Download to read offline




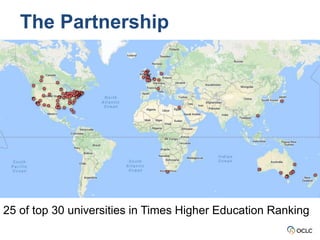
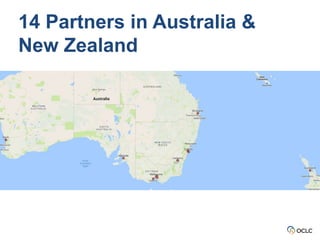











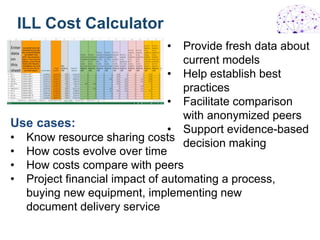




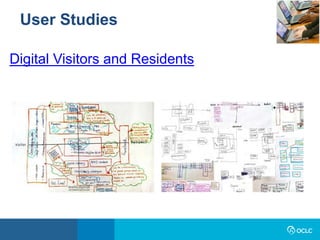








The document outlines the activities and objectives of the OCLC Research Library Partnership, focusing on collaboration among libraries to enhance learning and innovation. It highlights various working groups, initiatives on data curation, web archiving, and metadata management, and emphasizes the importance of shared resources and best practices within the library community. The report also discusses engagement strategies to empower library staff and improve community outreach through platforms like Wikipedia.








































































































