Big Social Data
2.9. 2015 Josef Šlerka, malá doktorandská obhajoba
Ústav informačních studií a knihovnictví
3.
Obsah
1. Nová médiaa sociální média
2. Data a Big Data
3. Big Social Data jako nové pole výzkumu
4. Social Network Analysis
5. Normalized Information Distance a jeho aplikace
6. Normalized Social Distance - vlastní výzkum
7. Případové studie
Nová média
V běžnémdiskursu se můžeme setkat s označením
nová média jako se synonymem pro internet, mobilní
telefony či herní konzole. (…) V obecnější rovině jsou
tyto technologické artefakty spojeny s koncepty
“digitálnosti, interaktivity, hypertexuality, virtuality,
síťovosti a simultánnosti.”
(LISTNER, M. a kol.: New Media: a critical
introduction. Routledge 2009, str. 13)
7.
Nová média
Digitálností jetřeba rozumět číselnou, digitální
reprezentaci informací, která přináší nejen
dematerializaci existence artefaktů, ale také umožňuje
samotnou komunikaci a práci zprostředkovanou
pomocí počítačů (například v internetové síti).
Interaktivnost představuje možnost postoupit od
pasivní recepce k zapojení diváka či čtenáře.
8.
Nová média
Hypertextualita odkazujek provázání textů mezi sebou
a především k nelinearnímu čtení.
Virtualita pak znamená vytváření digitálních prostředí,
která umožňují různé typy teleprezence.
Síťovostí a simultánností se rozumí nejen nástup
internetu, ale celkové uspořádání procesů ve
společnosti.
9.
Nová média
toto vymezeníje deskriptivní
obsahuje prvky, které nejsou nutnou podmínkou
(interkativita a pod.)
neposkytují dostatečné vymezení proti “starým”
mediím
10.
Manovich
Nabízí se tupřístup amerického teoretika ruského
původu Lva Manoviche. Ten ve své knize The
Language of New Media z roku 2001 charakterizuje
nová média pomocí pěti základních atributů, které mají
úzkou souvislost s informační vědou.
11.
Manovich
1. Princip číselnéreprezentace - Což znamená, že
každé “Novomediální dílo může být vymezeno
formálně, matematicky. Například obraz nebo tvar lze
popsat matematickou funkcí,” a z čehož vyplývá, že
“Novomediální dílo je předmětem algoritmické
manipulace. Uplatněním vhodného algoritmu můžeme
například automaticky odstranit zrnitost z fotografie,
vylepšit její kontrast, rozpoznat tvary nebo změnit
proporce. Řečeno ve zkratce, média se stávají
programovatelnými.”
12.
Manovich
2. Princip modularity,kterou Manovich popisuje
takto: "Jednotlivé prvky médií, obrazy, zvuky, tvary i
jednání jsou reprezentovány jako soubory diskrétních
vzorků, ať již jde o pixely, mnohoúhelníky, voxely,
znaky, skripty. Na vyšší úrovni jsou tyto jednotky
skládány do objektů, ale ponechávají si svojí
oddělenou identitu."
13.
Manovich
3. Princip automatizacejako další z atributů
novomediálního díla vychází z číselného kódování a
modulární struktury, které “umožňují automatizovat
řadu operací při vytváření, manipulaci a přístupu k
novým médiím. Lidská intencionalita proto může být z
tvůrčího procesu alespoň částečně odstraněna.”
Nejvíce viditelným je pro běžného učástníka
mediálního světa efekt prohledávatelnosti obsahu,
který nejlépe reprezentuje vyhledávač Google.
14.
Manovich
4. Princip variabilitynovomediálních artefaktů
vychází z předchozích bodů. “Stará média zahrnovala
lidského tvůrce, který osobně sestavoval prvky textů,
obrazů nebo zvuků do určité kompozice, nebo
sekvence. Tím, že byly uloženy do materiálu, je jejich
souslednost pevně daná. Může být vytvořeno mnoho
kopií původního originálu, které budou v souladu s
logikou industriální společnosti zcela identické. Nová
média jsou naopak charakteristická svou variabilitou.
15.
Manovich
5. Princip překódováníkdy “Logika počítačů se
vepisuje hluboko do kulturní úrovně médií již z toho
důvodu, že nová média jsou vytvářena, rozšiřována,
ukládána i archivována díky počítači. Způsoby, kterými
počítače formují náš svět, reprezentují a zpřístupňují
data, klíčové operace ovládající počítačové programy
(…) zkrátka vše, co můžeme označit za ontologii,
epistemologii a pragmatiku počítače, to vše ovlivňuje
kulturní úroveň nových médií, jejich organizaci, nové
žánry, ale také obsah.”
