定義時に回路規模が決まる • FPGA内のリソースを決めてから、その範囲での最大の認識率が探れる • つまりリアルタイム保証を先に行える 通常DNNのFPGA適用 LUT Network 認識率 学習時に決定 出来高払い (ベストエフォート) 性能 合成結果で出来高払い (ベストエフォート) 学習に先立って決定 39
40.
学習用OSSの紹介(BinaryBrain) • 今回の実験の為に開発した環境(C++ &
Eigen) • githubにて公開中 • https://github.com/ryuz/BinaryBrain • 特徴 • TensorFlowもChainerもTorchもCaffeも知らずノリで書いた(笑) • 参考書は「ゼロから作るDeep Learning」のみ • RTL(Verilog)を出力できる[今のところ Xilinxしか試してないですが] • NCHWでもNHWCでもないCHWNメモリ配置 → 1bitデータをメモリにパッキングしたままSIMD演算 • CUDA対応、FMA2命令とかも活用 • 普通のDNNもシンプルなCNN程度なら学習可能 (条件を揃えてベンチマークがしたい) Ver.1(直接学習の実験)→ Ver.2(micro-MLPでの逆伝播の実験) → Ver.3を開発中(GPU対応/Stochasticモデル) 40
41.
ご静聴ありがとうございました 41
42.
発表者アクセス先 • 渕上 竜司
(Ryuji Fuchikami) • e-mail : ryuji.fuchikami@nifty.com • Web-Site : http://ryuz.my.coocan.jp/ • Blog. : http://ryuz.txt-nifty.com/ • GitHub : https://github.com/ryuz/ • Twitter : https://twitter.com/Ryuz88 • Facebook : https://www.facebook.com/ryuji.fuchikami • YouTube : https://www.youtube.com/user/nekoneko1024 • レスポンス悪いかもしれませんが、お気軽にお問い合わせください m(_ _)m 42 なお、この資料は当方のこの後 Slide Shareでも公開予定です。
43.
43
44.
以下、予備資料 44
45.
Learning Prediction Matrix (行列) Weight (重み) Activation (活性化) Convolution (畳み込み層) Deep Network performance of CPUs/GPUs performance
of FPGA Binary Connect Dense (密行列) Binary (2値) Real (実数) OK Binarized Neural Network Dense (密行列) Binary (2値) Binary (2値) OK XNOR- Network Dense (密行列) Binary (2値) Binary (2値) OK LUT- Network Sparse (疎行列) Real (実数) Binary (2値) OK ? (原理的にXNOR-Netより 有利なはず) good(良い) excellent(非常に良い) bad(イマイチ) 1 node → many adders 1 node → many XNOR 1 node → many XNOR 1 node → 1 LUT excellent(非常に良い) 従来の Binary Networkとの比較 45 普通のバイナリネットは Wightの縮小が目的だが、 LUT-NetではここはRealのまま放置!
46.
FPGAとGPUの比較 46 [FPGA] Digi-Key XPS 品番
LUT 円 円/LUT W W/LUT XC7A200T-1FBG484C 134,600 22,662 0.168 XC7A100T-1FTG256C 63,400 12,776 0.202 XC7A75T-1FTG256C 47,200 10,835 0.230 XC7A50T-1FTG256C 32,600 6,224 0.191 XC7A35T-1FTG256C 20,800 4,021 0.193 XC7A25T-1CPG238C 14,600 3,849 0.264 XC7A15T-1FTG256C 10,400 3,268 0.314 XC7A12T-1CPG238C 8,000 3,006 0.376 XC7S6-1CSGA225 3,752 1,720 0.458 4.821 0.0013 [GPU] 価格.com Wiki 品番 CUDA cores 円 円/core TDP W/core RTX 2080Ti 4,352 129,790 29.823 250 0.0574 RTX 2080 2,944 79,800 27.106 215 0.0730 RTX 2070 2,304 53,977 23.428 175 0.0760 RTX 2060 1,920 36,698 19.114 160 0.0833 GTX 1660Ti 1,536 31,980 20.820 120 0.0781 GTX 1660 1,408 25,780 18.310 120 0.0852 GTX 1650 896 16,990 18.962 75 0.0837 GTX 1070Ti 2,432 56,980 23.429 180 0.0740 GTX1060 1,280 21,700 16.953 120 0.0938 GT 1030 384 8,680 22.604 30 0.0781 Jetson Nano 128 12800 100.000 7.5 0.0586 同じことをFPGAとGPUで行った場合、 FPGAだとLUT:20~100個で出来てしまうこと が、CPU/GPUだと数サイクル使ってしまうよ うなケースでFPGAが有利 したがって、低bit数の演算であればFPGAに分 がある。 特にLUT-Networkと同じことをCPU/GPUでや る場合、1個のLUT分の演算で数サイクルを消 費するような関係なので極めて性能差が出る
47.
