HDFS
● Hadoop DistributedFileSystem
○ 기본적으로 파일 시스템
● 주요 특징
○
○
○
○
블록 단위 파일 보관
■ 파일을 블록 단위로 나눠서 보관 (기본설정: 64M)
분산 파일 시스템
■ 블록을 다중 노드에 분산해서 보관
리플리케이션
■ 하나의 블록은 여러 노드에 복제
■ 특정 노드 장애에 무정지 대응
범용 장비 사용
4.
HDFS는 파일 시스템
●파일 시스템에 접근하기 위한 쉘스크립트(명
령행 인터페이스) 제공
$ hadoop fs -copyFromLocal typesafe-activator-1.0.0.zip hdfs://localhost/typesafe.zip
$ hadoop fs -ls hdfs://localhost/
Found 2 items
-rw-r--r-- 1 madvirus supergroup 125491 2013-12-02 18:00 /passion.jpg
-rw-r--r-- 1 madvirus supergroup 264523514 2013-12-02 18:01 /typesafe.zip
$ hadoop fs -copyToLocal hdfs://localhost/img/passion.jpg passion2.jpg
● 클라이언트
○ 쉘 스크립트, 자바 API, HTTP 등 제공
5.
HDFS 블록
● 블록
○HDFS에서의 파일은 블록 크기로 분리되어 저장
○ 기본 블록 크기는 64MB (128MB로 많이 사용)
○ 파일 분리 예
■ 256MB 파일은 64M 네 개의 블록으로 분리되어
저장 (즉, 4개의 파일로 분리되어 저장)
■ 블록 크기보다 작은 파일은 단일 블록으로 저장
●
이 경우, 블록 파일의 크기는 실제 파일 크기임
○ 단일 디스크보다 더 큰 파일을 보관할 수 있음
○ 복제 단위
■ 노드 간 데이터 복사는 블록 단위로 됨
6.
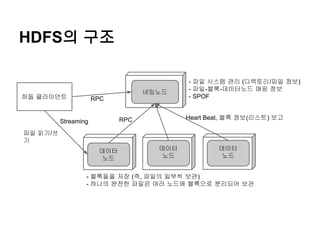
HDFS의 구조
네임노드
하둡 클라이언트
RPC
HeartBeat, 블록 정보(리스트) 보고
RPC
Streaming
- 파일 시스템 관리 (디렉토리/파일 정보)
- 파일-블록-데이터노드 매핑 정보
- SPOF
파일 읽기/쓰
기
데이터
노드
데이터
노드
데이터
노드
- 블록들을 저장 (즉, 파일의 일부씩 보관)
- 하나의 완전한 파일은 여러 노드에 블록으로 분리되어 보관
7.
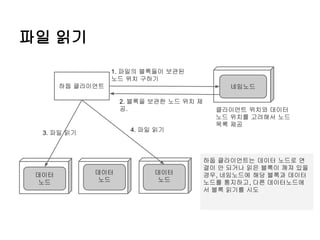
파일 읽기
1. 파일의블록들이 보관된
노드 위치 구하기
하둡 클라이언트
네임노드
2. 블록을 보관한 노드 위치 제
공.
4. 파일 읽기
3. 파일 읽기
데이터
노드
데이터
노드
데이터
노드
클라이언트 위치와 데이터
노드 위치를 고려해서 노드
목록 제공
하둡 클라이언트는 데이터 노드로 연
결이 안 되거나 읽은 블록이 깨져 있을
경우, 네임노드에 해당 블록과 데이터
노드를 통지하고, 다른 데이터노드에
서 블록 읽기를 시도
8.
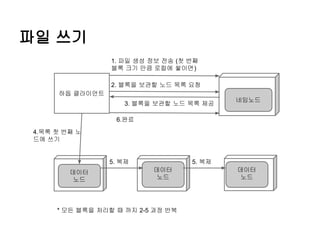
파일 쓰기
1. 파일생성 정보 전송 (첫 번째
블록 크기 만큼 로컬에 쌓이면)
2. 블록을 보관할 노드 목록 요청
하둡 클라이언트
3. 블록을 보관할 노드 목록 제공
네임노드
6.완료
4.목록 첫 번째 노
드에 쓰기
5. 복제
데이터
노드
5. 복제
데이터
노드
* 모든 블록을 처리할 때 까지 2-5 과정 반복
데이터
노드
9.