16.
Předběžné poznámky
Nová médiajsou charakteristická možností kopírování
bez ztráty informace.
Nová média jsou často ukládána ve zkomprimované
podobě (indexy v databázích, komprimační formát
obrázků.)
Sociální média
Christian Fuchsupozorňuje na fakt, že nepanuje
obecná shoda ohledně jejich přesného vymezení,
když pojem sociální média zastřešuje jak blogy, tak
tzv. social network sites (jako například Facebook),
stejně jako mikroblogy (jako Twitter), různé wiki
(kolektivně editované encyklopedie), ale také jiné
stránky s uživatelsky generovaným obsahem nebo
třeba stránky určené k sdílení obsahu.
19.
Sociální média
Americká teoretičkadanah m. boyd říká, že principy
sociálních sítí v textu Social Network Sites: Definition,
History, and Scholarship umožňují:
1. vytvářet veřejné nebo poloveřejné profily uvnitř
ohraničeného systému
2. vytvářet seznamy uživatelů, s nimiž jsem ve spojení
prostřednictvím nějakých sociálních akcí
3. zobrazit a procházet listy těchto spojení a to nejen
uživateli samotnému, ale také ostatním uživatelům
20.
Sociální média
José vanDijck v The Culture of Connectivity navrhuje
kriticky zkoumat sociální média jako techno-kulturní
konstrukt a socioekonomickou strukturu tvořenou šesti
základními částmi: vlastnictvím, technologiem, pravidly
užívání, uživately, obchodním model a obsahem.
21.
Sociální média
I přesrůzné názory na to, jak definovat sociální média
jako specifický druh nových médií, se všichni autoři
shodují v tom, že se jedná o virtuální prostor, ve
kterém hraje zásadní roli možnost sociálních interakcí
mezi uživately, a že tyto interakce mají specifický
dopad na vytváření identity uživatelů, komunikačních
situací a komunit.
22.
Sociální média
Sociální médiajako Facebook, Twitter či Instagram
nabízejí celou řadu různých typů sociálních akcí. Na
Facebooku je to kupříkladu přátelství, “to se mi líbí”,
sdílení, komentář. Sociální média jsou novomediální
prostředí pro masivní sociální interakci.
Vhodným frameworkem může být dramaturgická
sociologie E. Goffmana.
23.
Goffmanova teorie
Pokud chápemechování uživatelů sociálních sítí v
rámci dramaturgické sociologie, můžeme konkrétní
profil uživatele a jeho sociální akce chápat jako
součást osobní fasády. Z tohoto pohledu všechny
prvky výstavby osobního profilu tvoří prvky fasády
uživatele, které si uživatel volí s ohledem na svou
osobní identitu. Volba jména, fotografie, míra
nastavení soukromí, způsob vyplnění popisu a další
jsou výrazem uživatelovy identity.
24.
Goffmanova teorie
Identita samaovšem vzniká z napětí mezi tím, jak se
osoba vidí a jaké má postavení ve vztahu uvnitř
skupiny a vztahů s okolím. Z pohledu strojového
zpracování je výraz každé identity do značné míry
možné strojově zpracovat a pokusit se v něm najít
nějaké vzory.
25.
Goffmanova teorie
Ilustrativním příklademmůže být volba uživatelského
jména na sociální síti Facebook. Jméno, respektive
jeho podoba paří k informacím, které účastník získává
před započetím komunikace. Zároveň je jeho volba
ovlivněna velmi silně normou, kterou Facebook své
uživatele zavazuje. Pravidla Facebooku zavazují
uživatele k užití skutečného jména, nepoužívání
speciálních symbolů, přezdívek apod. Pokud tedy
uživatel toto pravidlo porušuje, dává tím jednoznačně
najevo, že má nějaký problém s tímto pojetím.
27.
Představení
Termínem představení myslíGoffman takovou činnost,
"kterou jednotlivec provádí v době vyznačující se jeho
trvalou přítomností ve společnosti konkrétního
souboru pozorovatelů a která má na pozorovatele
nějaký vliv." (Goffman str. 29). Scénou představení
jsou jednotlivé stránky, skupiny či uživatelské profily a
podobně, kde se interakce uskutečnují.
28.