実例紹介1 [MNIST MLP] (1000fps
動作) DNN (LUT-Net) MIPI-CSI RX Raspberry Pi Camera V2 (Sony IMX219) SERDE S TX PS (Linux) SERDES RX FIN1216 DMA OLED UG-9664HDDAG01 DDR3 SDRA M I2C MIPI-CSI Original Board PCX-Window 1000fps 640x132 1000fps control PL (Jelly) BinaryBrain Ether RTL offline learning (PC) ZYBO Z7-20 debug view 47 動画紹介
48.
MNIST MLP 総LUT: 1182
個 input:784 layer0: 256 layer1: 256 layer2: 128 layer3: 128 layer4: 128 layer5: 128 layer6: 128 layer7: 30 Camera + OLED込みの全体リソース DNN部はLUTのみハードマクロで指定 (ぴったり上記のリソース量) DNN部のみのリソース 250MHz = 250,000,000fps
49.
DNN (LUT-Net) MIPI-CSI RX Raspberry Pi Camera V2 (Sony
IMX219) SERDE S TX PS (Linux) SERDES RX FIN1216 DMA OLED UG-9664HDDAG01 DDR3 SDRA M I2C MIPI-CSI Original Board PCX-Window 1000fps 640x132 1000fps control PL (Jelly) BinaryBrain Ether RTL offline learning (PC) ZYBO Z7-20 debug view OSD (frame-mem) 49 事例紹介2 MNIST CNN (1000fp動作) 動画紹介
50.
MNIST CNN 学習時ログ fitting
start : MnistCnnBin initial test_accuracy : 0.1518 [save] MnistCnnBin_net_1.json [load] MnistCnnBin_net.json fitting start : MnistCnnBin [initial] test_accuracy : 0.6778 train_accuracy : 0.6694 695.31s epoch[ 2] test_accuracy : 0.7661 train_accuracy : 0.7473 1464.13s epoch[ 3] test_accuracy : 0.8042 train_accuracy : 0.7914 2206.67s epoch[ 4] test_accuracy : 0.8445 train_accuracy : 0.8213 2913.12s epoch[ 5] test_accuracy : 0.8511 train_accuracy : 0.8460 3621.61s epoch[ 6] test_accuracy : 0.8755 train_accuracy : 0.8616 4325.83s epoch[ 7] test_accuracy : 0.8713 train_accuracy : 0.8730 5022.86s epoch[ 8] test_accuracy : 0.9086 train_accuracy : 0.8863 5724.22s epoch[ 9] test_accuracy : 0.9126 train_accuracy : 0.8930 6436.04s epoch[ 10] test_accuracy : 0.9213 train_accuracy : 0.8986 7128.01s epoch[ 11] test_accuracy : 0.9115 train_accuracy : 0.9034 7814.35s epoch[ 12] test_accuracy : 0.9078 train_accuracy : 0.9061 8531.97s epoch[ 13] test_accuracy : 0.9089 train_accuracy : 0.9082 9229.73s epoch[ 14] test_accuracy : 0.9276 train_accuracy : 0.9098 9950.20s epoch[ 15] test_accuracy : 0.9161 train_accuracy : 0.9105 10663.83s epoch[ 16] test_accuracy : 0.9243 train_accuracy : 0.9146 11337.86s epoch[ 17] test_accuracy : 0.9280 train_accuracy : 0.9121 fitting end 50 → その後95%までは行ったがさすがに小規模すぎた
51.
