More Related Content

PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~ 
PPTX

PPTX

PDF
競プロは社会の役に立たない+ベンチャー企業の話 (NPCA夏合宿OB講演).pdf 
PPT

PDF

PDF

PDF
What's hot

PDF

PPTX
ネットストーカー御用達OSINTツールBlackBirdを触ってみた.pptx 
PPTX

PDF

PDF
スパースモデリング、スパースコーディングとその数理(第11回WBA若手の会) 
PDF

PDF

PDF

PPTX
トランザクションをSerializableにする4つの方法 
PDF

PDF

PDF

PDF

PDF
DSIRNLP #3 LZ4 の速さの秘密に迫ってみる 
PPTX

PDF

PPTX

PDF

PDF

PDF
Viewers also liked

PPT

PPT

PPTX

PDF

PPT
FINAL FANTASY Record Keeper の作り方 
PDF

PDF
ABテスト・LPOのための統計学【社内向けサディスティックエディション】データアーティスト株式会社 
PPT

PPTX
What is jubatus? How it works for you? 
PPTX

PDF

PDF
AWSを利用する上で考えたいHA構成とAWSを活用した既存DCのバックアップ 
PPTX

PDF

PDF

PPTX

PDF

PDF

PPT

PDF
Similar to キャッシュコヒーレントに囚われない並列カウンタ達

PDF
プログラミングコンテストでのデータ構造 2 ~動的木編~ 
PPT

PPTX
C#や.NET Frameworkがやっていること 
PDF

PPTX
Coherenceを利用するときに気をつけること #OracleCoherence 
PDF
PEZY-SC programming overview 
PDF