Představení
Z tohoto pohledujsou sociální akce jako je postování
statusů, lajkování příspěvků či jejich komentování
prostředky takového představení. Uživatel má pro své
představení k dispozici fasádu svého profilu, kde je
možné sdílet o sobě různé informace. Sem patří
kupříkladu i seznam stránek, které má označené jako
oblíbené (viz Elaine Wallace, Isabel Buil a Leslie de
Chernatony: Facebook ‘friendship’ and brand
advocacy).
29.
Předběžné poznámky
Sociální médialze vnímat jako prostor pro každodenní
sebeprezentaci a jako scénu pro naše představení
(interakce).
Tato jednání jsou sociální, mají intencionalitu a mohou
být podrobena tradičnímu druhu výzkumu, ať již
kvalitativnímu nebo kvantitativnímu.
V prostředí nových médií pak máme k dispozici
záznamy těchto sociálních jednání jako data, která
můžeme dále zpracovat.
Data (vs informace)
"Informaceje nějaká odlišnost, která vytváří
rozdíl." (MacKay, 1969)
"Informace je (...) rozdíl, který dělá rozdíl." (Bateson,
1973)
"Dd datum = def. X je různé od Y, kde X a Y jsou dvě
neinterpretované proměné a doména je ponechána k
dalšímu výkladu." (Floridi 2011, str. 85)
32.
Data (vs informace)
PodleFloridiho můžeme chápat data jako to, co je
identické, nebo co vůbec umožňuje signál, který je pak
možné symbolicky zakódovat. (Floridi 2011, str. 86)
33.
Data (sémioticky)
“A sign,or representamen, is something which stands
to somebody for something in some respect or
capacity.” (Peirce)
34.
Peirceovská typologie
znak (sign),jeho Objekt a jeho interpretant
sémiosis je činnost, která spojuje Z-O-I
sémiosis je potencionálně nekonečná
komplexní systém znaků
nejznámější ikon, index, symbol
35.
Ikon a index
Ikonje znak, který se vztahuje k Objektu a denotuje ho
jen díky svým vlastním rysům, které má bez ohledu na
to, zda nějaký Objekt skutečně existuje anebo ne.
Index je znak, který se vztahuje na Objekt a denotuje
ho tím, že je jím skutečně ovlivněný. Příkladem indexu
je klepání na dveře.
Ikony ani indexy však nic netvrdí, nýbrž ukazují.
36.
Symbol
Symbol je znak,který se vztahuje k Objektu a
denotuje ho díky zákonu, většinou asociaci všeobecné
ideje a tento zákon způsobuje interpretaci. Jinými
slovy znak tu nemá vztah ani podobnosti a ani faktické
souvislosti, ale jakési značky pravidla, které nám
umožňuje spojení mezi jinak nespojitými věcmi.
37.
Doplnění definice
Data jsousymbolická (konvenční) vyjádření indexů
skutečnosti, už obsahují určitý pohled. Ale nic neříkají.
Symboličnost je to, co umožňuje jejich uložení.
Míra konvenčnosti pak to, co umožňuje jejich
komunikaci.
Rozdíl je v tomto případě působení.
Jde jen o doplnění Floridiho.
Big Data
pojem pocházíz oblasti zpracování digitálních dat
Původně: Termín "Big Data" se vztahuje na soubory
dat, jejichž velikost je za schopností typických
softwarových nástrojů je zachytit, ukládat, spravovat a
analyzovat. (McKinsey, 2011)
40.
Big Data -3V a 1V
Dnes spíše důraz na jejich komplexnost:
volume (objem) dat narůstá exponenciálně.
velocity (rychlost) Objevují se úlohy vyžadující
okamžité zpracování velkého objemu průběžně
vznikajících dat. (kamery, sociální sítě)
variety (různorodost, variabilnost) kromě obvyklých
strukturovaných dat jde o úlohy pro zpracování
nestrukturovaných textů, ale i různých typů
multimediálních dat.
41.
Big Data -3V a 1V
veracity (věrohodnost) nejistá věrohodnost dat v
důsledku jejich nekonzistence, neúplnosti, nejasnosti a
podobně. Vhodným příkladem mohou být údaje
čerpané z komunikace na sociálních sítích.
42.
Změna cíle
“small data”- obvykle byly designovány pro odpověď
na nějaké konkrétní otázky, udržovaly se v agregacích
Big Data - obvykle existuje jen rámcová představa o
možnostech využití, důraz je proto kladen na
skladování co nejnižší granularity data
(Berman, Jules J.: Principles of big data : preparing,
sharing, and analyzing complex information. 2013)
43.
Technické důsledky
v posledníletech došlo k prudké demokratizaci v
přístupu k velkým datům
levnější datové uložiště, rozvoj open source řešení pro
zpracování (Hadoop, Elasticsearch aj.)
akcelerace vývoj data miningových nástrojů a
statistických programů (R, Rapidminer a další)
44.