MNIST CNN (DNN部リソース) CNV3x3 CNV3x3 MaxPol Affine CNV3x3 CNV3x3 MaxPol Affine //
sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub0_smm0(1 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub0_smm1(192, 32); bb::NeuralNetGroup<>sub0_net; sub0_net.AddLayer(&sub0_smm0); sub0_net.AddLayer(&sub0_smm1); // sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub1_smm0(32 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub1_smm1(192, 32); bb::NeuralNetGroup<>sub1_net; sub1_net.AddLayer(&sub1_smm0); sub1_net.AddLayer(&sub1_smm1); // sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub3_smm0(32 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub3_smm1(192, 32); bb::NeuralNetGroup<>sub3_net; sub3_net.AddLayer(&sub3_smm0); sub3_net.AddLayer(&sub3_smm1); // sub-networks for convolution(3x3) bb::NeuralNetSparseMicroMlp<6, 16>sub4_smm0(32 * 3 * 3, 192); bb::NeuralNetSparseMicroMlp<6, 16>sub4_smm1(192, 32); bb::NeuralNetGroup<>sub4_net; sub4_net.AddLayer(&sub4_smm0); sub4_net.AddLayer(&sub4_smm1); // main-networks bb::NeuralNetRealToBinary<float>input_real2bin(28 * 28, 28 * 28); bb::NeuralNetLoweringConvolution<>layer0_conv(&sub0_net, 1, 28, 28, 32, 3, 3); bb::NeuralNetLoweringConvolution<>layer1_conv(&sub1_net, 32, 26, 26, 32, 3, 3); bb::NeuralNetMaxPooling<>layer2_maxpol(32, 24, 24, 2, 2); bb::NeuralNetLoweringConvolution<>layer3_conv(&sub3_net, 32, 12, 12, 32, 3, 3); bb::NeuralNetLoweringConvolution<>layer4_conv(&sub4_net, 32, 10, 10, 32, 3, 3); bb::NeuralNetMaxPooling<>layer5_maxpol(32, 8, 8, 2, 2); bb::NeuralNetSparseMicroMlp<6, 16>layer6_smm(32 * 4 * 4, 480); bb::NeuralNetSparseMicroMlp<6, 16>layer7_smm(480, 80); bb::NeuralNetBinaryToReal<float>output_bin2real(80, 10); xc7z020clg400-1 51 DNN部の単体性能 250MHz / (28x28) = 318,877fps
52.
MNIST CNN (システム全体リソース) Camera
+ OLED込みの全体リソース 52 シミュレーション結果
53.
Learning prediction operator CPU 1Core operator CPU 1Core (1
weight calculate instructions) FPGA (XILIN 7-Series) ASIC multi-cycle pipeline multi-cycle pipeline Affine (Float) Multiplier + adder 0.25 cycle Multiplier + adder 0.125 cycle (8 parallel [FMA]) [MUL] DSP:2 LUT:133 [ADD] LUT:413 左×node数 gate : over 10k gate : over 10M Affine (INT16) Multiplier + adder 0.125 cycle Multiplier + adder 0.0625 cycle (16 parallel) [MAC] DSP:1 左×node数 gate : 0.5k~1k gate : over 1M Binary Connect Multiplier + adder 0.25 cycle adder +adder 0.125 cycle (8 parallel) [MAC] DSP:1 左×node数 gate : 100~200 左×node数 BNN/ XNOR-Net Multiplier + adder 0.25 cycle XNOR +popcnt 0.0039+0.0156 cycle (256 parallel) LUT:6~12 (接続数次第) LUT:400~10000 (接続数次第) gate : 20~60 左×node数 6-LUT-Net μPLD 4.6 cycle LUT 1.16 cycle (6 input load + 1 table load) / 6 (256 parallel) LUT : 1 (over spec) LUT : 1 (fit) gate : 10~30 (over spec) gate : 10~30 2-LUT-Net Multiplier + adder 0.5 cycle logic-gate 1.5 cycle (2 input load + 1 table load) / 2 LUT : 1 (over spec) LUT : 1 (over spec) gate : 1 (over spec) gate : 1 (fit) 演算機リソース規模について ※ 重要なところ意外は主観で適当に書いてます m(_ _)m 53 全結線をpipeline展開すると規模爆発するが、疎結合のLUT-Netならフィット
54.
54 LUT-NetworkでAutoEncoder やってみた CNV3x3 CNV3x3 MaxPol Affine CNV3x3 MaxPol 28x28x1 28x28x32 28x28x32 14x14x32 14x14x64 CNV3x3 Affine 32 UpSample CNV3x3 CNV3x3 UpSample CNV3x3 CNV3x3 28x28x1 Modulator Demodulator 14x14x64 14x14x64 7x7x64 14x14x64 28x28x64 14x14x64 14x14x64 28x28x64
55.
結線の問題 • 疎接続する時点で「どこをどう繋ぐか?」は課題として発生 • まだMLPでのMNIST実験だけだが •
下手に規則正しく繋ぐと過学習する模様!?(要精査) • ランダム結線は今のところ意外に性能が良い(というか今のところ最善?) • だが配線混雑でルーティングできないケースも発生 • CNNだとノード数がある程度小さくなるのでこの問題は大幅緩和 • 密結合での重み主体で結線を疎結合化してもランダムに勝てていない 0 0.2 0.4 0.6 0.8 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ランダム結線 test train 0 0.2 0.4 0.6 0.8 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 隣接結線 test train 55 過学習
56.