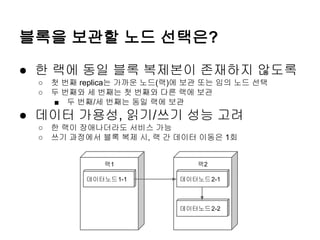
블록을 보관할 노드선택은?
● 한 랙에 동일 블록 복제본이 존재하지 않도록
○
○
첫 번째 replica는 가까운 노드(랙)에 보관 또는 임의 노드 선택
두 번째와 세 번째는 첫 번째와 다른 랙에 보관
■ 두 번째/세 번째는 동일 랙에 보관
● 데이터 가용성, 읽기/쓰기 성능 고려
○
○
한 랙이 장애나더라도 서비스 가능
쓰기 과정에서 블록 복제 시, 랙 간 데이터 이동은 1회
랙1
데이터노드1-1
랙2
데이터노드2-1
데이터노드2-2
10.
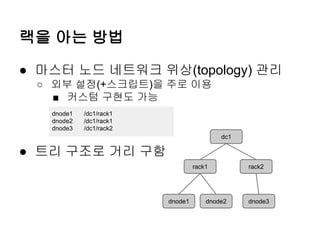
랙을 아는 방법
●마스터 노드 네트워크 위상(topology) 관리
○ 외부 설정(+스크립트)을 주로 이용
■ 커스텀 구현도 가능
dnode1
dnode2
dnode3
/dc1/rack1
/dc1/rack1
/dc1/rack2
dc1
● 트리 구조로 거리 구함
rack1
dnode1
dnode2
rack2
dnode3
11.
네임노드 데이터
● 메모리
○파일 시스템 메타 데이터
■
■
디렉토리, 파일명, 블록, 블록-데이터노드 매핑 정보
톰 화이트, “경험상 백만 블록 당1,000MB 메모리 사용(보수적)”
● 파일
○ 두 개의 파일
■ edits: 변경 내역
■ fsimage: 특정 시점의 데이터 스냅샷
●
●
디렉토리, 파일명, 블록, 상태 정보
블록-데이터노드 매핑 정보는 포함하지 않음
○ 이 정보는 네임노드 구동 시점에, 데이터노드로부터 받음
12.
네임노드 구동 과정
1.파일로부터 메모리에 데이터 생성
a. fsimage를 메모리에 로딩
b. edits를 읽어와 메모리에 변경 내역 반영
2. 스냅샷 생성
a. 현재의 메모리 상태를 fsimage로 내림
b. 빈 edits 생성
3. 데이터 노드로부터 블록 정보 수신
a. 메모리에 블록-데이터노드 매핑 정보 생성
4. 정상 서비스 시작
안전모드: 1~3 과정, 네임 노드 서비스 안 됨
13.
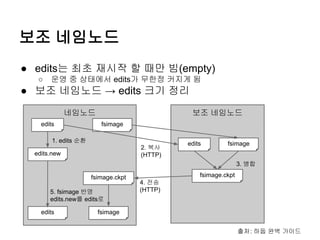
보조 네임노드
● edits는최초 재시작 할 때만 빔(empty)
○
운영 중 상태에서 edits가 무한정 커지게 됨
● 보조 네임노드 → edits 크기 정리
네임노드
edits
보조 네임노드
fsimage
1. edits 순환
2. 복사
(HTTP)
edits.new
edits
fsimage
3. 병합
fsimage.ckpt
5. fsimage 반영
edits.new를 edits로
edits
fsimage.ckpt
4. 전송
(HTTP)
fsimage
출처: 하둡 완벽 가이드
HDFS 장애: 블록깨짐
● 체크섬 파일: 블록과 함께 생성
○ 체크섬 파일은 데이터 노드에 함께 보관
● 데이터노드:
○ 주기적으로 블록 스캐너 실행 (체크섬 오류 확인)
■ 문제 있는 블록을 네임노드에 통지
● 클라이언트
○ 블록을 읽을 때 체크섬도 읽어와 오류 확인
○ 오류 있을 시, 네임노드에 해당 블록 오류 통지
● 네임노드
○ 통지받은 오류 블록에 해당하는 다른 복제본 복사
○ 오류 블록 소유 데이터 노드에 삭제 지시
16.