3. Big SocialData
jako nové pole
Surface vs deep data
45.
Big Social Data
Sociálnímédia patří mezi významné producenty tzv.
velký dat.
Sociální média produkují data nejen obsahová
(statusy, tweety, fotografie a další), ale také značné
množství formalizovaných typů informací, které
vyjadřují nějaké sociální jednání nebo postoje.
46.
Big Social Data
Tatoperspektiva otevírá pro humanitní a sociální vědy
novou perspektivu, kterou Manovich reflektuje ve
svém textu Trending: The Promises and the
Challenges of Big Social Data.
Prostřednictvím sociálních sítí a dalších zdrojů máme
možnost přistupovat k velmi rozsáhlým záznamům o
lidském chování jak do hloubky, tak do šířky. Nejsme
již nuceni si vybrat mezi hloubkovým šetřením s
malým počtem lidí, nebo dotazníkovým šetřením s
velkým počtem respondentů.
47.
Big Social Data
Therise of social media along with the progress in
computational tools that can process massive
amounts of data makes possible a fundamentally new
approach for the study of human beings and society.
We no longer have to choose between data size and
data depth. We can study exact trajectories formed by
billions of cultural expressions, experiences, texts, and
links. The detailed knowledge and insights that before
can only be reached about a few people can now be
reached about many more people. (Manovich 2011)
Social Network
Analysis
Analýza sociálníchsítí je strategie pro výzkum
sociálních struktur za využití teorie grafů.
Analýza sociálních sítí je klíčová technika v moderní
sociologii.
K dispozici je celá řada nástrojů pro její provedení.
Základní text: Stanley Wasserman, Katherine Faust:
Social Network Analysis - Methods and Applications
50.
Stavební prvky grafu
uzel(nodes, vertices, entities, items etc.)
vazba (ties, connections, relationships etc.)
vazby mohou mít směr případně váhu či jich
může být víc
z pohledu sociologie mohou mít i kvality např.
silné nebo slabé
51.
Typologie grafů I.
Unimodal(jedna přímá vazba)
Multimodal (vícero přímých vazeb)
Affiliation (vazba prostřednictvím např. akce)
Multiplex Network (kvalitativně různé vazby)
52.
Typologie grafů II.
Full(každý s každým)
Partial (tak nějak všichni)
Egocentric (já jsem centrum dění)
Co lze třebaměřit
Počet hran (Degree Centrality)
Prostřednictví (Betweenness Centralities)
Blízkost (Closeness Centrality)
Hustota (Density), Dosažitelnost (Reachability)
Eigenvector Centrality
Shluky a komunity
56.
Degree Centrality
počet přímýchvazeb k dalším uzlům
měří aktivitu uzlů v síti.
uzly s vysokou hodnotou Degree Centrality
jsou „spojky“ nebo „středy“ v této síti.
57.
Closeness Centrality
nejvyšší, jestližez uzlu lze dosáhnout ke všem
dalším uzlům v síti.
nejmenší hodnota součtu vzdáleností k
ostatním uzlům
uzly snadno přijímají a přenášejí inovace.
uzly s vysokou mírou blízkosti středu mají velký
vliv na to, co se v síti odehrává.
58.
Betweenness - Bridges
nejvyššípokud cesty mezi libovolnými dvěma
uzly sítě vždy procházejí tímto uzlem.
měří, kolik cest mezi dvojicí uzlů prochází
daným uzlem.
závora, propojení nebo zprostředkovatel rolí.
kontroluje tok informací v síti a umožňuje
dobrou viditelnost všeho, co se děje v síti.
Eigenvector centrality
Lze počítatjen v neorientovaném grafu
Přidává k výsledku nejen počet vazeb uzlu, ale
také počet vazeb uzlů, které mají uzly s ním
spojené
Odhaluje i nepřímý vliv
Google Page Rank je varianta Eigenvector
centality
Homofilie
Similarity breeds connection.This principle — the
homophily principle — structures network ties of every
type, including marriage, friendship, work, advice,
support, information transfer, exchange,
comembership, and other types of relationship. The
result is that people’s personal networks are
homogeneous with regard to many sociodemographic,
behavioral, and intrapersonal characteristics.
Homophily limits people’s social worlds in a way that
has powerful implications for the information they
receive, the attitudes they form, and the interactions
they experience. (Miller McPherson)
64.