Real-Time化に向けたアーキ考察 (例:U-Net) Conv Conv Pooling Conv Conv UP Conv Conv frame memory frame memory Motion Compensation Pooling Conv Conv Conv Conv UP Conv Conv Pooling Conv Conv UP Conv Conv frame memory Motion Compensation Motion Compensation SDRAM SDRAM SDRAM pooling後のデータは解像度が低いので1frame前のものを 動き補償して使えばよいのでは? ハイスピードビジョンの動き探索はとても軽量。 一番上だけ最新なら結果も最新 current frame previous
frame previous frame previous frame 56
57.
Real-Timeで 最も尤もらしい結果を出力するアーキ 57 DNN Video-In ME MC Video-Out Frame
Memory オーバーサンプリング系は誤差を次のフレーム以降に持ち越せるので多少間違えてもOK IIRフィルタに帰着できる
58.
深層学習用のハードウェアとしての考察 • Learning用ハードウェアとPredictionハードウェアの関係 • Learning用ハードウェア •
学習の可能性を極力排除しない余裕を持った演算 • Prediction用ハードウェア • 実効性能重視(コスト[$/FLOPS], 熱・バッテリー[W/FLOPS]) • LUT-NetworkはPredictionの効率化を狙った新しい技術提案 • 通常Learning用ハードウェアはそのままPredictionもこなせる(上位互換)が、 LUT-Networkは異なる • 正攻法の後者の追及は量子化とSparse化 → LUT-Network は初めからこのボリュームを最大に捻ってスタート • 学習結果のテーブル化という新しい効率化が本質 • 既存Learning用ハードウェアのアーキテクチャ改善はLUT-Network用のネット の加速にあまり寄与してくれないかも(課題) 58 効率よく 学習結果を 移行させたい
59.
LUT-Netの学習へのGPU活用(検討中) 59 BatchNormalization Binary-Activation ・ ・ ・ μMLP1個の学習 global memory CUDA (SM) shared memory (L1) AVX2
(i7-4770) CUDA(GT 1030) 高速化 μMLP forward 94ms 16ms 5.8倍 μMLP backward 603ms 236ms 2.5倍 Im2Col forward 663ms 15ms 44.2倍 Im2Col backward 498ms 43ms 11.5倍 CUDAのSMのアーキがワーキングセットとしてジャストフィット! L1メモリ部分を排除してDense Tensorの演算の効率を上げるDNN専用 チップより、普通のGPUがLUT-Netの学習には向いている可能性 [少しCUDAも書いて実験] ※ GT1030は論理性能でi7-4770の2倍ぐらい。コーディングの気合の入れ方にそもそもムラが大きい
60.
技術ポイントまとめ(計算機効率) • 演算器個数×クロック周波数以上の演算は出来ない • CPU/GPUは上限が決まっている •
ASICやFPGAでは演算器に回せるリソース量(トランジスタ数)は設計次第 • 演算器個数を増やすには • 演算器に使うトランジスタの比率を増やす(制御や記憶のリソースを減らす) • 専用エンジン(ASIC) > FPGA ≒ GPU > CPU • 演算器を小さくする(演算密度を上げる) • テーブル化(LUT-Net) < INT1 (Binary-Net) < INT8 < FP16 < FP32 • 演算器稼働率を上げる(無駄な計算はしない) • 学習時には多くの可能性が欲しい • backwardで勾配消失しない十分な精度 → FP16~FP32 • 十分な結合 → 演算できる範囲で密結合 • 推論時には結果に影響する演算だけを効率よくやりたい • 不要な計算の削除 → 疎結合網 60
61.
Real-Time DNNしながらFPGAのリリースを使い尽くす • LUT •
LUT-Networkのレイヤーに利用 • Block-RAM(SRAM) • 畳み込みのラインバッファ • DSP(積和演算機) • 入力の1段目だけ普通の掛け算にする • 画像を認識する上で多値の勾配などの情報は魅力的 • I/O • 外界の機器と演算ユニットを直結 • エッジコンピューティングの醍醐味 • 高速シリアル • 別のエッジと連携 • ロジック規模拡張に複数FPGA • DDR3/4-SDRAM • U-Net や RNNのバッファとして • AIコア(Versal ACAP) • さてどうするべきか? 61 LUT以外のリソースも使い切ってこそのFPGA活用
62.