PDF
Infinispan - Open Source Data Grid rev2 
PDF

PDF
Intel TSX HLE を触ってみた x86opti 
PDF

PDF

PDF

PDF
Guide to Cassandra for Production Deployments 
PDF

PDF

PDF
Cassandraのトランザクションサポート化 & web2pyによるcms用プラグイン開発 
PDF

PPTX

PDF
P2P 技術と Cloud コンピューティングへの応用 キャッシュコヒーレントに囚われない並列カウンタ達
- 1.
- 2.
- 3.
- 4.
- 5.
All programmer shouldknow
• L1 キャッシュ参照......................... 0.5 ns
• 分岐予測ミス............................ 5 ns
• L2 キャッシュ参照........................... 7 ns
• Mutex lock/unlock ........................... 25 ns
• Main memory 参照...................... 100 ns
- 6.
- 7.
- 8.
- 9.
- 10.
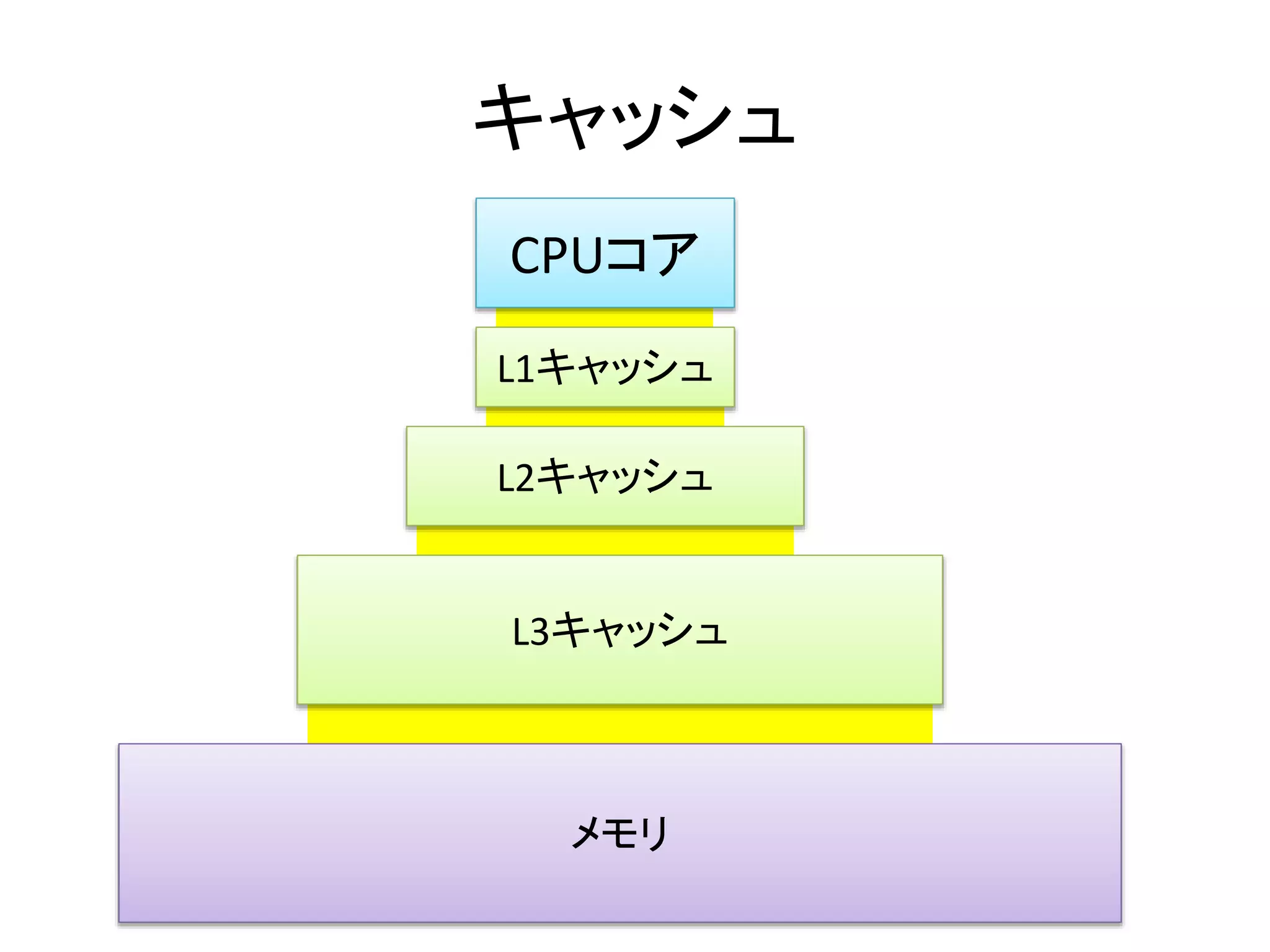
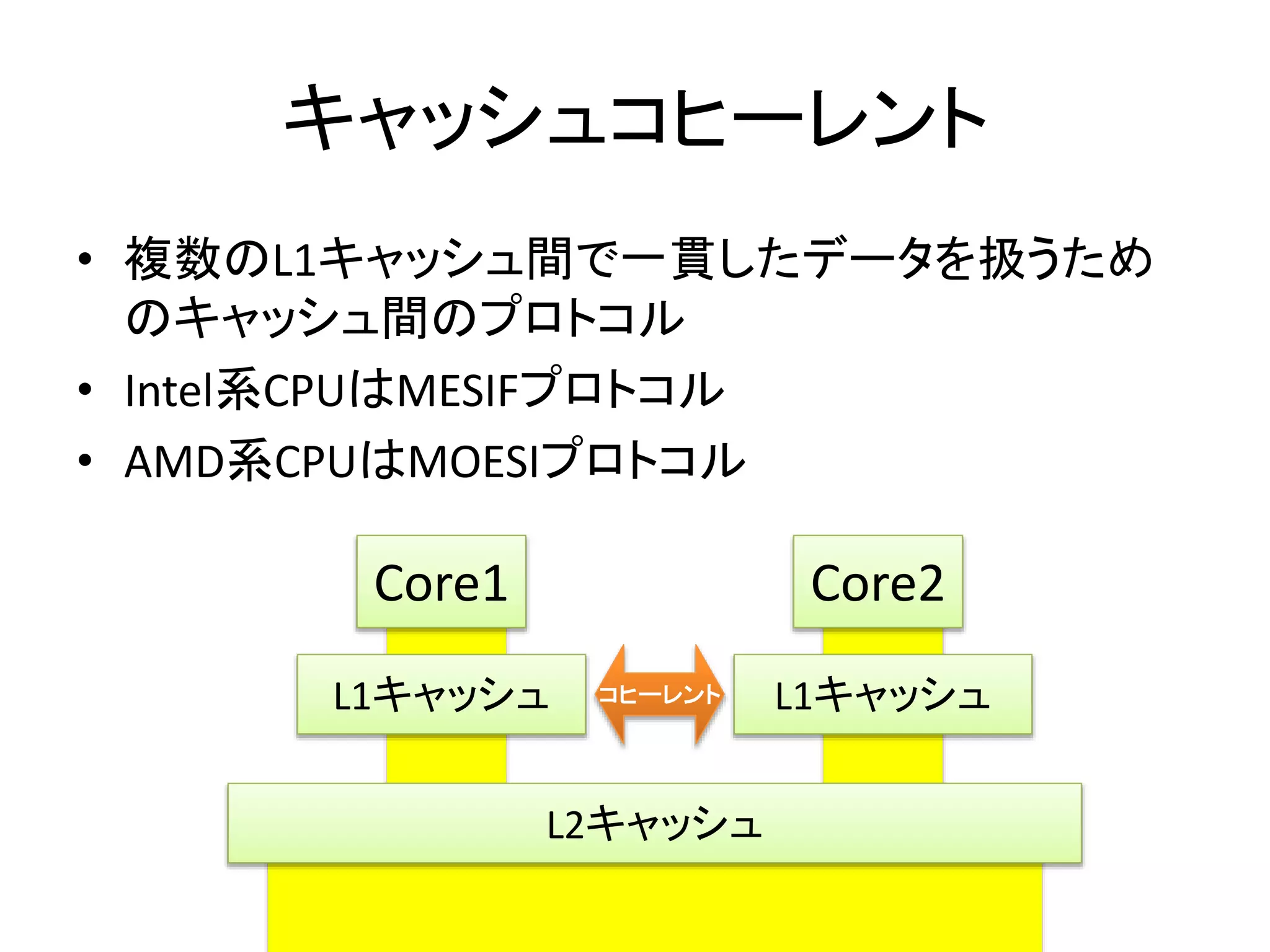
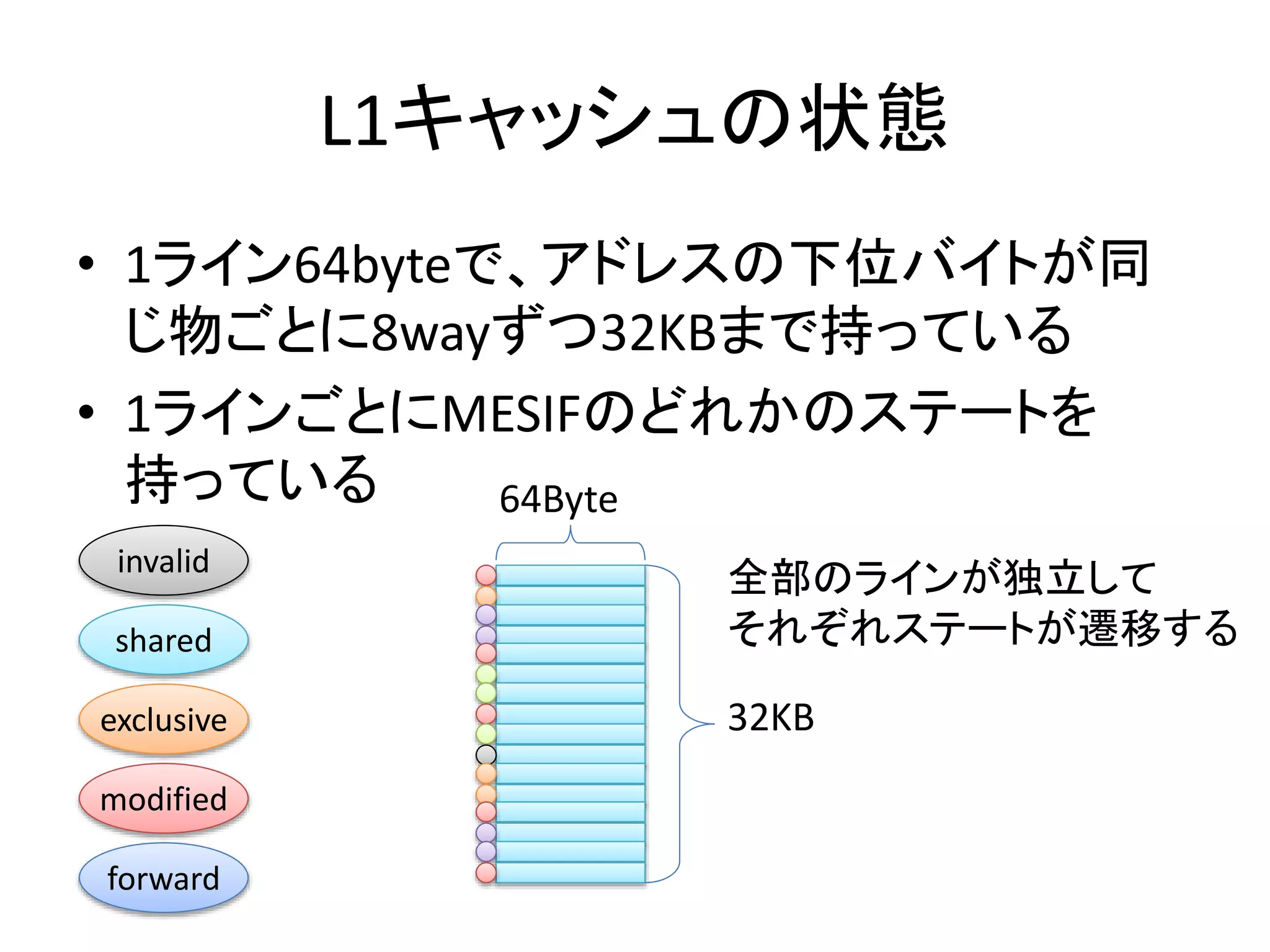
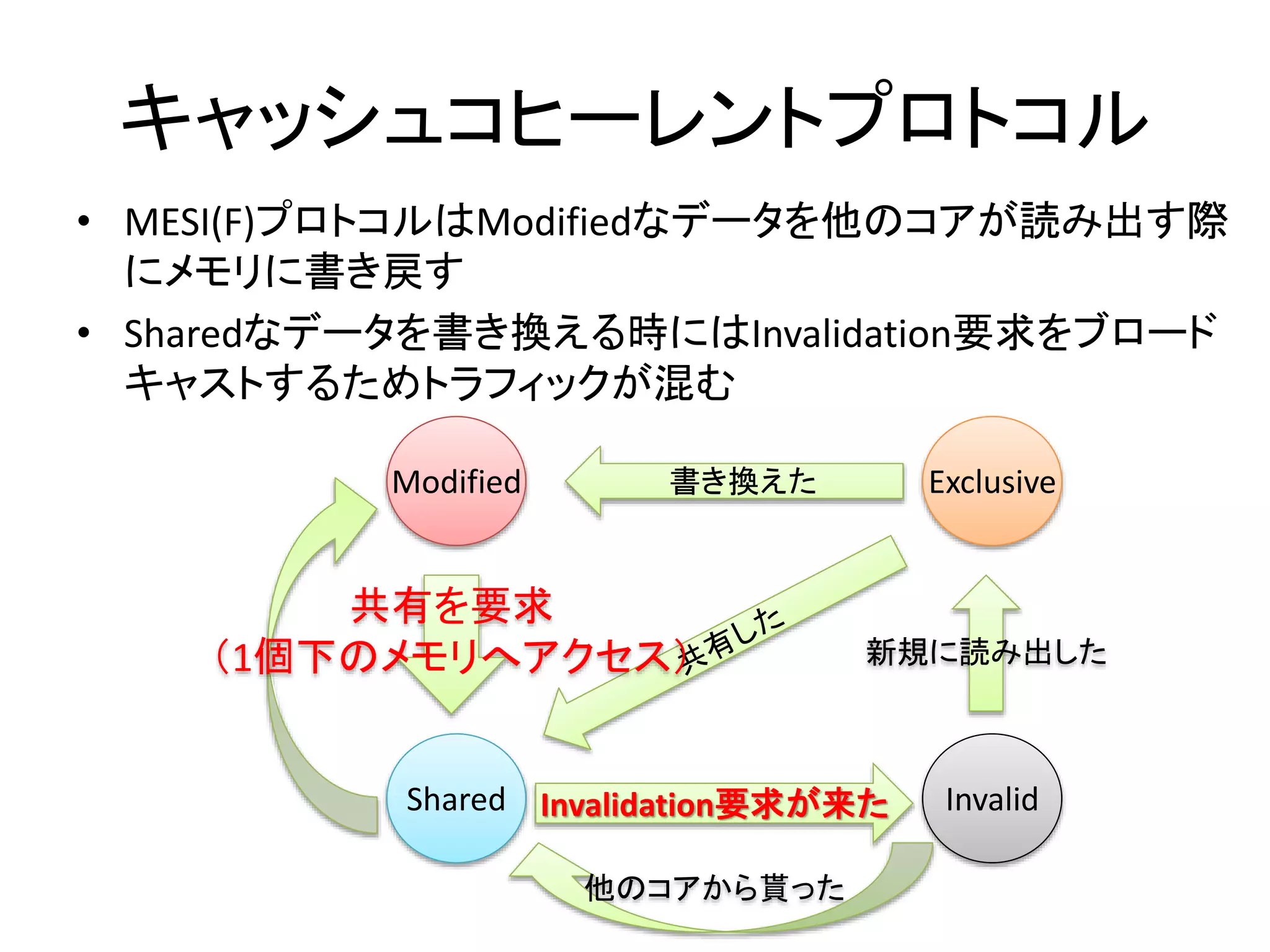
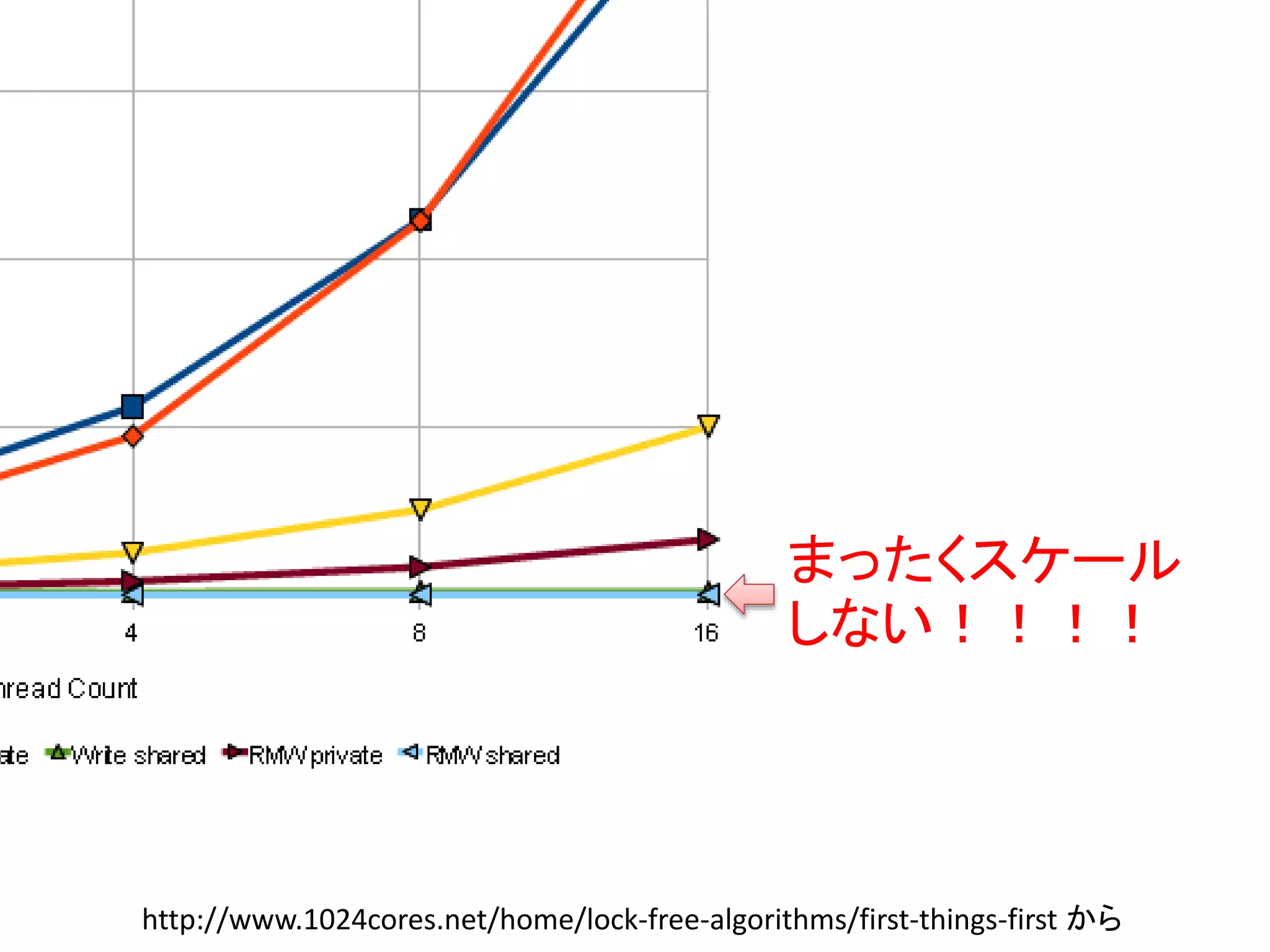
キャッシュコヒーレントプロトコル
• キャッシュラインが取る状態名の頭文字が由来
– Modified: メモリよりもキャッシュの方が新しい(書き換えた)