Podobnost
centrální roli homofiliea obecně možnosti počítání v
sociálních sítích hraje podobnost, která je hybnou silou
uspořádávání
podobnost lze ovšem formalizovat
65.
Formální definice
Podobnost (Similarity)měří jak blízko jsou jsi dvě
instance. Čím “blíže” si dvě instance jsou, tím je číslo
vyjadřující jejich blízkost nižší.
Nepodobnost (Dissimilarity) měří jak jsou dvě instance
různé. Čím více se liší, tím je nepodobnost větší.
Vzdálenosti (Proximity/Distance) je vyjádřením je
vyjádřením vzájemné podobnosti nebo nepodobnosti
instancí.
66.
Formální definice
Metrické vzdálenost(Distance metric) je specifickým
případem vyjádření podobnosti instancí, které splňují
následující tři podmínky, kdy d je vyjádřením
vzdálenosti mezi instancemi x, y a z.
1. Minimality: d(x, y) => 0; d(x, y) = 0 iff x = y;
2. Symmetry: d(x, y) = d(y, x);
3. The triangle inequality: d(x, y) + d(y, z) ≥ d(x, z).
67.
Formální definice
Tato vymezenísamozřejmě nedefinují co podobnost
je, ale jak s ní budeme zacházet jako s číselnou
hodnotou a jaké vlastnosti bude mít specifické
vyjádření.
Dekang Lin shrnuje tři základní intuice podobnosti v
studii An Information-Theoretic Definition of Similarity
takto:
68.
Formální definice
Intuition 1:The similarity between A and B is related to
their commonality. The more commonality they share,
the more similar they are.
Intuition 2: The similarity between A and B is related to
the differences between them. The more differences
they have, the less similar they are.
Intuition 3: The maximum similarity between A and B is
reached when A and B are identical, no matter how
much commonality they share.
Kolmogorov a složitost
TeorieKolmogorovy komplexity se snaží odpovědět na
otázku “Co je nahodilý objekt?”
Představuje algoritmickou teorii informace a tvoří de
facto doplněk teorie Shannona.
71.
Složitost
Mějme k dispozicitři číselné řetězce v desítkové
soustavě:
a) 3333333333
b) 3141596535
c) 84354279521
Který z nich bychom považovali za náhodný?
72.
Složitost
Čím delší jepopis postupu, který potřebujeme k
popsání řetězce, tím je řetězec více komplexní. V
Kolgomorově pojetí však nejde o popis v nějakém
jazyce, ale existenci univerzalního počítačového stroje
(Turingova stroje), který takový popis generuje, a délku
tohoto programu.
73.
Informační vzdálenost
Teorie informačnívzdálenosti představuje rozšíření
Kolmogorovy komplexity o myšlenku vzdálenosti mezi
řetězci, respektive jejich podobnosti. Podle ní je
minimální informační vzdálenost mezi dvěma
instancemi (řetězce x a y) vyjádřená délkou
nejkratšího programu, který transformuje jeden
řetězec na druhý a naopak. Univerzální informační
vzdálenost je vyjádřena pak vzorcem E(x,y) =
max{K(x|y),K(y|x)}.
74.
Informační vzdálenost
Vitányi aCilibrasi od této myšlenky odvozují obecnou
normalizovanou informační vzdálenost (normalized
information distance), která by byla schopna
produkovat i metrickou vzdálenost. Výsledkem je
následující vzorec
75.
NCD
Teorie informační vzdálenostije teoretická konstrukce,
kterou není možné v praxi vytvořit, je totiž závislá na
nespočitatelné funkci K. Je však možné použít jinou
funkci, která se v reálném světě o podobnou funkčnost
snaží. Těmito programy jsou dle autorů kompresní
algoritmy, které mají za úkolu spočítat co největší
bezztrátovou kompresi dat, tedy co největší redukci
komplexit pomocí univerzálního programu.
76.
NCD
Odpovídá to izkušenosti, kterou máme z jejich
každodenního používání. Pokud pomocí kompresního
programu tzv. zabalíme dva soubory, které jsou si
podobnější než jiné dva, rozdíl mezi výslednou délkou
nového souboru a délkou odpovídající součtu délek
původních souborů je menší.
77.
NCD
Komprese dat (takékomprimace dat) je zpracování
počítačových dat s cílem zmenšit jejich objem
(jednotka bajt) při současném zachování informací v
datech obsažených. Úkolem komprese dat je zmenšit
datový tok při jejich přenosu nebo zmenšit potřebu
zdrojů při ukládání informací. (Wikipedia)
Obvykle se snaží alg. nalézt opakující se sekvence
znaků a vytvořit z nich slovník, který umožňuje odkaz
na přesné místo.
