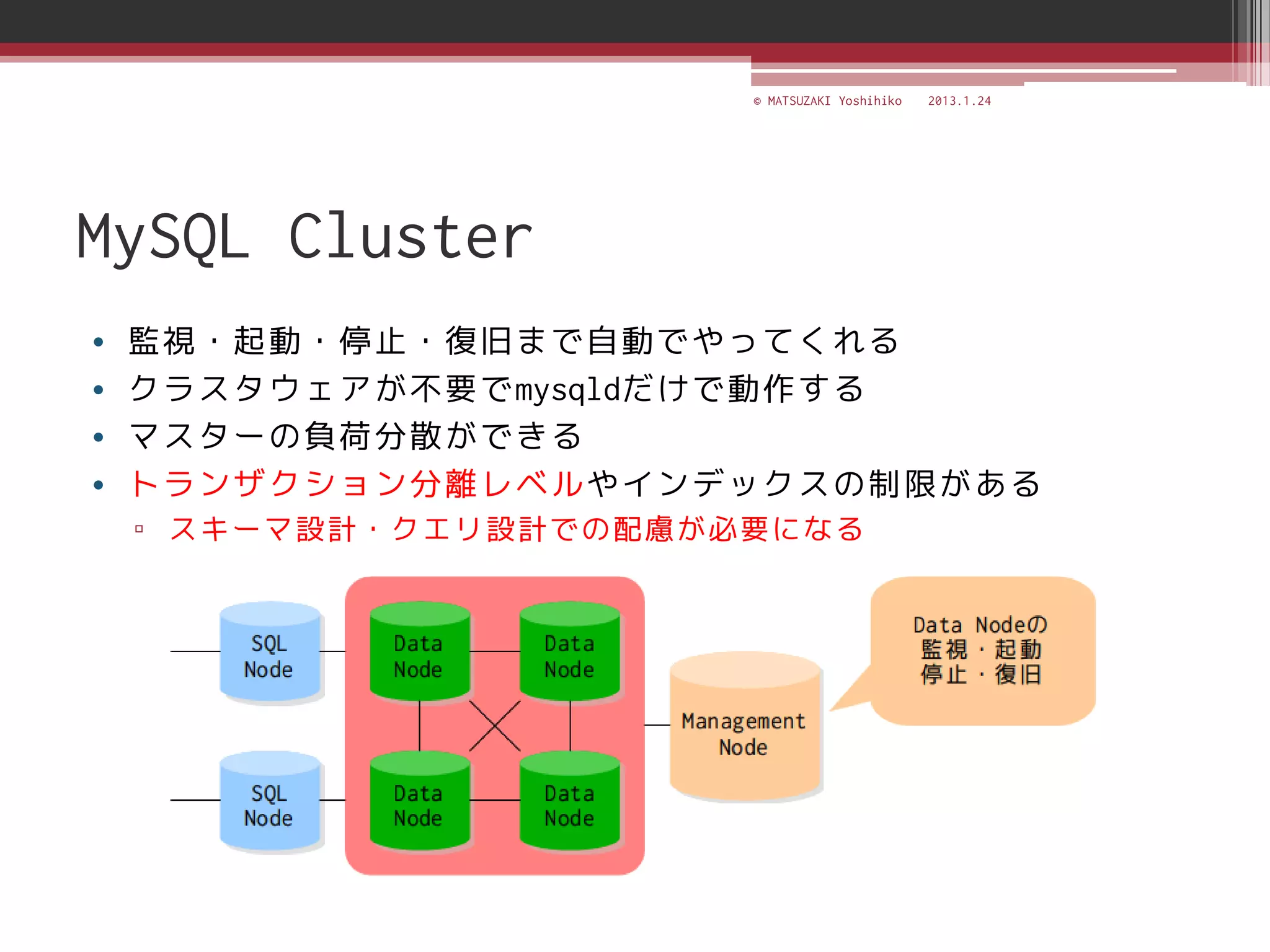
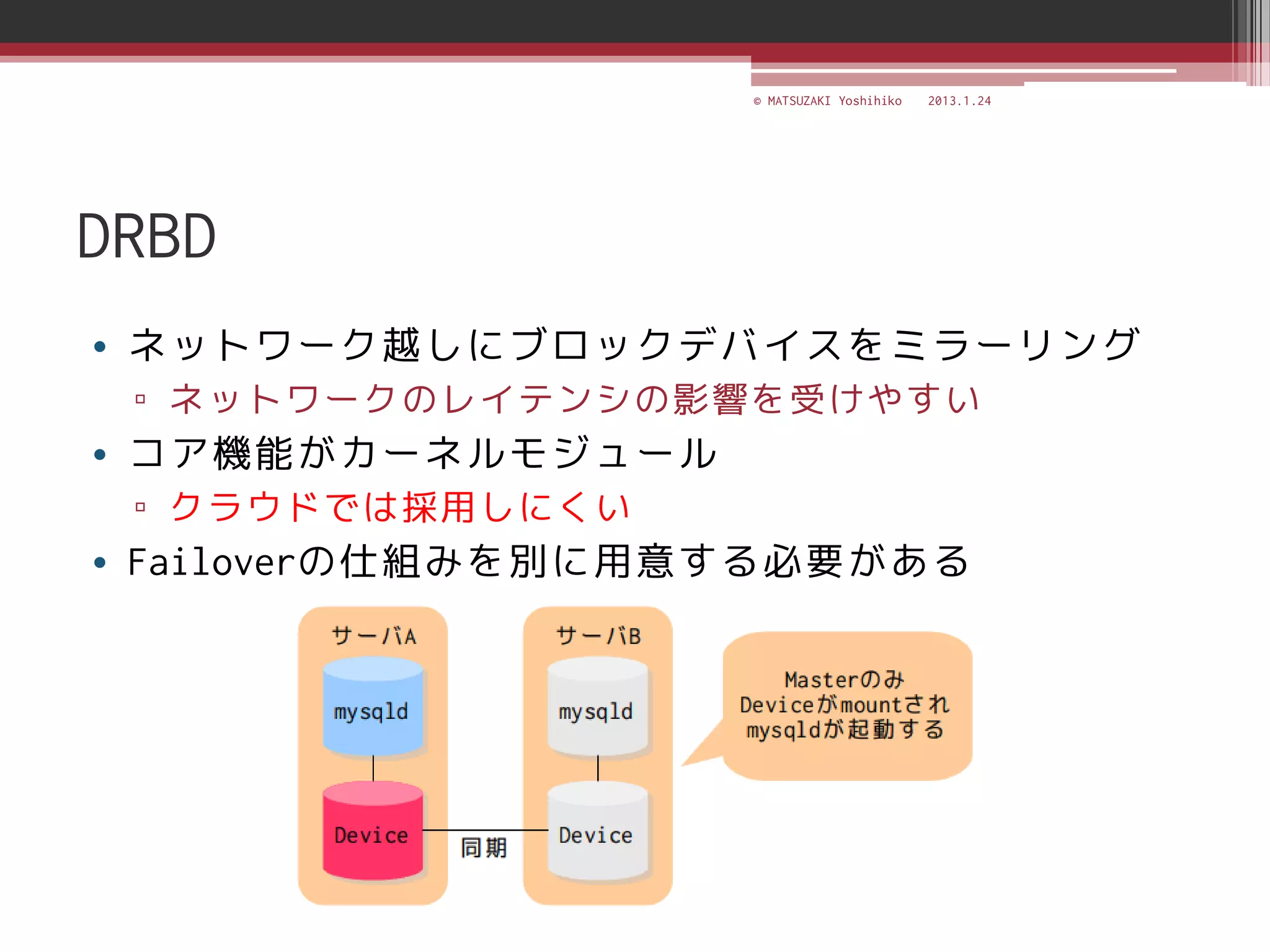