HDFS 장애 대응:데이터노드 장애
● 데이터노드 → 네임노드: heart beat 전송
○ 주기적으로 전송
● 네임노드
○ 데이터노드의 heart beat이 없으면 장애로 판단
○ 장애 데이터노드를 서비스 대상에서 제외
○ 장애 데이터노드가 포함한 블록들에 대한 복제 수행
해서 복제본 개수를 맞춤
17.
HDFS 장애 대응:네임노드
● 하둡1
○ SPOF
○ 수동 처리
● 최소
○ 공유파일 시스템(NFS 같은 것)에 edits와 fsimage 보
관
○ 노드 장애 발생시, 다른 장비를 네임노드로 사용
■ 데이터노드로부터 블록 정보 수신 필요
● 업체 별 지원
○ CDH4 Auto-Failover, ZooKeeper 저널
■ Active-Standby로 구성 (하둡2 방식과 동일?)
18.
HDFS 장애 대응:네임노드
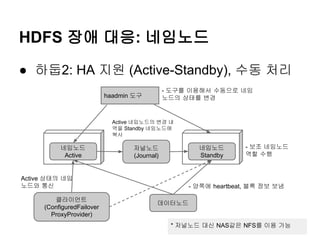
● 하둡2: HA 지원 (Active-Standby), 수동 처리
- 도구를 이용해서 수동으로 네임
노드의 상태를 변경
haadmin 도구
Active 네임노드의 변경 내
역을 Standby 네임노드에
복사
네임노드
Active
네임노드
Standby
저널노드
(Journal)
Active 상태의 네임
노드와 통신
클라이언트
(ConfiguredFailover
ProxyProvider)
- 보조 네임노드
역할 수행
- 양쪽에 heartbeat, 블록 정보 보냄
데이터노드
* 저널노드 대신 NAS같은 NFS를 이용 가능
19.
HDFS 장애 대응:네임노드
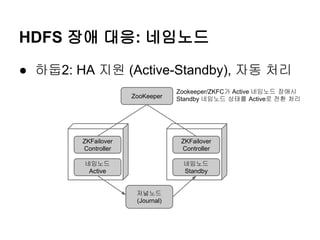
● 하둡2: HA 지원 (Active-Standby), 자동 처리
ZooKeeper
Zookeeper/ZKFC가 Active 네임노드 장애시
Standby 네임노드 상태를 Active로 전환 처리
ZKFailover
Controller
ZKFailover
Controller
네임노드
Active
네임노드
Standby
저널노드
(Journal)
20.
기타
● 밸런서
○ 사용률이높은 데이터노드의 블록을 사용률이 낮은
데이터노드로 이동
○ 하둡 클러스터에서 백그라운드로 동작
● 하둡 아카이브
○ 하둡에 보관된 여러 파일을 아카이브(1개 파일)로 묶
음
○ 아카이브에 포함된 파일을 조회/접근 가능
○ 작은 파일들을 1개 파일로 전환해서 네임노드의 메모
리 사용량 감소

















































![[2A7]Linkedin'sDataScienceWhyIsItScience](https://cdn.slidesharecdn.com/ss_thumbnails/2a7linkedinsdatasciencewhyisitscience-140930023218-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)






