– Exclusive: メモリとキャッシュが同一であり、他のコアはこの
キャッシュラインを持っていない
– Shared: メモリとキャッシュが同一であり、他のコアもこの
キャッシュラインを複製している
– Invalid: 正しいキャッシュを持っていないので読むな
– Owned: 俺がメモリだ(Shared可能なModified)
– Forward: Sharedのボス。アクセスする際にはこいつに伺え
- 11.
- 12.
- 13.
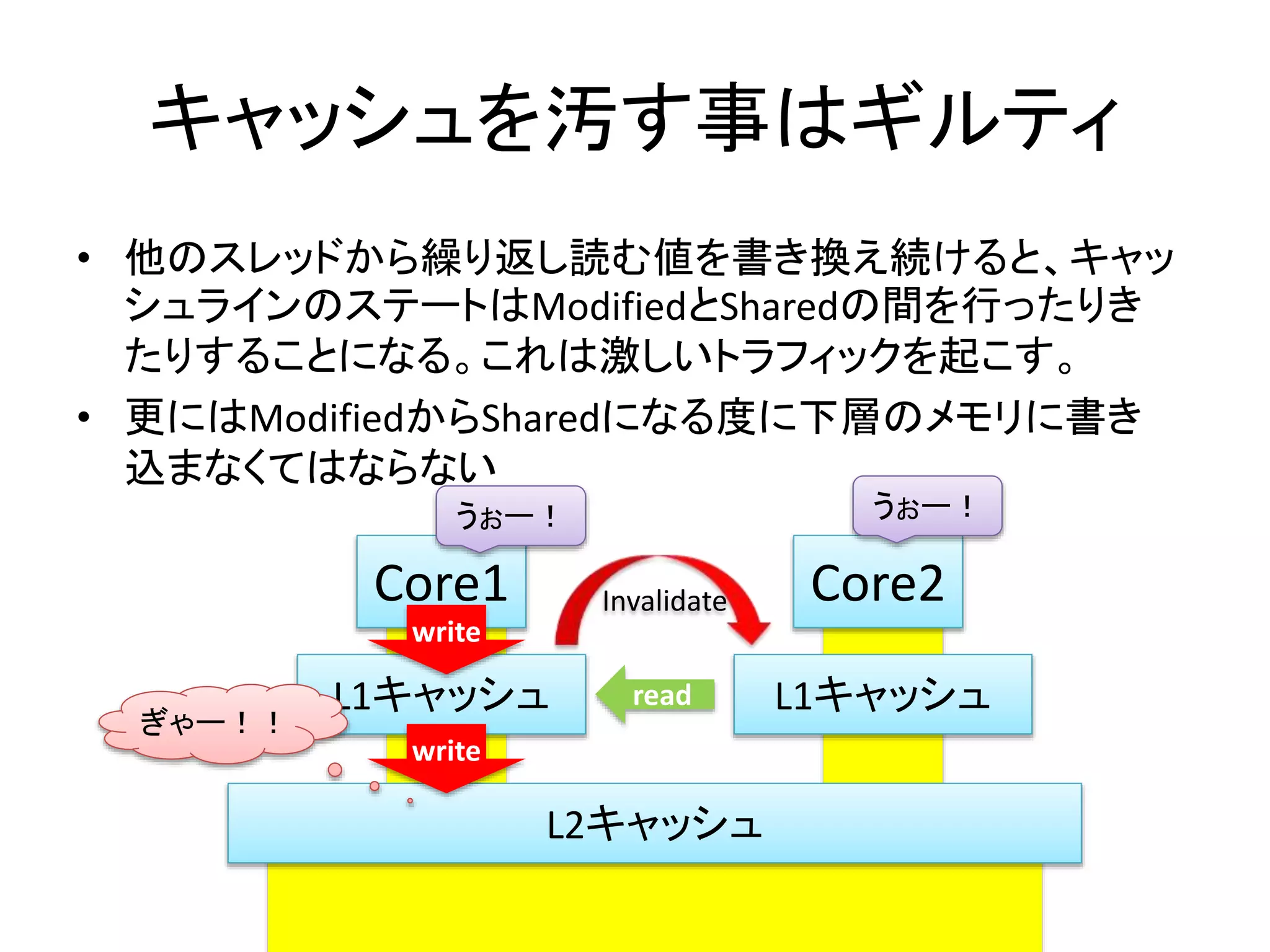
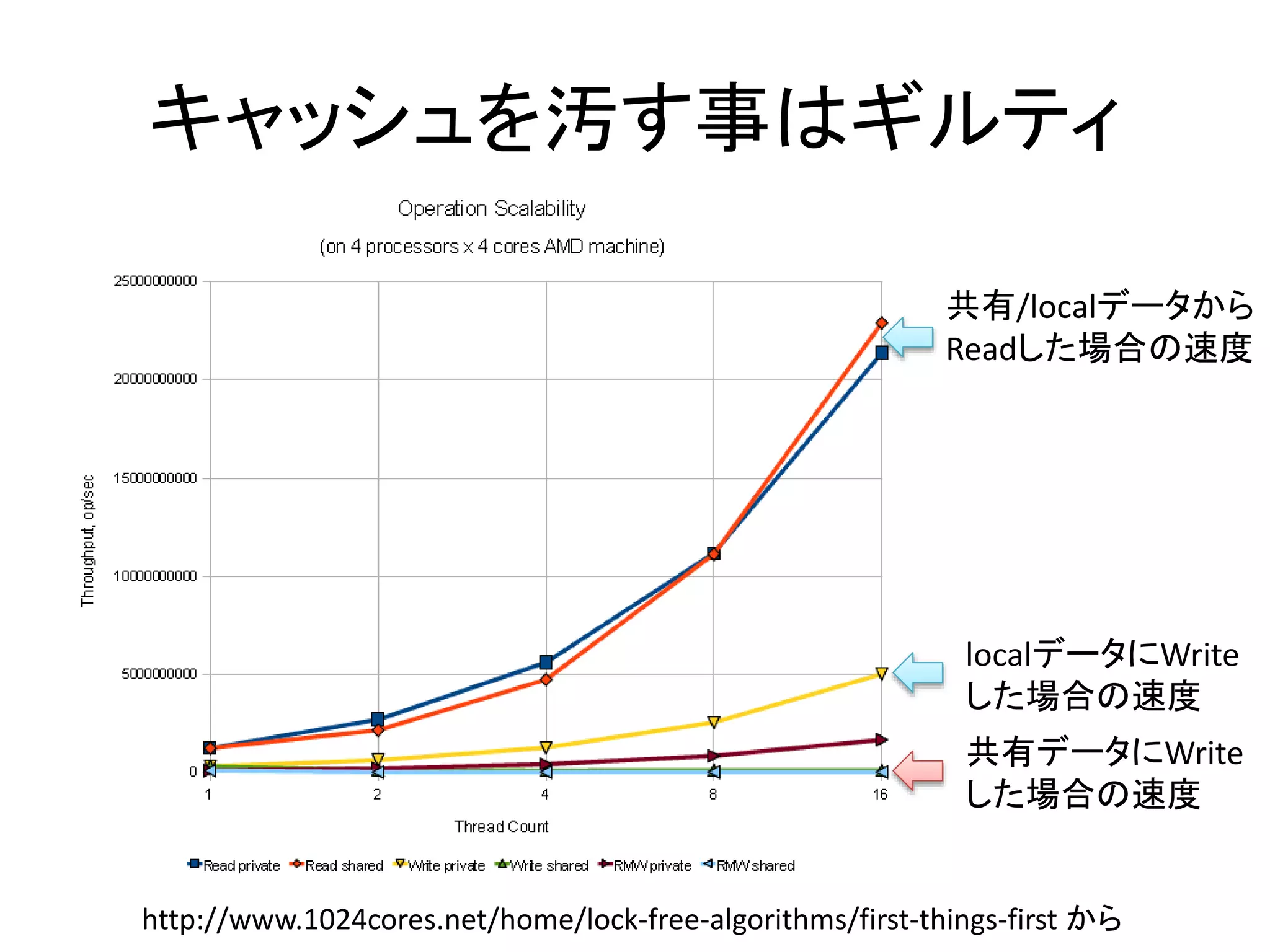
キャッシュを汚す事はギルティ
• 他のスレッドから繰り返し読む値を書き換え続けると、キャッ
シュラインのステートはModifiedとSharedの間を行ったりき
たりすることになる。これは激しいトラフィックを起こす。
• 更にはModifiedからSharedになる度に下層のメモリに書き
込まなくてはならない
うぉー! うぉー!
Core1 Core2
L1キャッシュL1キャッシュ
L2キャッシュ
write
read
ぎゃー!!
write
Invalidate
- 14.
- 15.
- 16.
- 17.
- 18.
All programmer shouldknow
• L1 キャッシュ参照......................... 0.5 ns
• 分岐予測ミス............................ 5 ns
• L2 キャッシュ参照........................... 7 ns
• Mutex lock/unlock ........................... 25 ns
• Main memory 参照...................... 100 ns
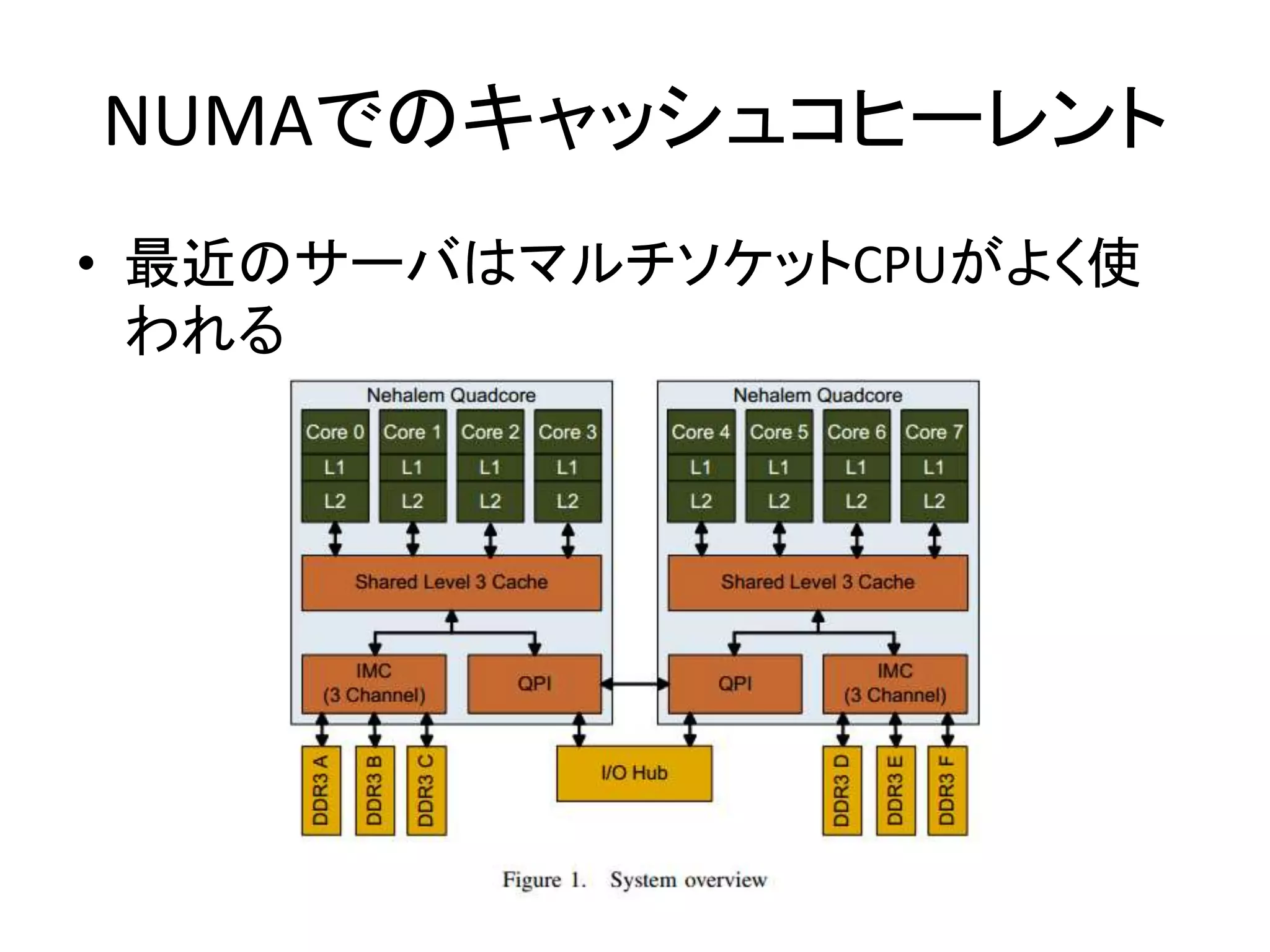
