Downloaded 38 times





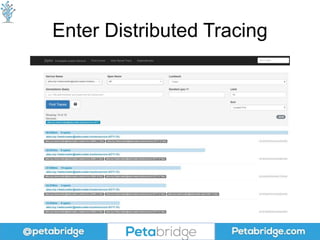
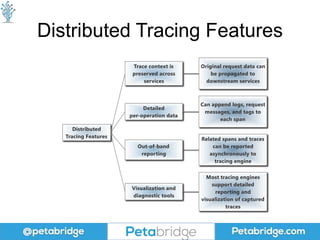
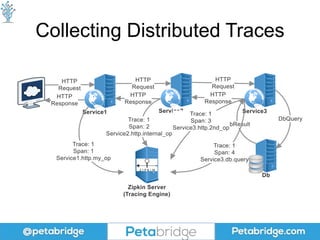
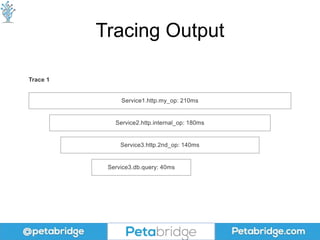


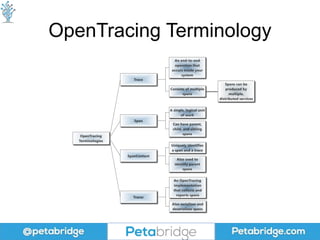






This document discusses distributed tracing and how it can help solve problems caused by microservices. It covers what distributed tracing is, how it works, popular implementations like OpenTracing and Zipkin, and best practices for using distributed tracing. OpenTracing is introduced as a vendor-neutral standard that helps library developers implement tracing and defines common formats for propagating traces between services. Code examples are provided for collecting trace data using OpenTracing and Zipkin.























































