リファレンス • BinaryConnect: Training
Deep Neural Networks with binary weights during propagations https://arxiv.org/pdf/1511.00363.pdf • Binarized Neural Networks https://arxiv.org/abs/1602.02505 • Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1 https://arxiv.org/abs/1602.02830 • XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks https://arxiv.org/abs/1603.05279 • Xilinx UltraScale Architecture Configurable Logic Block User Guide https://japan.xilinx.com/support/documentation/user_guides/ug574-ultrascale-clb.pdf 62
Download

![自己紹介
• 基本的にサンデープログラマ(平日はサラリーマンやってる2児の父親)
• 1976年生まれ 全国転々としつつも結局、福岡が一番長く、今も福岡在住
• 1998~ μITRON仕様 Real-Time OS HOS-80 をリリース
• 現在 HOS-V4a にて各種組み込みCPUに対応
(ARM,H8,SH,MIPS,x86,Z80,AM,V850,MicroBlaze, etc.)
• 2008~ FPGA用ソフトコアSoC環境 Jelly をリリース(MIPS互換コア)
• 現在 Zynq 上にて Real-Time GPU や LUT-Network の実験など
各種 Real-Time コア開発の実験場と化す
• 2018~ LUT-Network用の環境 BinaryBrain を開発中
• 本日のお題
• リアルタイムコンピューティング(当然Edgeコンピュータ)が大好き
• 電脳メガネ計画(いつかやりたい電脳コイルの世界)
• Real-Time 画像I/O (カメラ[IMX219] & OLED 1000fps駆動)
• Real-Time GPU開発 (frame buffer無し、ゼロ遅延描画)
• Real-Time DNN開発 (超低遅延DNN認識)
2](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-2-320.jpg)















![LUTの学習方法
• LUTテーブルの学習方法
• 直接学習(力技での学習実験)
• Micro-MLPによるバイナリ値で学習する方法 (2018/02/02 fpgaxで発表)
• Stochastic-LUTによる確率値で学習する方法 [New!]
• Stochastic-LUTモデルを Micro-MLP的に使ってバイナリ値で学習する方法 [New!]
• バイナリ学習の底上げ
• バイナリ変調を行う方法 [Update]
• 番外(新モデルの非バイナリ応用)
• Stochastic-LUTモデルをStochasticガン無視で、浮動小数点の学習として、パーセプト
ロンの変わりに使う方法 [New!]
18
まだまだ試行錯誤中ですが、いろいろな知見が得られてきました](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-18-320.jpg)
![[直接学習] 学習方法
入力値 発生回数 0出力時の損失 1出力時の損失
0 37932 47813.7 48233.9
1 39482 50001.3 49692.9
2 37028 44698.9 44845.7
3 40640 49257.1 49331.0
4 27156 33998.4 33891.0
5 23930 29538.6 29495.2
6 29002 35197.3 35451.4
7 27786 33390.9 33466.9
8 43532 52741.1 52993.5
9 41628 49985.9 50388.5
10 49176 56521.4 56026.1
11 46542 54215.4 54284.9
・・・・
・・・・
・・・・
・・・・
59 34268 41152.9 41215.8
60 22872 28852.4 29000.0
61 17930 22068.9 22112.9
62 24156 28213.2 28227.1
63 24194 28367.0 28450.4
新しいテーブル値
0
1
0
0
1
1
0
0
0
0
1
0
・・・・
0
0
0
0
0
1. LUTテーブルを一旦乱数で埋める
2. ある1個のLUTの出力を0と1それぞれに固定して学習データ全部流す
3. LUTの入力値毎に損失関数の総和を取っておき、損失が減る方向にテーブルを更
新
19](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-19-320.jpg)
![[直接学習] MNISTの学習実験
0.6
0.65
0.7
0.75
0.8
0.85
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
MNIST学習実験
学習データ(6万個) 評価データ(1万個)
小規模実験ではあるが、学習に用いたデータでの認識率とほぼ対応する
形で、評価用のデータセットでも認識率の向上が見られた。
層構成:360-180-30 の570個のLUTを利用
結線 :全層ともランダム結線
20
思いの外、過学習的な挙動を示さない](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-20-320.jpg)
![
yxwvu
tsrqp
onmlk
jihgf
edcba
000
000
000
000
000
wv
ts
ok
gf
db
Dense-Affine (Fully Connection)
Sparse-Affine (最初のアイデア)
・
・
・
synthesis
LUT
LUT
LUT
LUT
LUT
LUT
LUTmapping
BatchNormalization
Binary-Activation
BatchNormalization
Binary-Activation
Deep Logic