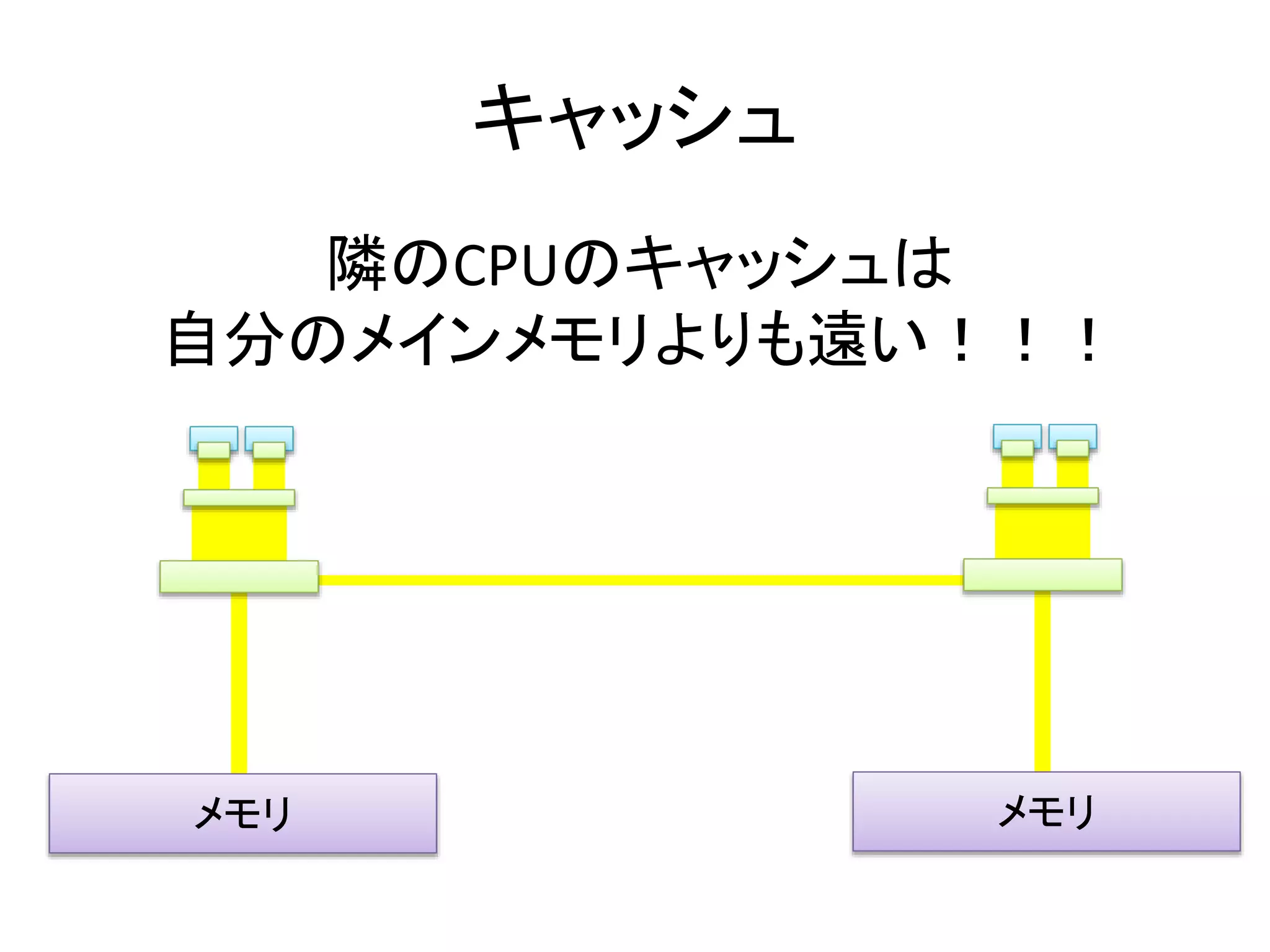
• QPI経由で隣のメモリ参照.............. 200 ns~
- 19.
- 20.
- 21.
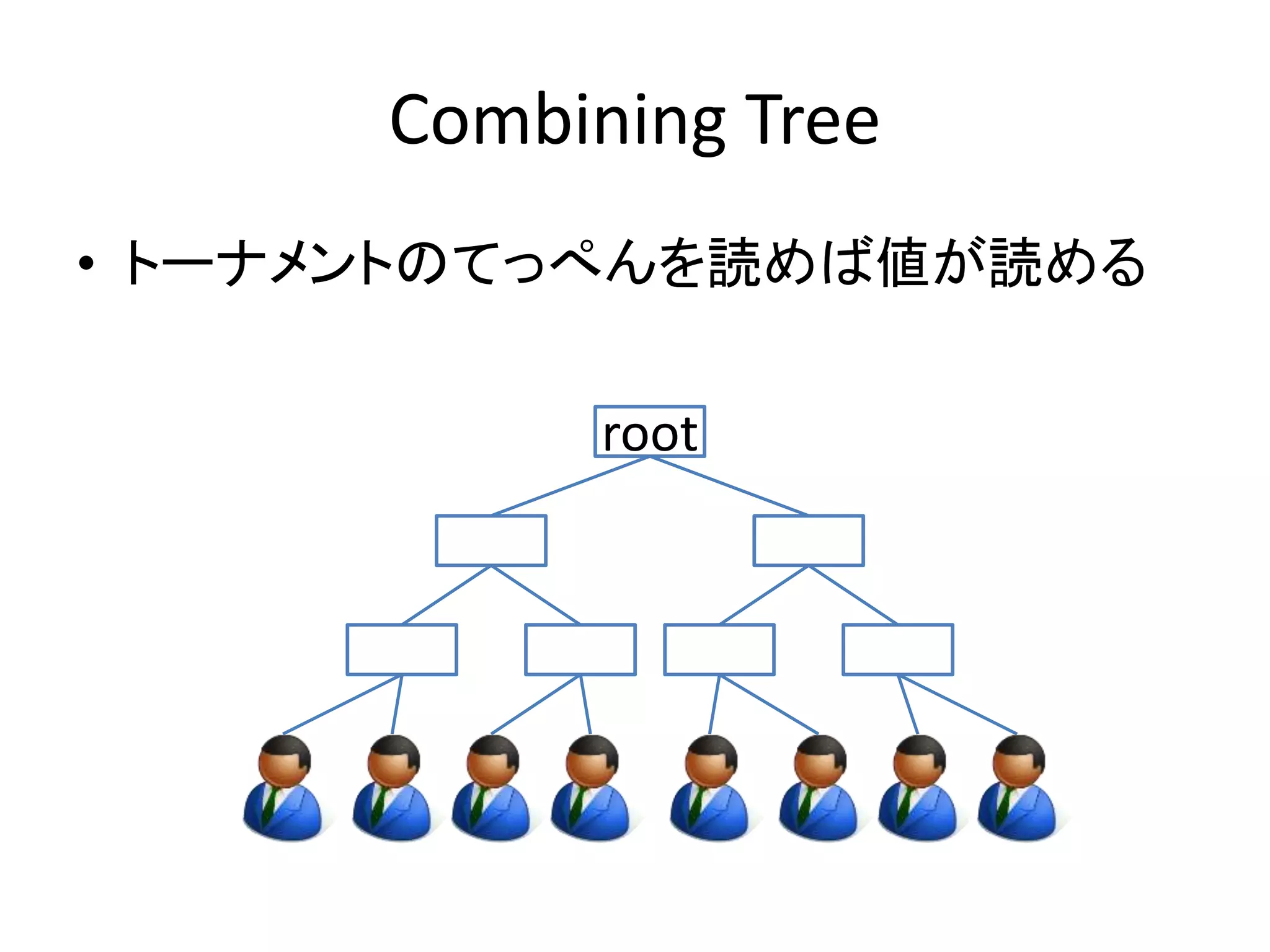
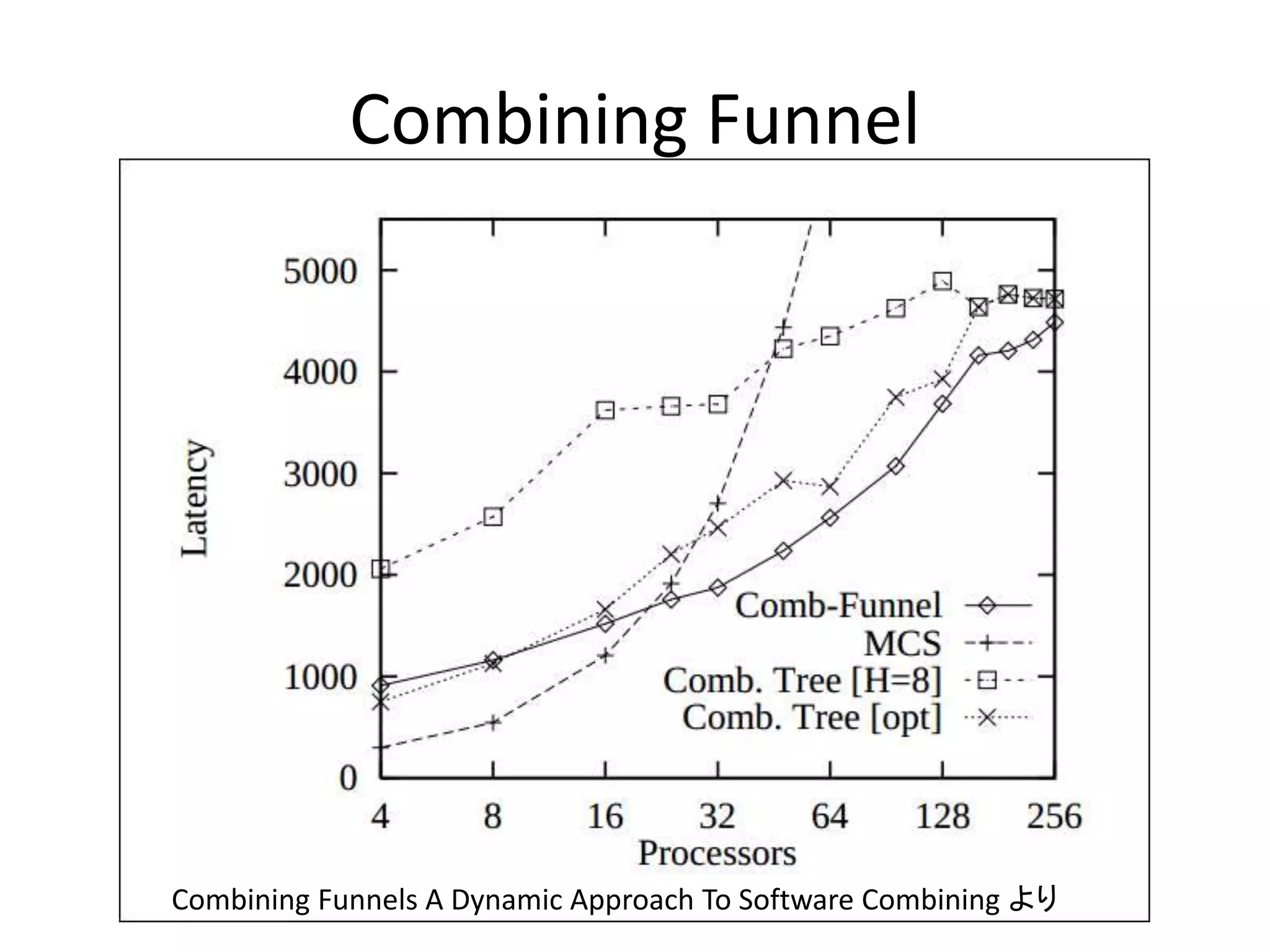
Combining Tree
•以下のインタフェースを備えるカウンタ
– add(int a):数値aを足す
– read():現在の数値を読む
• ただしスケーラブル!
擬似コード
class counter {
public:
counter() : cnt_(0) {}
void add(int a) { cnt_ += a; }
int read() const { return cnt_; }
private:
int cnt_;
};
- 22.
Combining Tree
•1つのキャッシュラインを取り合うのが2スレッ
ドまでになるようトーナメントを構成する
• トーナメントでぶつかったスレッドは、先に来
たスレッドに後に来たスレッドが値を託して待
つ
• キャッシュコヒーレントトラフィックを劇的に削
減!
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
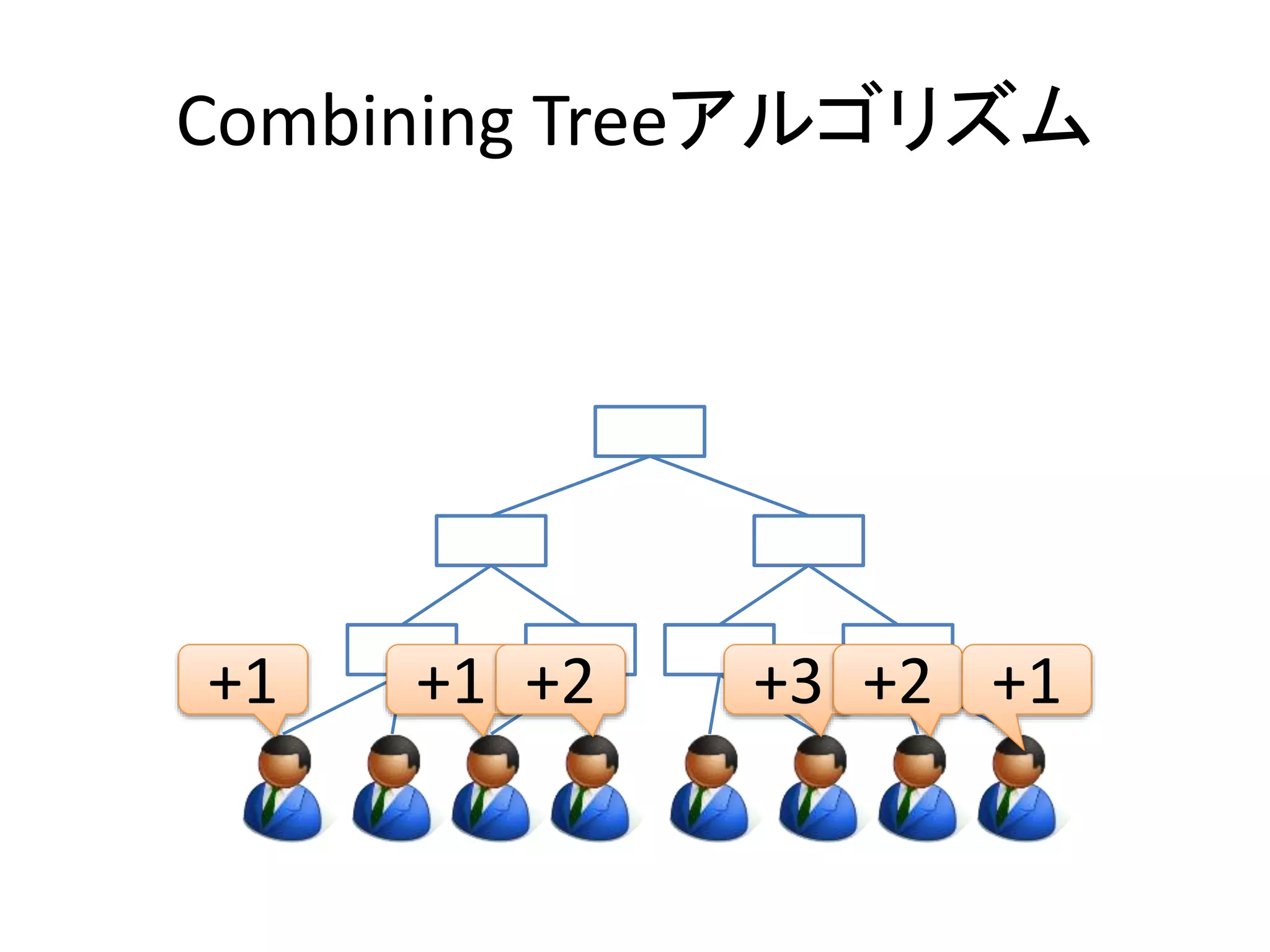
Combining Treeアルゴリズム
•結合法則を用いて計算の合成を行う
• x + 1 + 1 + 2 + 3 + 2 + 1
• x + 1 + (1 + 2) + 3 + (2 + 1)
• x + (1 + 3) + (3 + 3)
• x + (4 + 6)
• x + 10
- 30.
詳細なアルゴリズム
• 各ノードはIdle,First, Second, Rootのどれかの
状態を持つ
– Idle: どのスレッドも触ってない