NCD
Upravený vzorec vypadánásledovně:
Přičemž Z je kompresní algoritmus a x a y zůstávají
řetězce určené k porovnání.
Formální důkazy Vitányiho a Cilibrase ukazují, že se
jedná o plnohodnotnou distanční metriku.
80.
NCD
Autoři NCD provedlisérii testů navrženého postupu na
celé řadě druhů řetězců (knihy, lidský genom, MIDI
soubory), které se zdají potvrzovat univerzální
charakter navrženého modelu a to včetně klasifikace
heterogenních řetězců. Na vstupu v tomto
experimentu byla data z genetiky, ukázky z literárních
textů, MIDI soubory, binární počítačové programy a
zkompilované programy ze zdrojových kodů
programovacího jazky Java. Využit byl kompresní
algoritmus bzip a metoda quartet clustering.
82.
NCD
Experimenty dalších autorůpotvrzují předchozí
experimenty autorů, včetně předpokládané odolnosti
NCD proti šumům v textu. Dále se věnují jeho dalším
aplikacím například pro automatickou evaluaci
strojového překladu. Další studie, za účasti autora
původního týmu Paula Vitanyiho, pak sledují využití
NCD při klastrování.
83.
NCD
v rámci seminářeDigital Humanities provedli studenti
Studia nových médií řadu experimentů, které
naznačují univerzálnost postupu:
http://snm-blog.tumblr.com/post/42742243421/digital-
humanities-6-complearn
http://janmarsicek.tumblr.com/post/44283514150/ncd-
capek-macha-nemcova
http://jitkab.tumblr.com/post/38054898777/podobnost-
seri%C3%A1l%C5%AF-podle-ncd
84.
Normalized Web
Distance
Aplikace teorieinformační vzdálenosti v NCD se
omezuje pouze na řetězce, nikoli na ideje nebo pojmy.
Proto se její autoři rozhodli příjít s metrikou, která toto
omezení překračuje a tím je korpus World Wide Webu.
Podle Cilibrase je možné index vyhledávačů chápat
jako uložení univerzální distribuce slov na stránkách a
vyhledávač pak jako určitý druh pseudo-compressoru,
který zohledňuje všechny dimenze lidského mínění.
85.
Normalized Web
Distance
Vitanyi sodkazem na Shannon-Fano code a uchopení
indexu korpusu jako pseudo-compressoru pak
formalizuje novou metriku takto:
Kde f(x) je počet stránek obsahující x, f(x,y) je počet
stránek obsahující obojí a N je počet celkově
indexovaných stránek.
86.
Normalized Web
Distance
Cilibrasi popisujeve své dizertaci Statistical inference
through data compression základní kontrast mezi
oběma přístupy takto:
The first type is the NCD based on a literal
interpretation of the data: the data is the object itself.
The second type is the NGD masses of contexts
expressing a large body of common-sense
knowledge. It may be said that the first case ignores
the meaning of the message, whereas the second
focuses on it.
87.
Normalized Web
Distance
Série experimentuprovedené Cilibrasem a Vitanyim
pomocí výsledků vyhledávače Google přináší v tomto
ohledu velmi uspokojivé výsledky.[15] Předmětem
experimentů byly názvy díla holandský malířů 17.
století, názvy anglických románů, čísla a barvy a
názvy Shakespearových děl. Ve všech případech
dokázal postup díla správně rozdělit. Předmětem
experimentu byla i rekonstrukce vazeb vyjádřených
experty ve WordNetu. Zde byla přesnost mezi NGD a
vazbou ve WordNetu 0.8725.
Social Distance
V návaznostina Goffmana můžeme říci, že identita
člověka je tvořena osobní historií jeho sociálníhch
jednání.Tato jednání vyjadřují jeho postoje.
Příslušnost k sociálním skupinám pak vyjadřuje určité
preference a zájmy.
Sociální média jako Facebook a další nabízejí
možnost analýzy takových to jednání zachycených v
bi-modálních sítích.
90.
Normalized Social
Distance
Pokud NWDpřináší myšlenku sémantické vrstvy
informací, lze se odvážit ještě o jednu vrstvu dál a to
na vrstvu pragmatickou, opírající se o množství
podobností, které jednotlivé sociální skupiny tvoří. A
definovat formálně metodu počítání vzdálenosti mezi
dvěma sociálními skupinami.
91.