(Low-speed and Middle
Performance)
同じくXORはだめ
でも高速(300MHz~400MHz)
1層ではXORは学習できない
100MHz~200MHz
micro-MLPを束ねた層
LUTmapping
BatchNormalization
Binary-Activation
1層でXORも学習できる
高速(300MHz~400MHz)
・
・
・
Simple Logic
(High-speed and Low Performance)
Simple Logic
(High-speed and High Performance)
BNもLUT内に含める
隠れ層もLUT内に含める
この単位を micro-MLP として定義
[誤差逆伝播] Micro-MLPのアイデア
21](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-21-320.jpg)
![[誤差逆伝播] バイナリ活性層 (binary activation layer)
• forward
• Sign()
• 𝑦 =
1 𝑖𝑓 𝑥 ≥ 0,
0 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒,
• 符号見るだけ
• backward
• hard-tanh()
• 𝑔 𝑥 = 1 𝑥 ≤1
• 小さい値の時のみ伝播
Binary Connect の方法をそのまま拝借(先人の知恵に感謝)
重みは実数なので Batch Normalization はオリジナルの実数版を使う
22
BatchNormalization
Binary-Activation
・
・
・](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-22-320.jpg)
![[誤差逆伝播] micro-MLP の学習
Affine Layer
(16~64 perceptron)
Activation Layer
Sigmoid or ReLU
・・・・
・・・・
Affine Layer
(1 perceptron)
Batch Normalization
Activation Layer
Binarize
6 signals input (0.0 or 1.0)
【Learning (FP32) [CPU/GPU]】
1 signal output (0.0 or 1.0)
×16~64
(FP32)
×1 (FP32)
【Prediction (Binary) [FPGA)]】
LUT
(64bit Look-up Table)
6 signals input (H or L)
1 signal output (H or L)
Affine Layer
(16~64 perceptron)
Activation Layer
Sigmoid or ReLU
・・・・
・・・・
Affine Layer
(1 perceptron)
Batch Normalization
Activation Layer
hard-tanh
1 gradient input (FP32)
6 gradients output (FP32)
<Forward> <Backward>
<Forward>
logic
synthesis
× 16~64
(FP32)
×1 (FP32)
×6 (Binary)
×1 (Binary)
×1 (FP32)
×1 (FP32)
×6 (FP32)
×16~64
(FP32)
× 16~64
(FP32)
×1 (FP32)
23](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-23-320.jpg)







![[新アイデア] Stochastic-LUTモデル
32
-
*
-
x0
x1
*
W0
binarize
*
*
W1
*
*
W2
*
*
W3
1
1
+ y
2入力LUTの例 x0-x1 を入力する確率変数. W0-W3 をテーブル値とする
W0 が参照される確率 : (1 - x1) * (1 - x0)
W1 が参照される確率 : (1 - x1) * x0
W2 が参照される確率 : x1 * (1 - x0)
W3 が参照される確率 : x1 * x0
y = W0 * (1 - x1) * (1 - x0)
+ W1 * (1 - x1) * x0
+ W2 * x1 * (1 - x0)
+ W3 * x1 * x0
値をすべて観測時に0と1のどちらかの値に決まる確率変数として確率値をFP32で扱います。
この計算グラフは微分可能であるため、誤差逆伝播が可能です。
6入力LUTのグラフは図示すると巨大になるので作成していませんが、同様に作成可能です。
確率的LUTモデルを用いることで、一度に非常に多くのバイナリ値を計算したのと同じ効果が得られるた
め、micro-MLPよりも高速/高精度な結果が得られます。W値はそのままLUT化できます。
これだけでLUTを完全モデル化
Batch-Normalization不要
Activationも不要](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-32-320.jpg)
![確率的LUTモデルの内部のパラメータ
33
input[n-1:0]
output
LUTテーブルは入力数nに対してn次元を持ち、その中で連続体として振舞いま
す。
上記は2入力LUTにXORを学習させた場合の模式図です。
内部の状態テーブルを参照する形式を取るために、パーセプトロン素子と違って
内部テーブルがXOR形状に学習することも可能です](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-33-320.jpg)






![学習用OSSの紹介(BinaryBrain)
• 今回の実験の為に開発した環境(C++ & Eigen)
• githubにて公開中
• https://github.com/ryuz/BinaryBrain
• 特徴
• TensorFlowもChainerもTorchもCaffeも知らずノリで書いた(笑)
• 参考書は「ゼロから作るDeep Learning」のみ
• RTL(Verilog)を出力できる[今のところ Xilinxしか試してないですが]
• NCHWでもNHWCでもないCHWNメモリ配置
→ 1bitデータをメモリにパッキングしたままSIMD演算