– First: 最初のスレッドが既に触った
– Second: 二つ目のスレッドが触った
– Root: てっぺん(遷移しない)
• 更にノードはロックを2つ持っている
- 31.
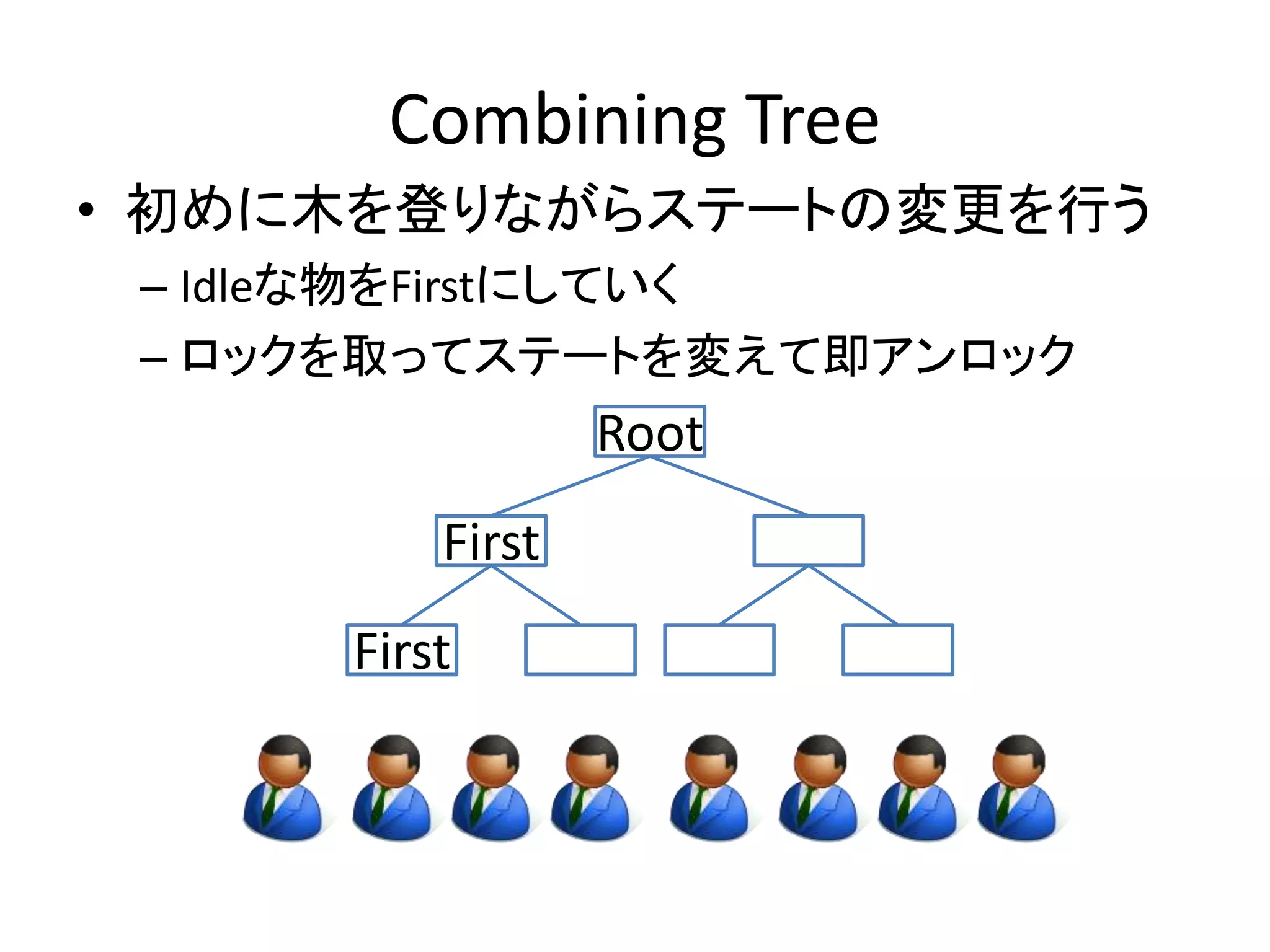
Combining Tree
•初めに木を登りながらステートの変更を行う
– Idleな物をFirstにしていく
– ロックを取ってステートを変えて即アンロック
Root
First
First
- 32.
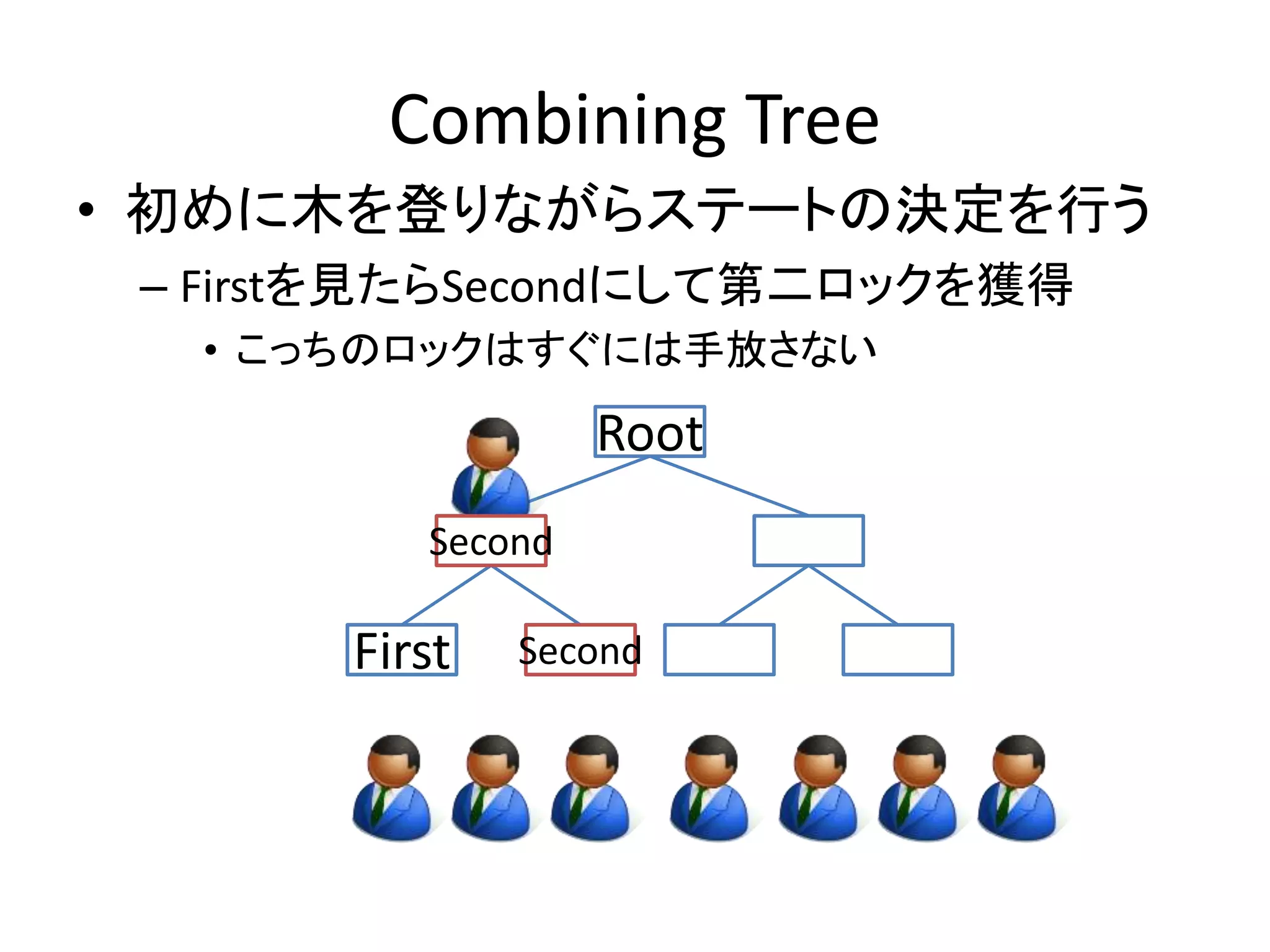
Combining Tree
•初めに木を登りながらステートの決定を行う
– Firstを見たらSecondにして第二ロックを獲得
• こっちのロックはすぐには手放さない
Root
First
Second
First First
Second
- 33.
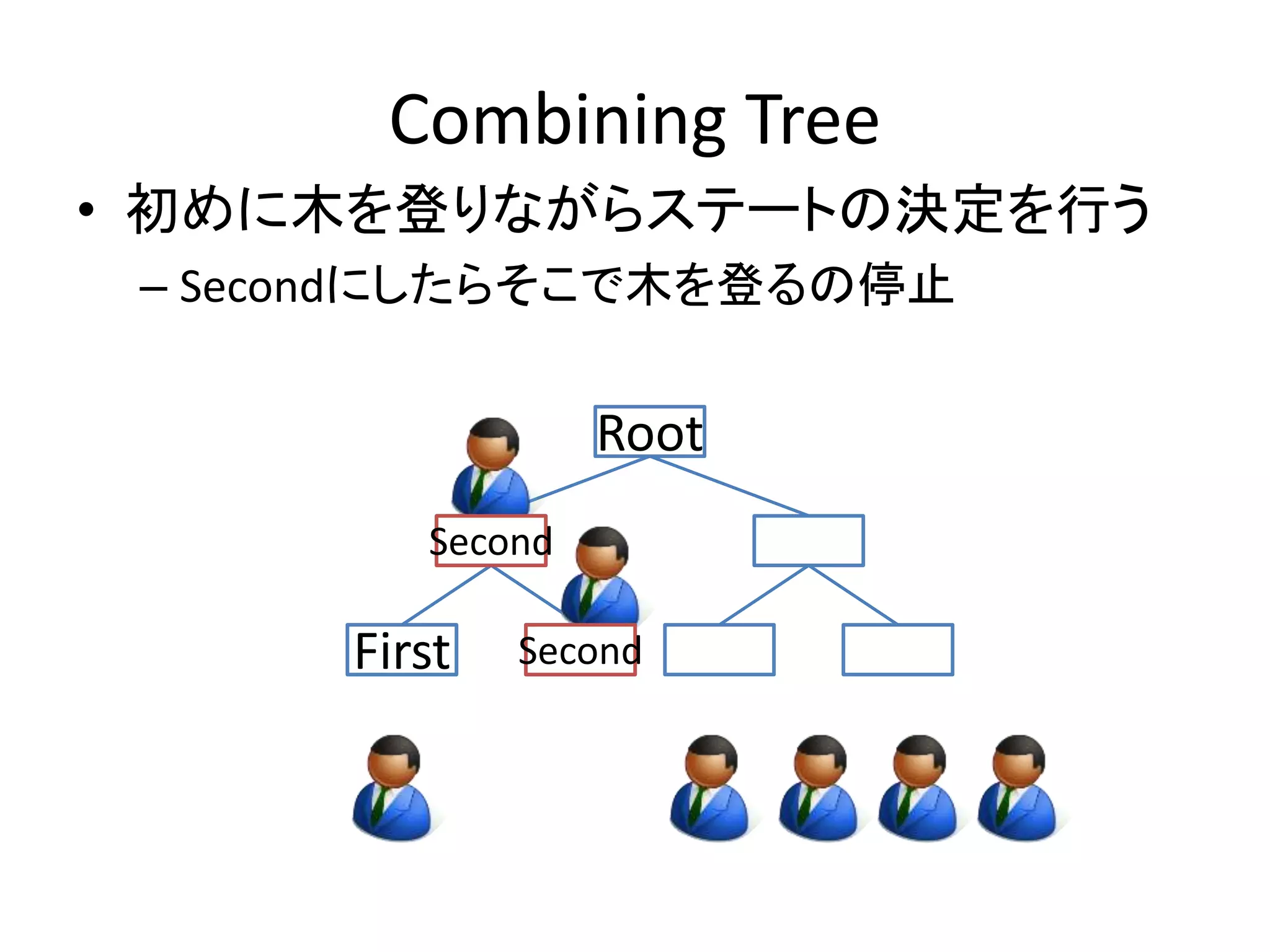
Combining Tree
•初めに木を登りながらステートの決定を行う
– Secondにしたらそこで木を登るの停止
Root
First
Second
First
Second
- 34.
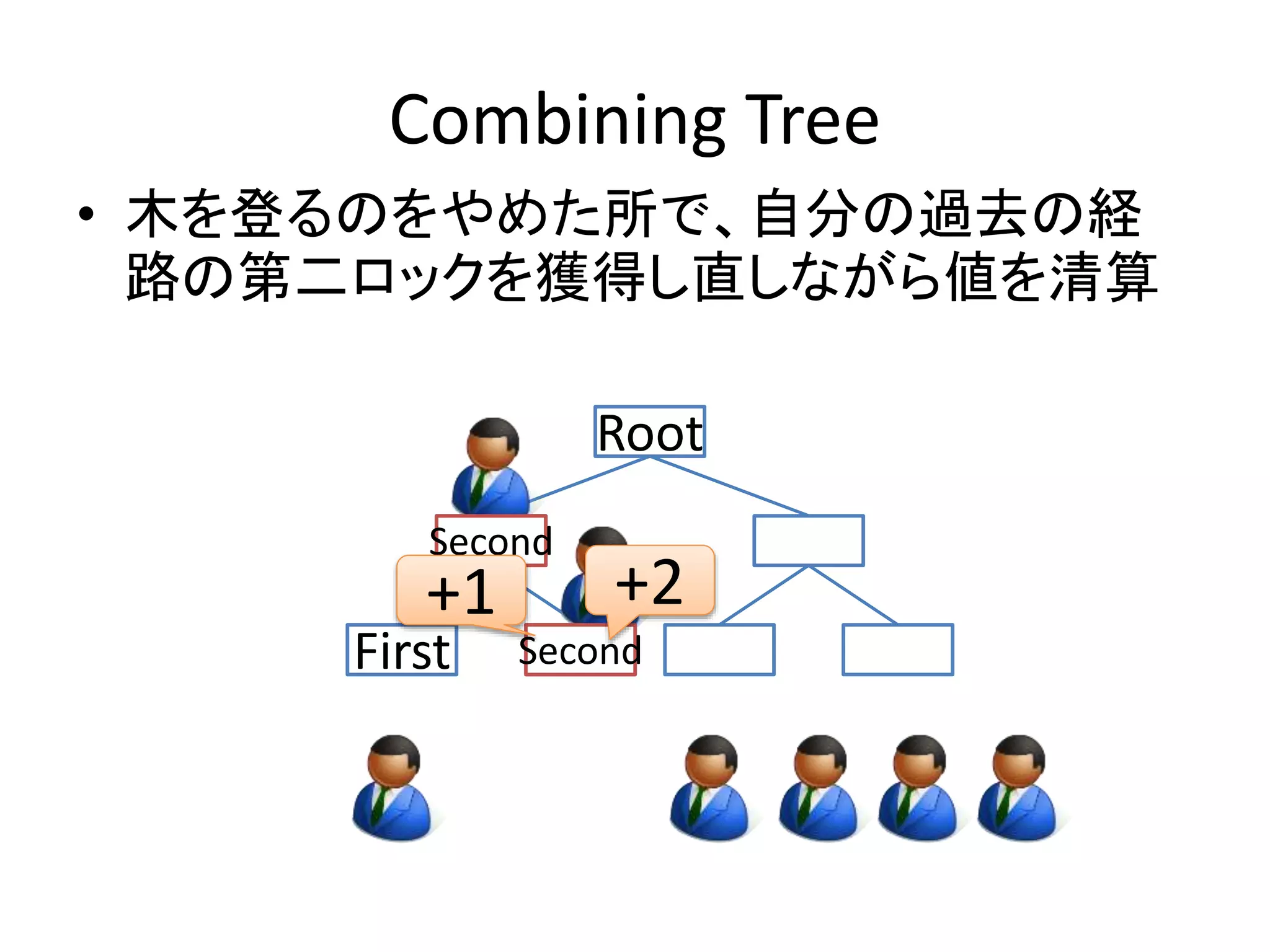
Combining Tree
•木を登るのをやめた所で、自分の過去の経
路の第二ロックを獲得し直しながら値を清算
Root
First
Second
First
Second
- 35.
Combining Tree
•木を登るのをやめた所で、自分の過去の経
路の第二ロックを獲得し直しながら値を清算
Root
First
Second
+1 +2
First
Second
- 36.
Combining Tree
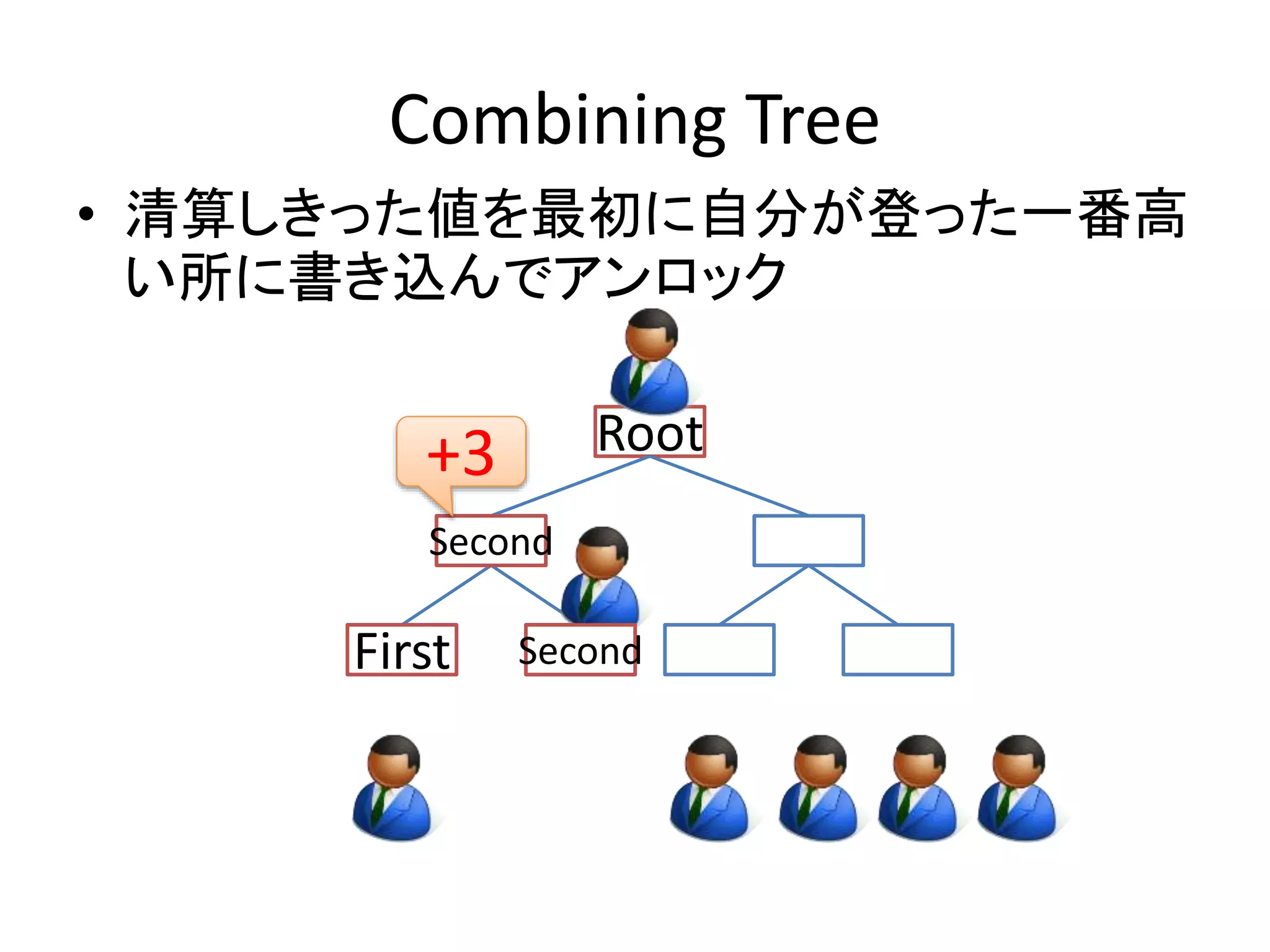
•清算しきった値を最初に自分が登った一番高