Normalized Social
Distance
Formálně vypadátakto:
Kdy f(x) je počet členů jedné subskupiny, f(y) je počet
druhé subskupiny, f(x,y) vyjadřuje počet členů obou
skupin a N je celkový počet členů skupiny.
92.
Normalized Social
Distance
Takto formálněvyjádřená vzdálenost by měla být
schopna měřit vzdálenost libovolných dvou sociálních
subskupin, které jsou zastřešeny jednotnou skupinou.
Kupříkladu v případě bimodální sítě navštěvníků
místních restaurací na malém městě by takto šla
počítat bízkost sociální blízkosti podniků.
93.
Normalized Facebook
Distance (NFD)
NSDje ovšem metrika univerzální, kterou je možné
přizpůsobit pro data ze sociálních sítí. V následujících
případových studiích jsem ji aplikoval na případě
sociální sítě Facebook v upravené podobě jako
Normalized Facebook Distance (NFD), která počítá
blízkost jednotlivých stránek na základě průniku jejich
zapojených fanoušků.
94.
NFD
Pokud chápeme popisuživatele de facto jako síť
rozdílu v preferovaných stránkách, nabízí se možnost
nejen věnovat se celkové charakteristice fanoušků
prostřednictvím distančního modelu, ale také jejich
podrobnější charakteristice, přesněji nalezení zřetelně
odlišených subskupin.
95.
NFD
Takováto matice jev podstatě bimodální sítí s relativně
nízkou hustotou, zároveň ale může být podrobena
některým klasickým exploračním technikám, jako je
hierarchický klastering, multidimensionalní scaling či
analýza základních komponent (PCA).
96.
NFD
Pro průzkum takovýchmatic jsem vytvořil aplikace
Facebook profiling, který má na vstupu dva soubory.
První je tabulka s distančním modelem fanoušků a
druhým pak binární matice obsahující na řádcích ID
uživatelů a ve sloupcích pak stránky, v nichž se
fanoušci zkoumané stránky nejčastěji zapojují svým
like.
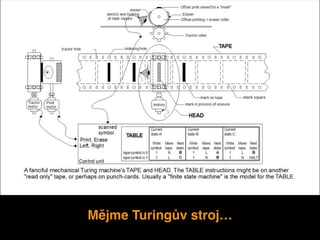
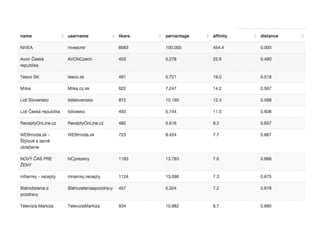
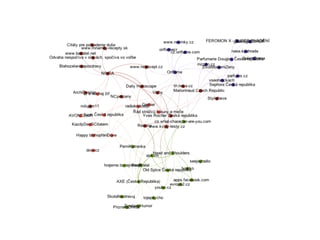
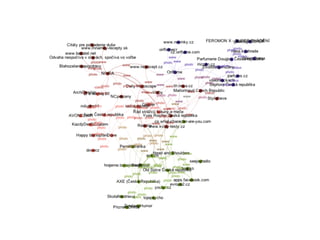
DSSS
Stránka Dělnické stranysociální spravedlnosti, která je
považována za tolerovanou formu neonacismu na
české politické scéně. Minimální hranici pro průnik
jsem v našem případě stanovili na 5% a blízkost
menší než 0.7. V našem případě se jedná o data ze
začátku roku 2014.