• CUDA対応、FMA2命令とかも活用
• 普通のDNNもシンプルなCNN程度なら学習可能
(条件を揃えてベンチマークがしたい)
Ver.1(直接学習の実験)→ Ver.2(micro-MLPでの逆伝播の実験)
→ Ver.3を開発中(GPU対応/Stochasticモデル)
40](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-40-320.jpg)





![FPGAとGPUの比較
46
[FPGA] Digi-Key XPS
品番 LUT 円 円/LUT W W/LUT
XC7A200T-1FBG484C 134,600 22,662 0.168
XC7A100T-1FTG256C 63,400 12,776 0.202
XC7A75T-1FTG256C 47,200 10,835 0.230
XC7A50T-1FTG256C 32,600 6,224 0.191
XC7A35T-1FTG256C 20,800 4,021 0.193
XC7A25T-1CPG238C 14,600 3,849 0.264
XC7A15T-1FTG256C 10,400 3,268 0.314
XC7A12T-1CPG238C 8,000 3,006 0.376
XC7S6-1CSGA225 3,752 1,720 0.458 4.821 0.0013
[GPU] 価格.com Wiki
品番 CUDA cores 円 円/core TDP W/core
RTX 2080Ti 4,352 129,790 29.823 250 0.0574
RTX 2080 2,944 79,800 27.106 215 0.0730
RTX 2070 2,304 53,977 23.428 175 0.0760
RTX 2060 1,920 36,698 19.114 160 0.0833
GTX 1660Ti 1,536 31,980 20.820 120 0.0781
GTX 1660 1,408 25,780 18.310 120 0.0852
GTX 1650 896 16,990 18.962 75 0.0837
GTX 1070Ti 2,432 56,980 23.429 180 0.0740
GTX1060 1,280 21,700 16.953 120 0.0938
GT 1030 384 8,680 22.604 30 0.0781
Jetson Nano 128 12800 100.000 7.5 0.0586
同じことをFPGAとGPUで行った場合、
FPGAだとLUT:20~100個で出来てしまうこと
が、CPU/GPUだと数サイクル使ってしまうよ
うなケースでFPGAが有利
したがって、低bit数の演算であればFPGAに分
がある。
特にLUT-Networkと同じことをCPU/GPUでや
る場合、1個のLUT分の演算で数サイクルを消
費するような関係なので極めて性能差が出る](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-46-320.jpg)
![実例紹介1 [MNIST MLP]
(1000fps 動作)
DNN
(LUT-Net)
MIPI-CSI
RX
Raspberry Pi
Camera V2
(Sony IMX219)
SERDE
S
TX
PS
(Linux)
SERDES
RX
FIN1216
DMA
OLED
UG-9664HDDAG01
DDR3
SDRA
M
I2C
MIPI-CSI
Original Board
PCX-Window
1000fps
640x132
1000fps
control
PL (Jelly)
BinaryBrain
Ether
RTL
offline learning (PC)
ZYBO Z7-20
debug view
47
動画紹介](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-47-320.jpg)


![MNIST CNN 学習時ログ
fitting start : MnistCnnBin
initial test_accuracy : 0.1518
[save] MnistCnnBin_net_1.json
[load] MnistCnnBin_net.json
fitting start : MnistCnnBin
[initial] test_accuracy : 0.6778 train_accuracy : 0.6694
695.31s epoch[ 2] test_accuracy : 0.7661 train_accuracy : 0.7473
1464.13s epoch[ 3] test_accuracy : 0.8042 train_accuracy : 0.7914
2206.67s epoch[ 4] test_accuracy : 0.8445 train_accuracy : 0.8213
2913.12s epoch[ 5] test_accuracy : 0.8511 train_accuracy : 0.8460
3621.61s epoch[ 6] test_accuracy : 0.8755 train_accuracy : 0.8616
4325.83s epoch[ 7] test_accuracy : 0.8713 train_accuracy : 0.8730
5022.86s epoch[ 8] test_accuracy : 0.9086 train_accuracy : 0.8863
5724.22s epoch[ 9] test_accuracy : 0.9126 train_accuracy : 0.8930
6436.04s epoch[ 10] test_accuracy : 0.9213 train_accuracy : 0.8986
7128.01s epoch[ 11] test_accuracy : 0.9115 train_accuracy : 0.9034
7814.35s epoch[ 12] test_accuracy : 0.9078 train_accuracy : 0.9061
8531.97s epoch[ 13] test_accuracy : 0.9089 train_accuracy : 0.9082
9229.73s epoch[ 14] test_accuracy : 0.9276 train_accuracy : 0.9098