い所に書き込んでアンロックするのが基本戦
略
Root
First
Second
First
+3
Second
- 37.
Combining Tree
•清算しきった値を最初に自分が登った一番高
い所に書き込んでアンロック
Root
+3
SFeicrosntd
Second
Second
First
- 38.
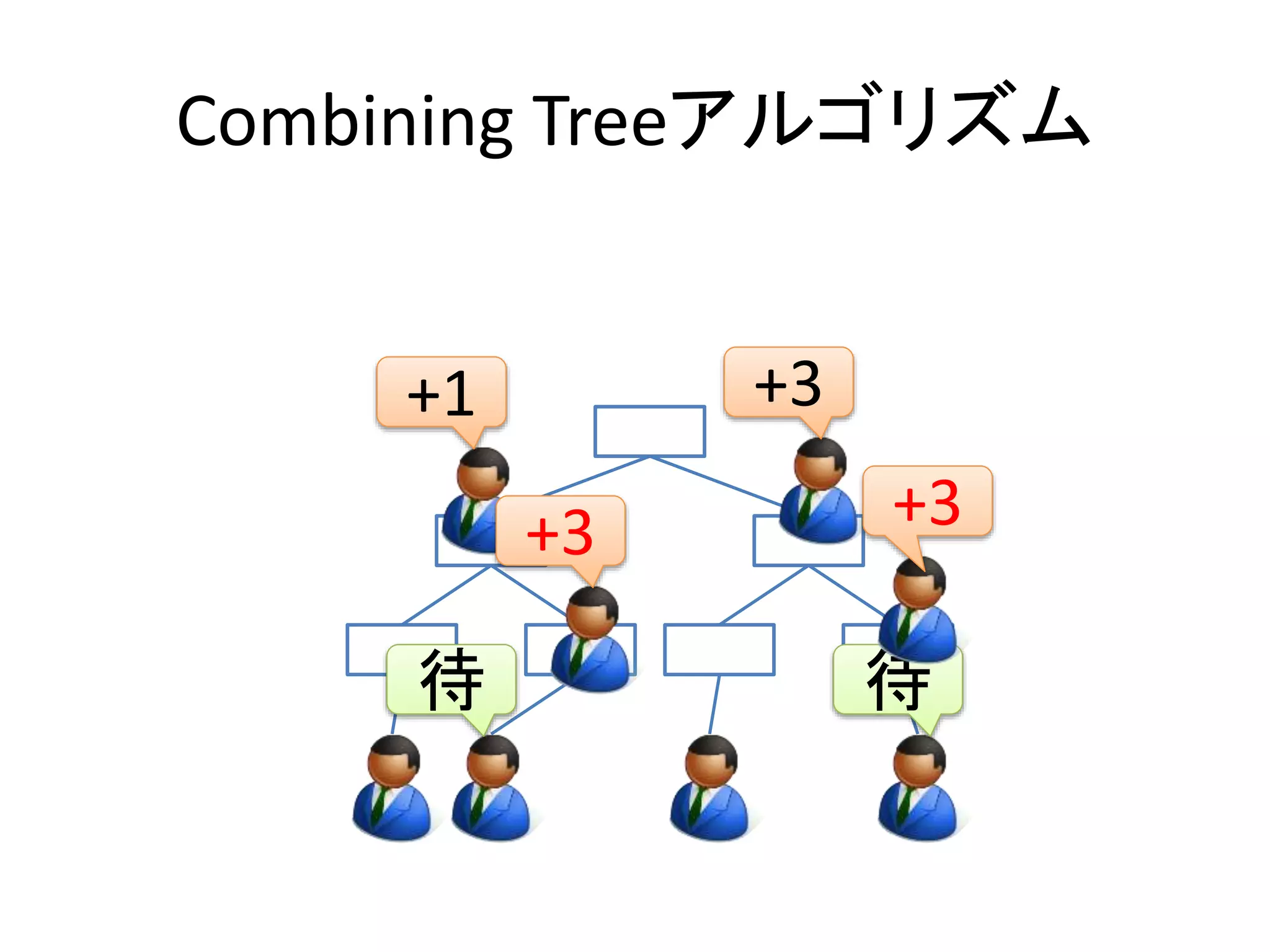
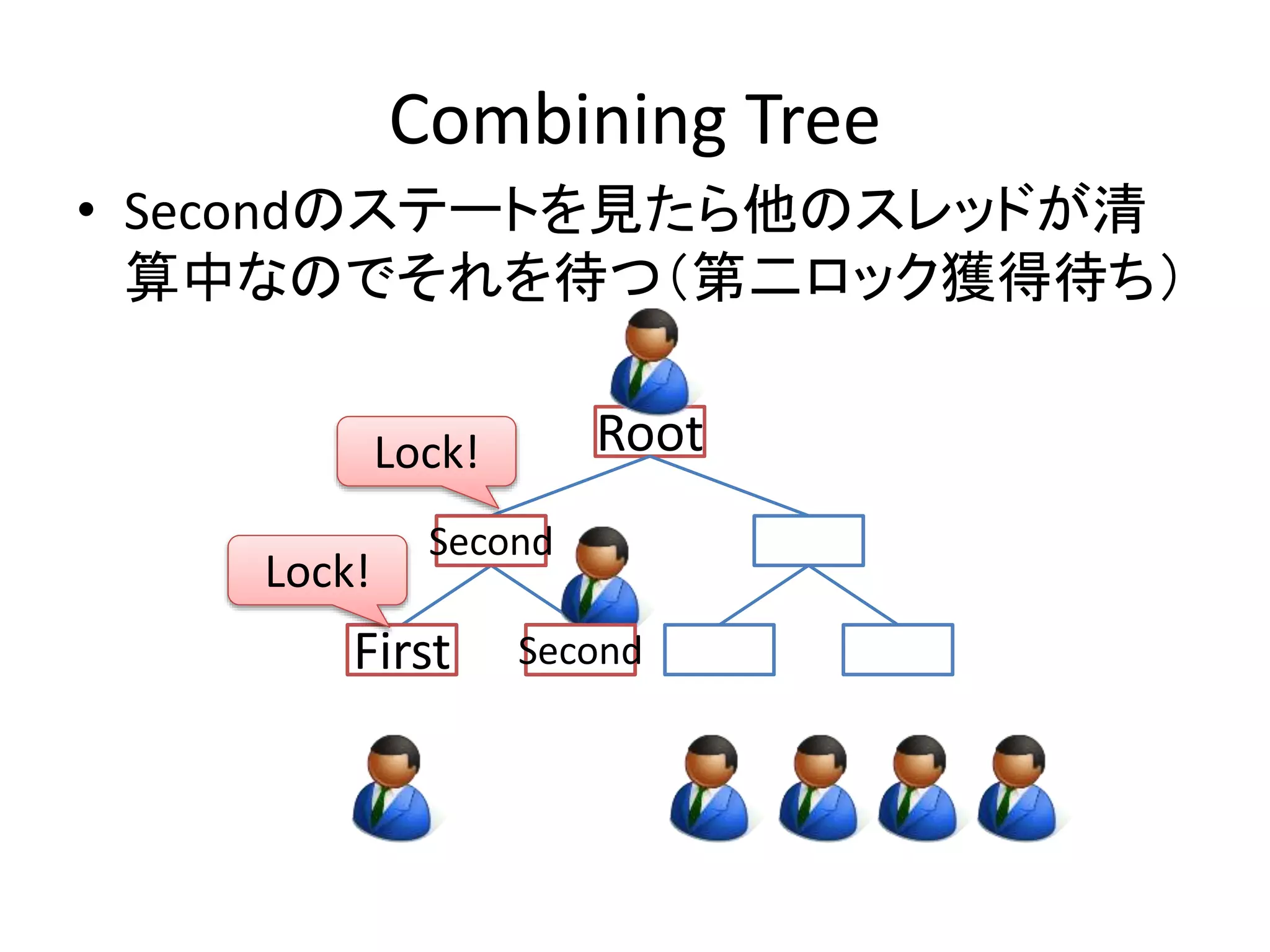
Combining Tree
•Secondのステートを見たら他のスレッドが清
算中なのでそれを待つ(第二ロック獲得待ち)
Root
Lock!
SFeicrosntd
Second
Second
Lock!
First
- 39.
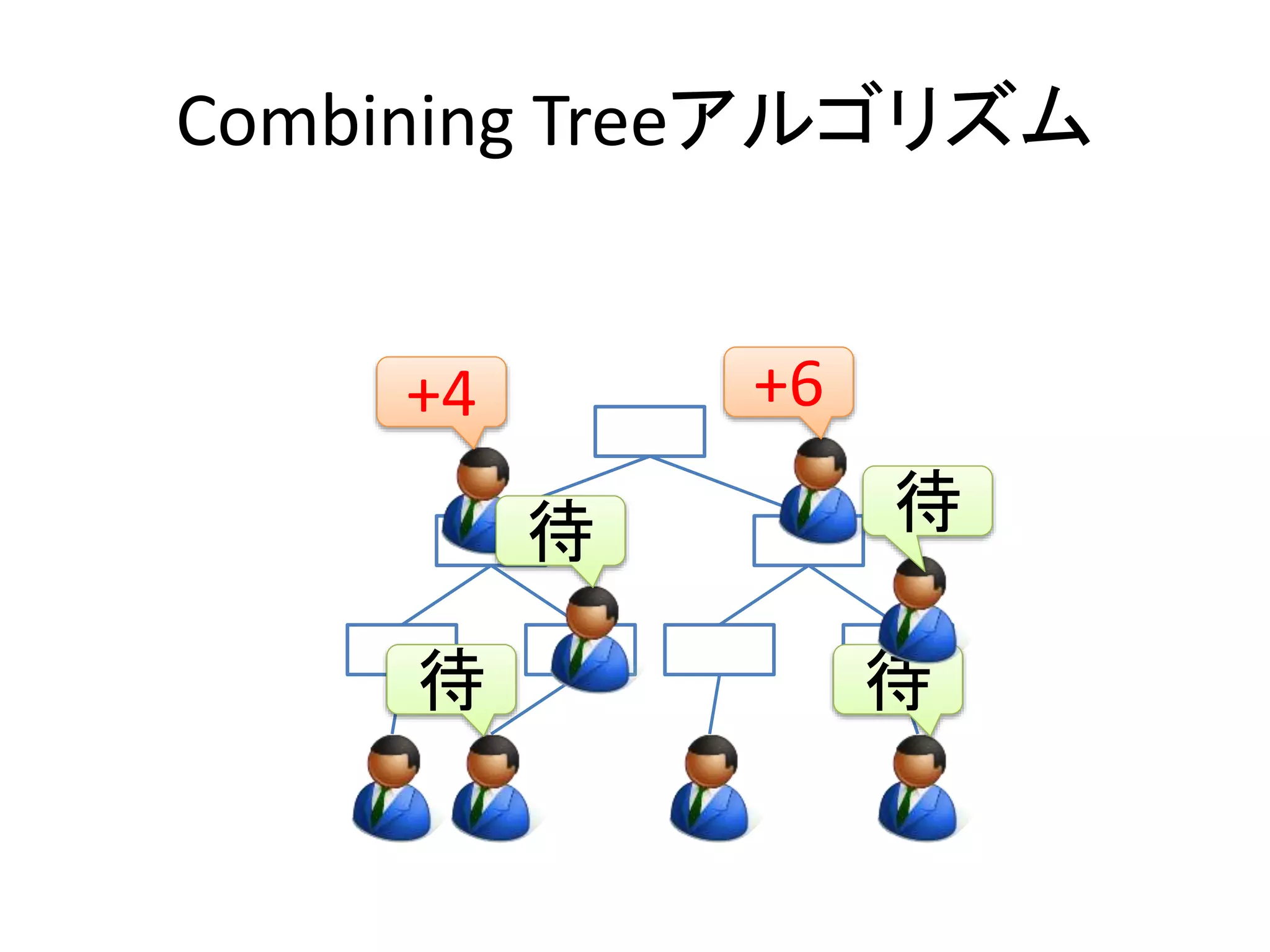
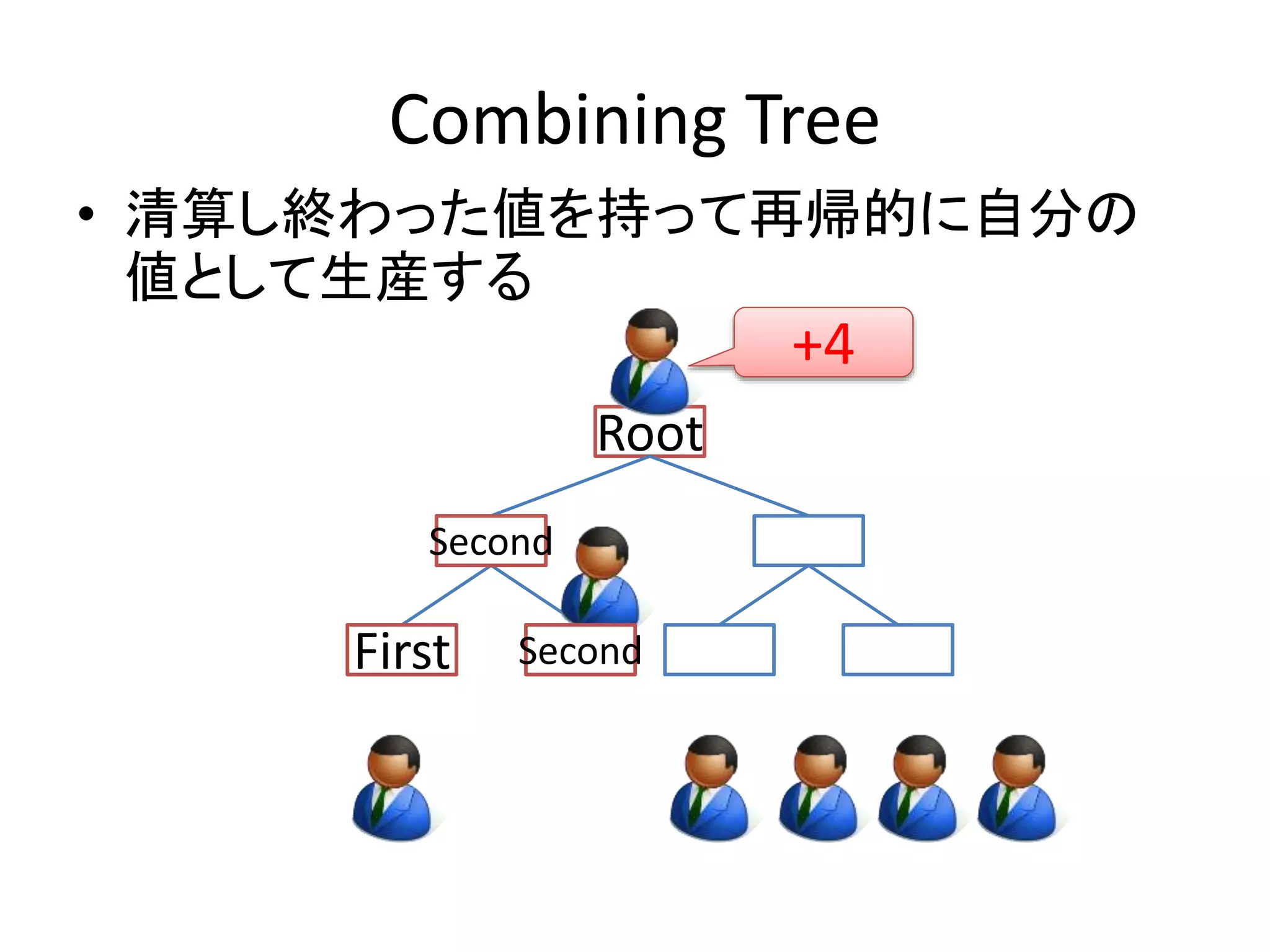
Combining Tree
•清算し終わった値を持って再帰的に自分の
値として生産する
Root
SFeicrosntd
Second
Second
First
+4
- 40.
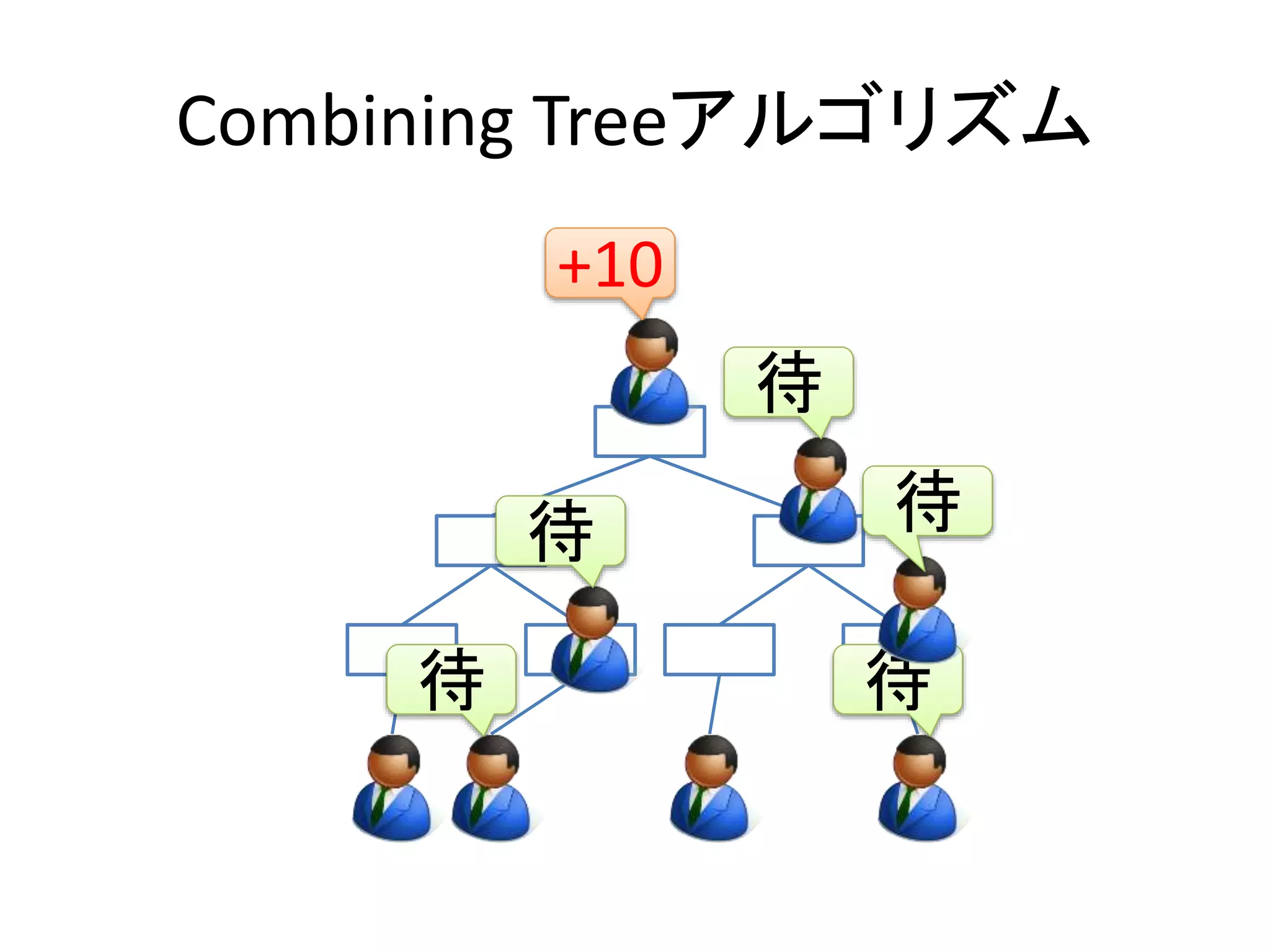
Combining Tree
•平均して木の深さnに対して2*n回のロックと
アンロックを使うことになる
– 大丈夫なの・・・?
• Mutex lock/unlock ........................... 25 ns
• QPI経由で隣のメモリ参照.............. 200 ns~
キャッシュ衝突のペナルティを
考えると余裕でペイする
- 41.
Combining Tree
•衝突がない場合でも2*n回のロック・アンロッ
ク
• レイテンシという点において非常に悪い
– 改良として1ノードに3スレッド以上ぶら下げて木
の深さを減らすパターンもあるが、複雑さがマッ