Distanční model stránky fanoušků aktivních na
stránkách vypadá takto:
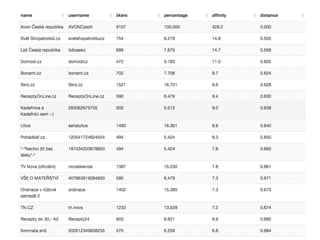
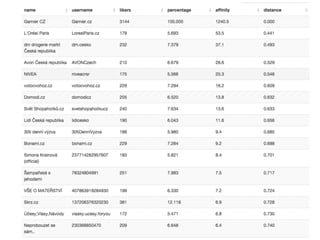
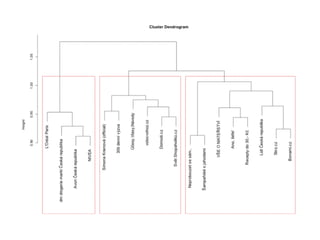
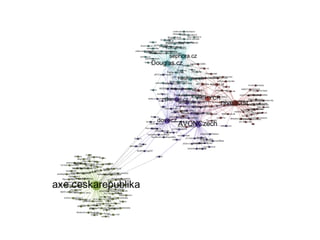
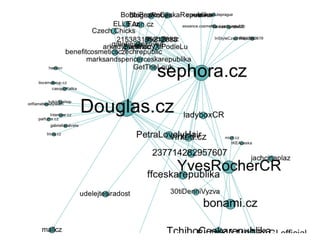
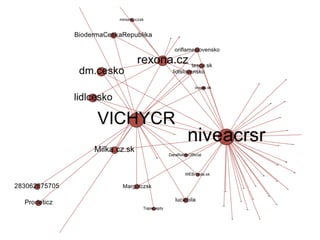
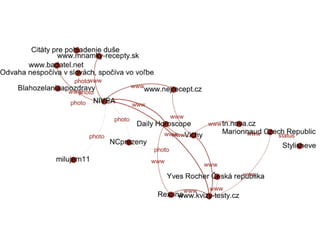
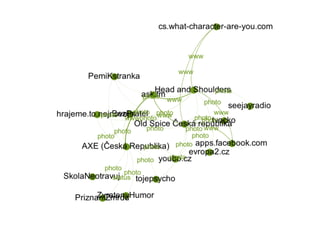
Analýza sdílení
Pokud platí,že uživatelé patří do stejného klastru na
základě blízkosti, pak by se tato blízkost měla projevit i
v tom, co aktivně sdílí na svých stránkách, protože se
de facto jedná o jinou podobu jejich sebeprezentace.
Nasledující grafy ukazují segmentaci stránek na
základě síťového grafu nejčastěji sdílených odkazů na
osobních stránkách aktivních uživatelů stránek.
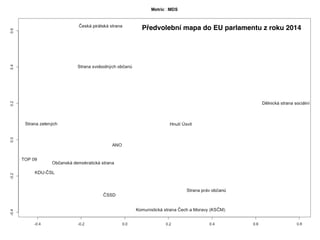
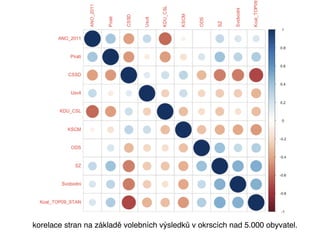
korelace stran nazákladě volebních výsledků v okrscích nad 5.000 obyvatel.
128.
Vzájemná korelace
Pokud facebookovémapy blízkosti skutečně odráží
realitu podobnosti stran, měly by korelovat se
vzájemnou korelací výsledků stran z voleb.
Na vstupu máme tedy dvě matice. Jednu se
vzájemnou vzdáleností stránek politických stran na
Facebooku a druhou s korelacemi stran na základě
volebních výsledků v okrscích nad 5.000 obyvatel.
129.
Vzájemná korelace
Čím lépeodráží mapa z Facebooku reálný svět, tím
by měla být korelace s korelační maticí z reálných
voleb nižší (maximálně provázaný vztah vyjadřuje
hodnota -1). Naopak hodnota 0 vyjadřuje naprostou
nezávislost a data z Facebooku by pak neměla žádný
vztah k offline světu
A skutečně: pro Českou republiku vyšla korelace -0.71
což je na sociální vědy číslo nebývale dobré. Pro
Polsko: - 0.79, pro Slovensko: -0.67 a pro Německo:
0.7























































































![Normalized Web
Distance
Série experimentu provedené Cilibrasem a Vitanyim
pomocí výsledků vyhledávače Google přináší v tomto
ohledu velmi uspokojivé výsledky.[15] Předmětem
experimentů byly názvy díla holandský malířů 17.
století, názvy anglických románů, čísla a barvy a
názvy Shakespearových děl. Ve všech případech
dokázal postup díla správně rozdělit. Předmětem
experimentu byla i rekonstrukce vazeb vyjádřených
experty ve WordNetu. Zde byla přesnost mezi NGD a
vazbou ve WordNetu 0.8725.](https://image.slidesharecdn.com/malaobhajoba-pokorekturach-upravach-151221085101/85/Big-Social-Data-87-320.jpg)










































































![[cz] Časoprostor 2.0](https://cdn.slidesharecdn.com/ss_thumbnails/prezentace1-110602073033-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




