9950.20s epoch[ 15] test_accuracy : 0.9161 train_accuracy : 0.9105
10663.83s epoch[ 16] test_accuracy : 0.9243 train_accuracy : 0.9146
11337.86s epoch[ 17] test_accuracy : 0.9280 train_accuracy : 0.9121
fitting end
50
→ その後95%までは行ったがさすがに小規模すぎた](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-50-320.jpg)


![Learning prediction
operator
CPU
1Core
operator
CPU 1Core
(1 weight calculate instructions)
FPGA
(XILIN 7-Series)
ASIC
multi-cycle pipeline multi-cycle pipeline
Affine
(Float)
Multiplier
+ adder
0.25
cycle
Multiplier
+ adder
0.125 cycle
(8 parallel [FMA])
[MUL] DSP:2
LUT:133
[ADD] LUT:413
左×node数 gate : over 10k gate : over 10M
Affine
(INT16)
Multiplier
+ adder
0.125
cycle
Multiplier
+ adder
0.0625 cycle
(16 parallel)
[MAC] DSP:1 左×node数 gate : 0.5k~1k gate : over 1M
Binary
Connect
Multiplier
+ adder
0.25
cycle
adder
+adder
0.125 cycle
(8 parallel)
[MAC] DSP:1 左×node数 gate : 100~200 左×node数
BNN/
XNOR-Net
Multiplier
+ adder
0.25
cycle
XNOR
+popcnt
0.0039+0.0156 cycle
(256 parallel)
LUT:6~12
(接続数次第)
LUT:400~10000
(接続数次第)
gate : 20~60 左×node数
6-LUT-Net μPLD
4.6
cycle
LUT
1.16 cycle
(6 input load
+ 1 table load) / 6
(256 parallel)
LUT : 1
(over spec)
LUT : 1
(fit)
gate : 10~30
(over spec)
gate : 10~30
2-LUT-Net
Multiplier
+ adder
0.5
cycle
logic-gate
1.5 cycle
(2 input load
+ 1 table load) / 2
LUT : 1
(over spec)
LUT : 1
(over spec)
gate : 1
(over spec)
gate : 1
(fit)
演算機リソース規模について
※ 重要なところ意外は主観で適当に書いてます m(_ _)m
53
全結線をpipeline展開すると規模爆発するが、疎結合のLUT-Netならフィット](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-53-320.jpg)




![深層学習用のハードウェアとしての考察
• Learning用ハードウェアとPredictionハードウェアの関係
• Learning用ハードウェア
• 学習の可能性を極力排除しない余裕を持った演算
• Prediction用ハードウェア
• 実効性能重視(コスト[$/FLOPS], 熱・バッテリー[W/FLOPS])
• LUT-NetworkはPredictionの効率化を狙った新しい技術提案
• 通常Learning用ハードウェアはそのままPredictionもこなせる(上位互換)が、
LUT-Networkは異なる
• 正攻法の後者の追及は量子化とSparse化
→ LUT-Network は初めからこのボリュームを最大に捻ってスタート
• 学習結果のテーブル化という新しい効率化が本質
• 既存Learning用ハードウェアのアーキテクチャ改善はLUT-Network用のネット
の加速にあまり寄与してくれないかも(課題)
58
効率よく
学習結果を
移行させたい](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-58-320.jpg)
![LUT-Netの学習へのGPU活用(検討中)
59
BatchNormalization
Binary-Activation
・
・
・
μMLP1個の学習
global memory
CUDA
(SM)
shared memory
(L1)
AVX2 (i7-4770) CUDA(GT 1030) 高速化
μMLP forward 94ms 16ms 5.8倍
μMLP backward 603ms 236ms 2.5倍
Im2Col forward 663ms 15ms 44.2倍
Im2Col backward 498ms 43ms 11.5倍
CUDAのSMのアーキがワーキングセットとしてジャストフィット!
L1メモリ部分を排除してDense Tensorの演算の効率を上げるDNN専用
チップより、普通のGPUがLUT-Netの学習には向いている可能性
[少しCUDAも書いて実験]
※ GT1030は論理性能でi7-4770の2倍ぐらい。コーディングの気合の入れ方にそもそもムラが大きい](https://image.slidesharecdn.com/lut-network20190710-190710153707/85/LUT-Network-Edge-AI-59-320.jpg)

























![GPUとSSDがPostgreSQLを加速する~クエリ処理スループット10GB/sへの挑戦~ [DB Tech Showcase Tokyo/2017]](https://cdn.slidesharecdn.com/ss_thumbnails/20170906dbtsgpussdacceleratespostgresqljp-170906073226-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)