ハでレイテンシはむしろ悪化
- 42.
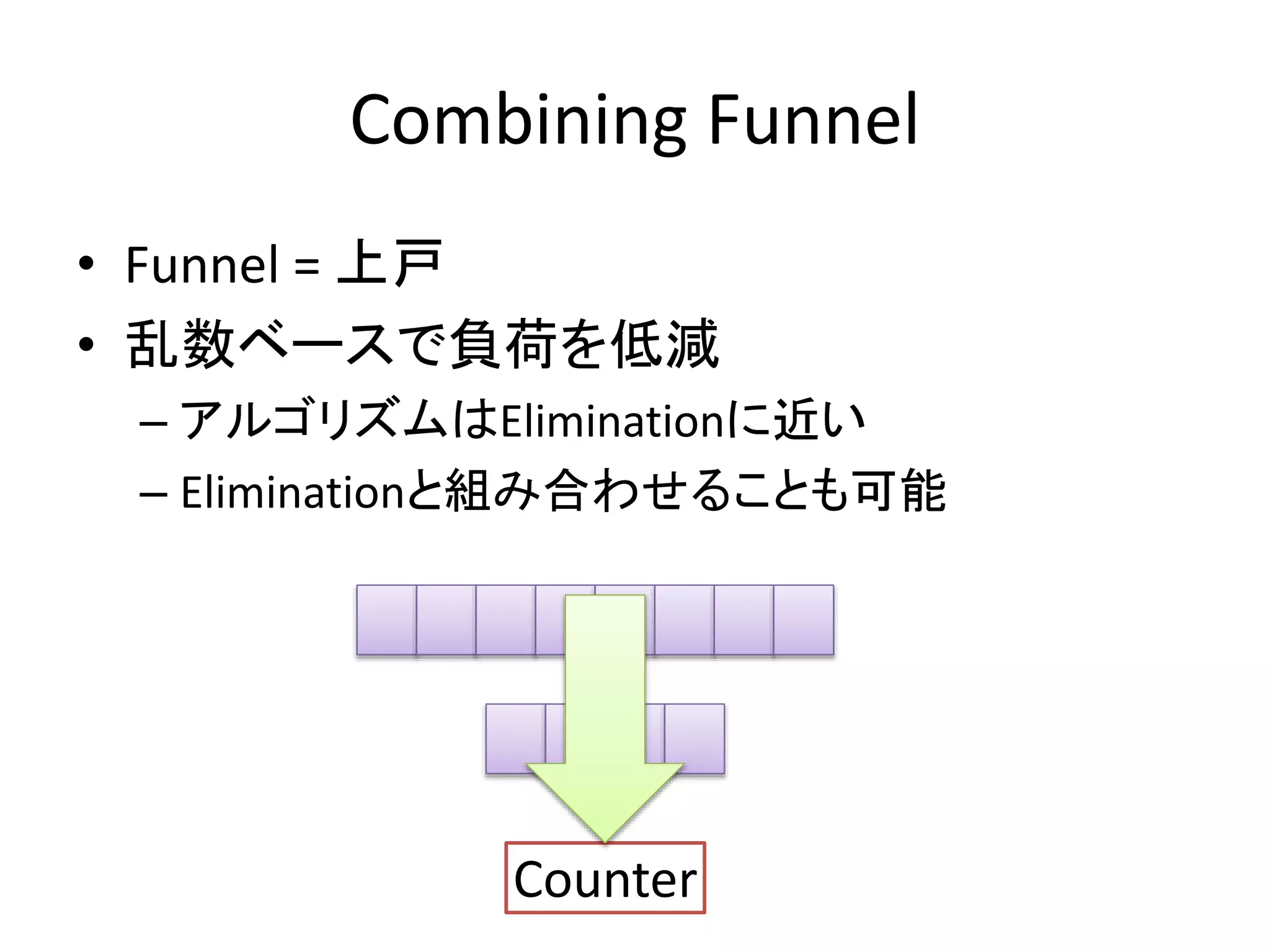
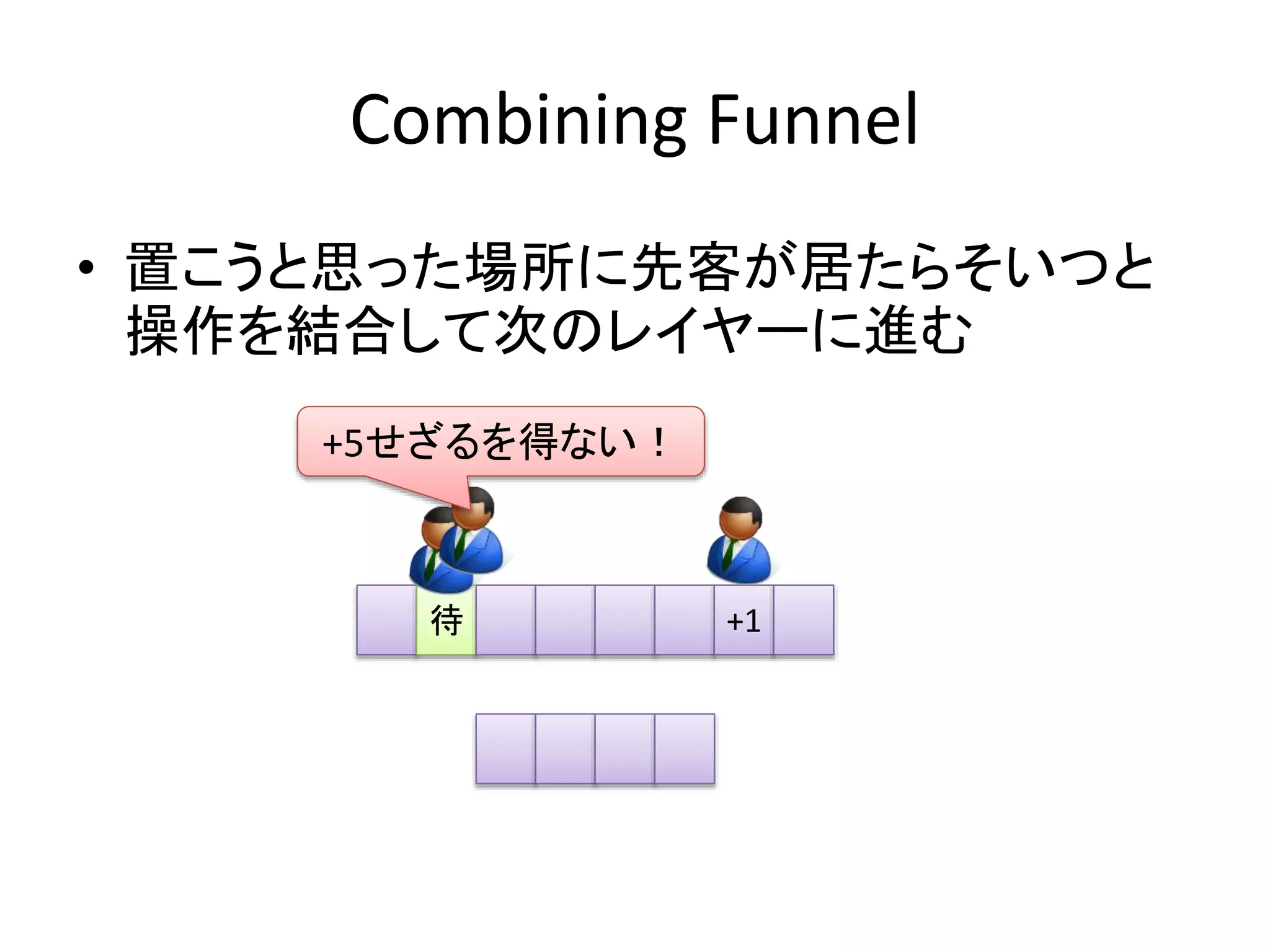
Combining Funnel
•Funnel = 上戸
• 乱数ベースで負荷を低減
– アルゴリズムはEliminationに近い
– Eliminationと組み合わせることも可能
Counter
- 43.
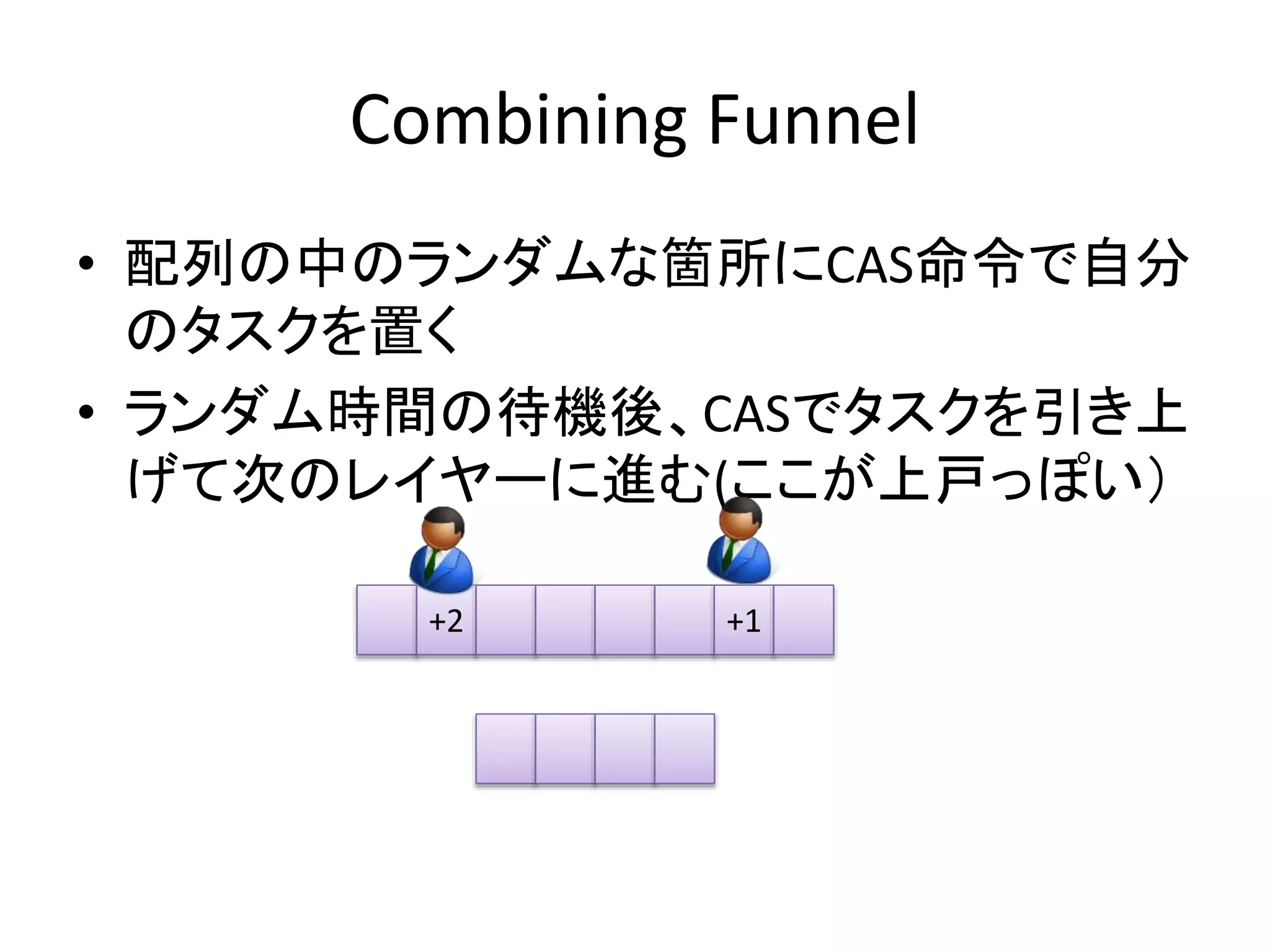
Combining Funnel
•配列の中のランダムな箇所にCAS命令で自分
のタスクを置く
• ランダム時間の待機後、CASでタスクを引き上
げて次のレイヤーに進む(ここが上戸っぽい)
+2 +1
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
SNZI
• 数を数えようとするから残念なことになるん
や!諦めろ!
– ゼロかどうか分かればええ!
• Scalable-Non-Zero-Indicatorの略でSNZI
– pronounced "snazzy" : (和訳)粋な、おしゃれな、
優雅な、エレガントな、格好いい
- 50.
SNZIのセマンティクス
• 数字が読めないカウンタ
• これをスケーラブルにする
擬似コード
class snzi {
public:
counter() : cnt_(0) {}
void inc() { cnt_ += 1; }
void dec() { cnt_ -= 1; }
bool is_zero() const {
return cnt_ == 0;
}
private:
int cnt_;
};
- 51.
- 52.
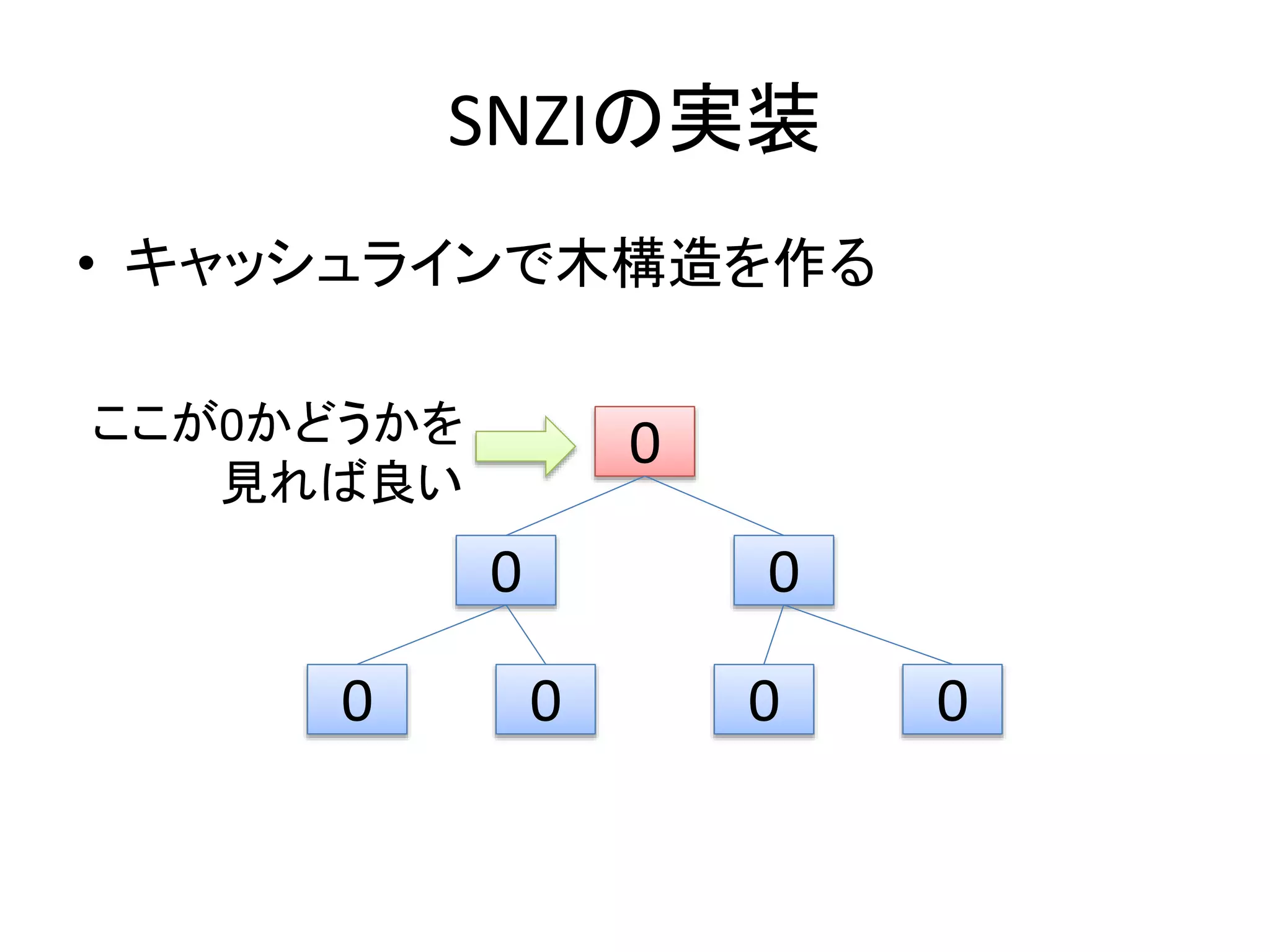
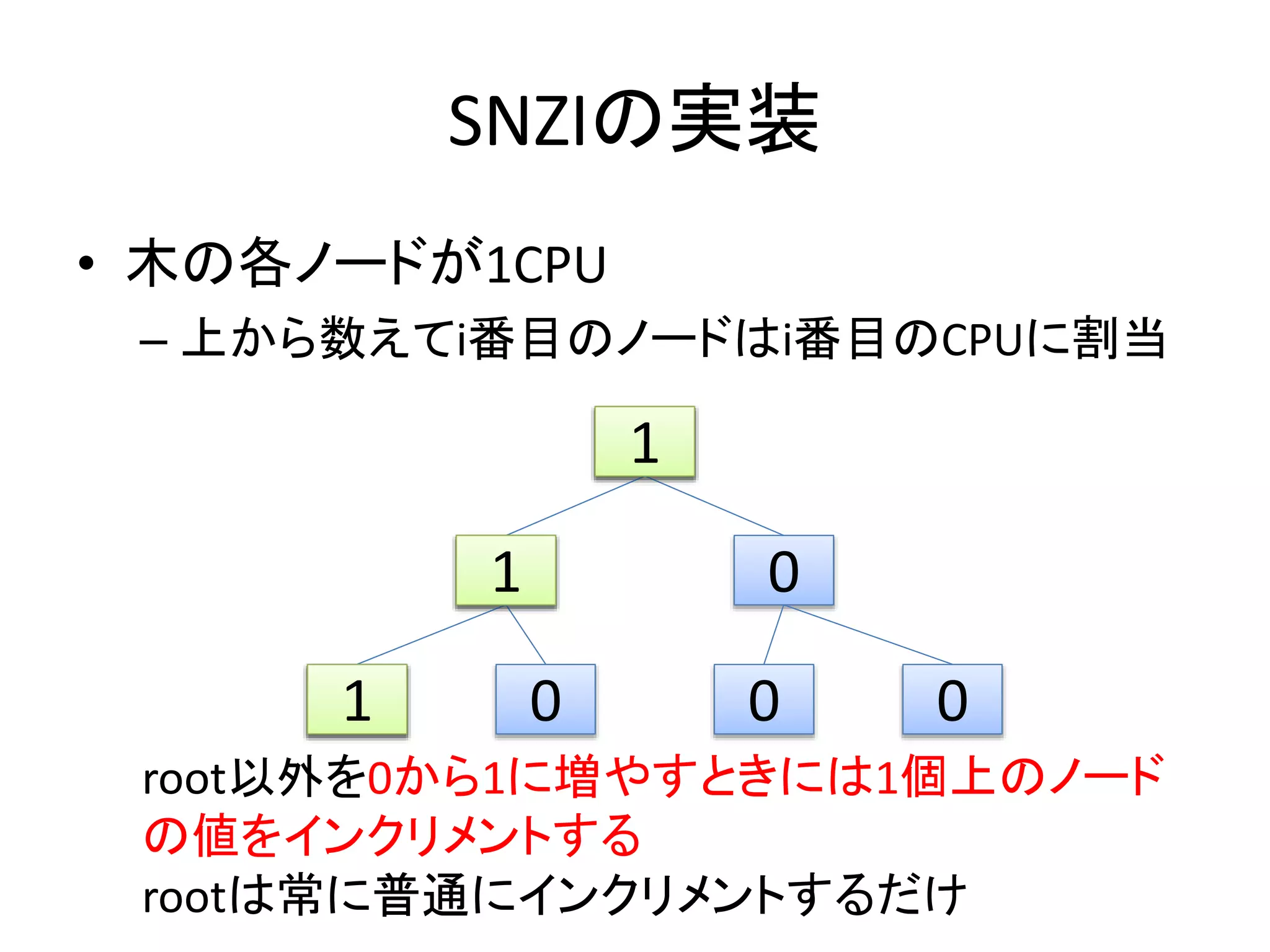
SNZIの実装
• 木の各ノードが1CPU
– 上から数えてi番目のノードはi番目のCPUに割当
0
1
0 1
0
01 0 0 0
root以外を0から1に増やすときには1個上のノード
の値をインクリメントする
rootは常に普通にインクリメントするだけ
- 53.
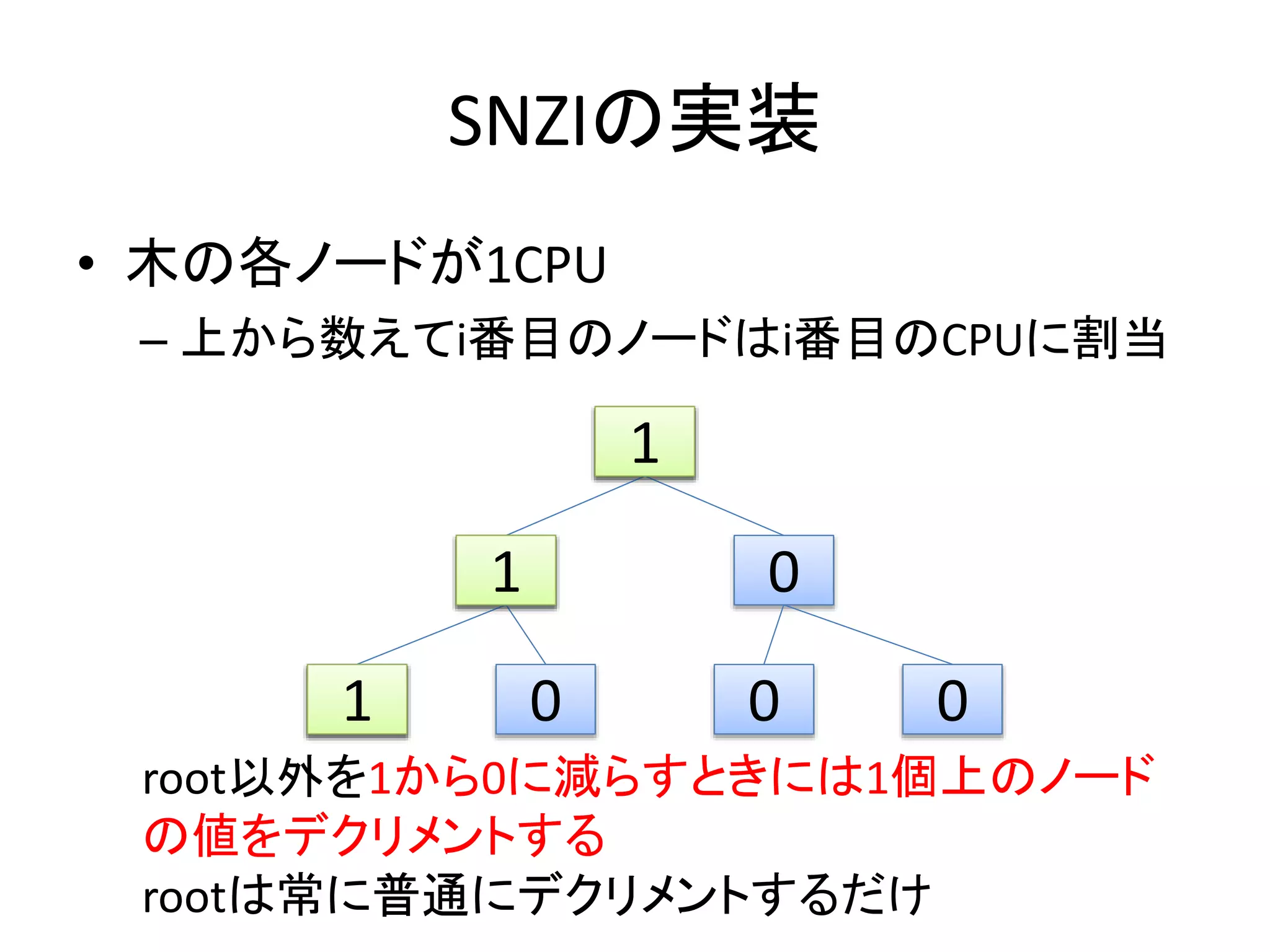
SNZIの実装
• 木の各ノードが1CPU
– 上から数えてi番目のノードはi番目のCPUに割当
0
1
0 1
0
01 0 0 0
root以外を1から0に減らすときには1個上のノード
の値をデクリメントする
rootは常に普通にデクリメントするだけ
- 54.
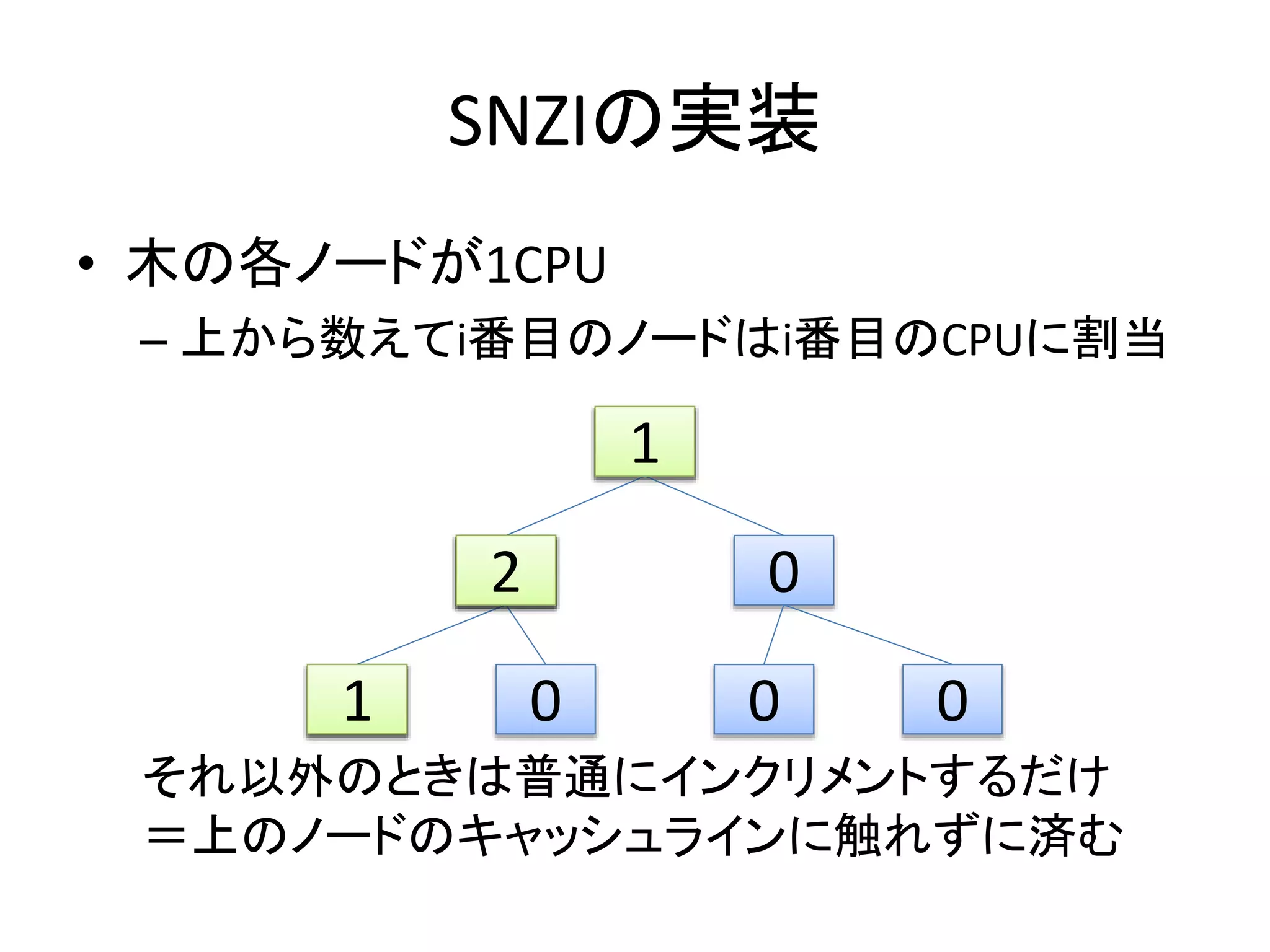
SNZIの実装
• 木の各ノードが1CPU
– 上から数えてi番目のノードはi番目のCPUに割当
0
1
0 2
1
0
01 0 0 0
それ以外のときは普通にインクリメントするだけ
=上のノードのキャッシュラインに触れずに済む
- 55.
- 56.
- 57.
SNZIの実装
• 厳密には複数のスレッドが同一のノードにア
クセスしに来た際に0⇔1周りで細かい調停が
必要
0から1のときは、先に自分の箇所の値を1/2という値にしてから上のノードをインクリメン
トしにいき、そのあとで1/2を1にCASを試みる。もし上のノードのインクリメントに成功した
後に1/2→1のCASに失敗したら上のノードをデクリメントしておく
• デクリメントの数はその前に行われたインクリ
メントの数を越えては行けない(Read-Write
ロックなどに用いるには充分)
- 58.
- 59.
- 60.
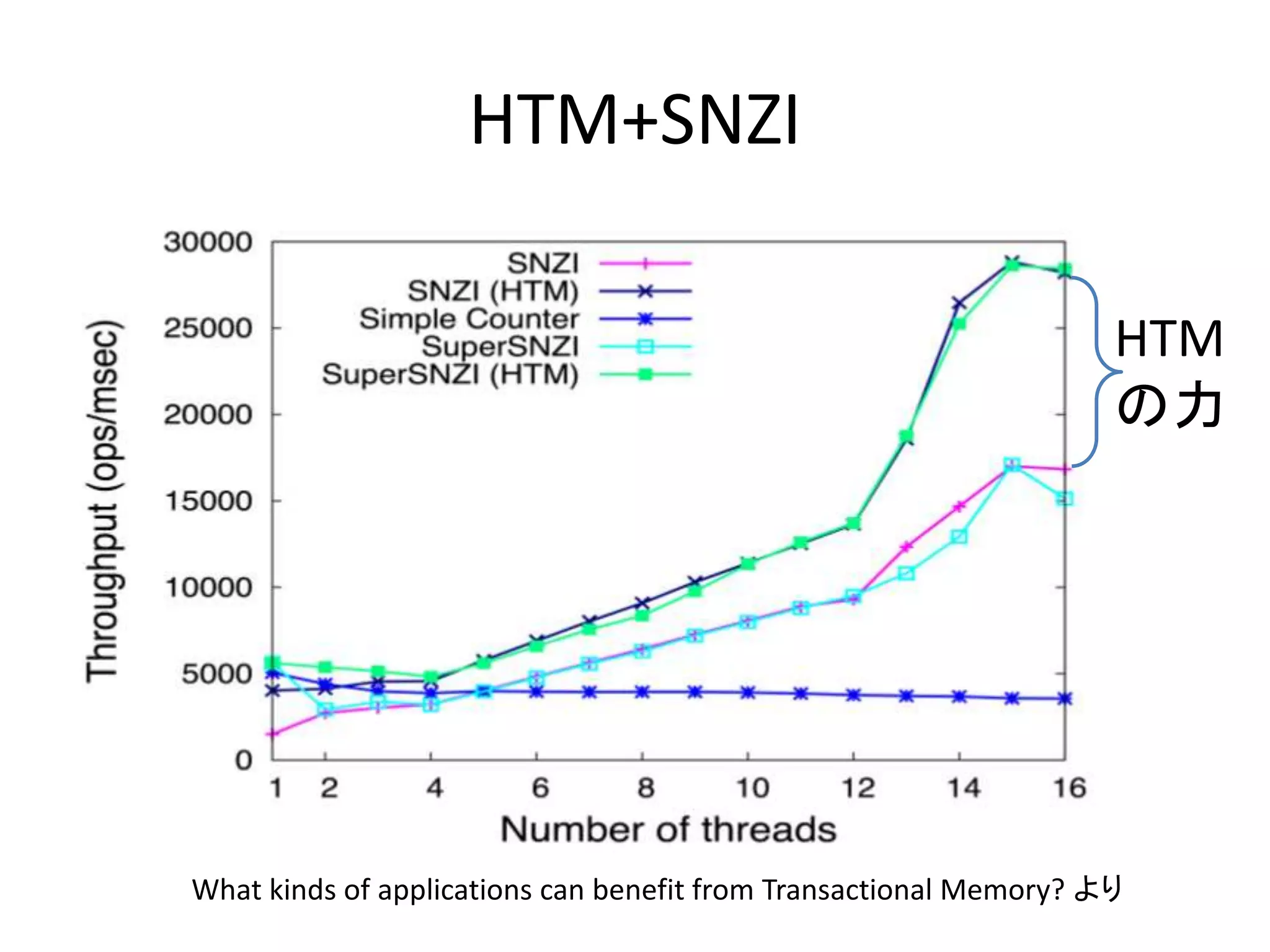
HTM+SNZI
HTM
の力
What kinds of applications can benefit from Transactional Memory? より