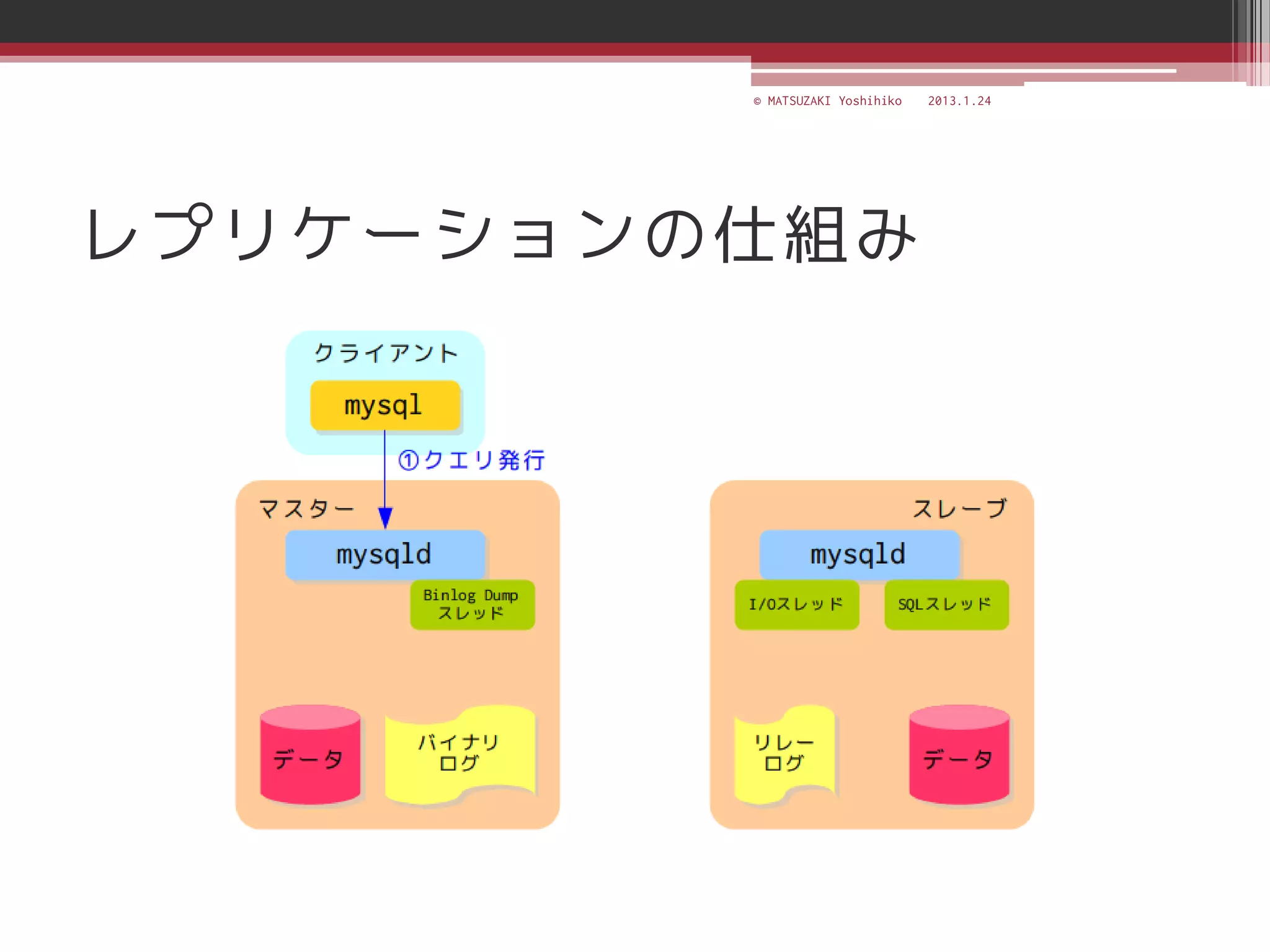
<SKILL BASECAMP 2013> MySQLの冗長化~無停止運用を実現するには~ http://www.pasonatech.co.jp/entry/index.jsp?mode=2&d=on&no=3756










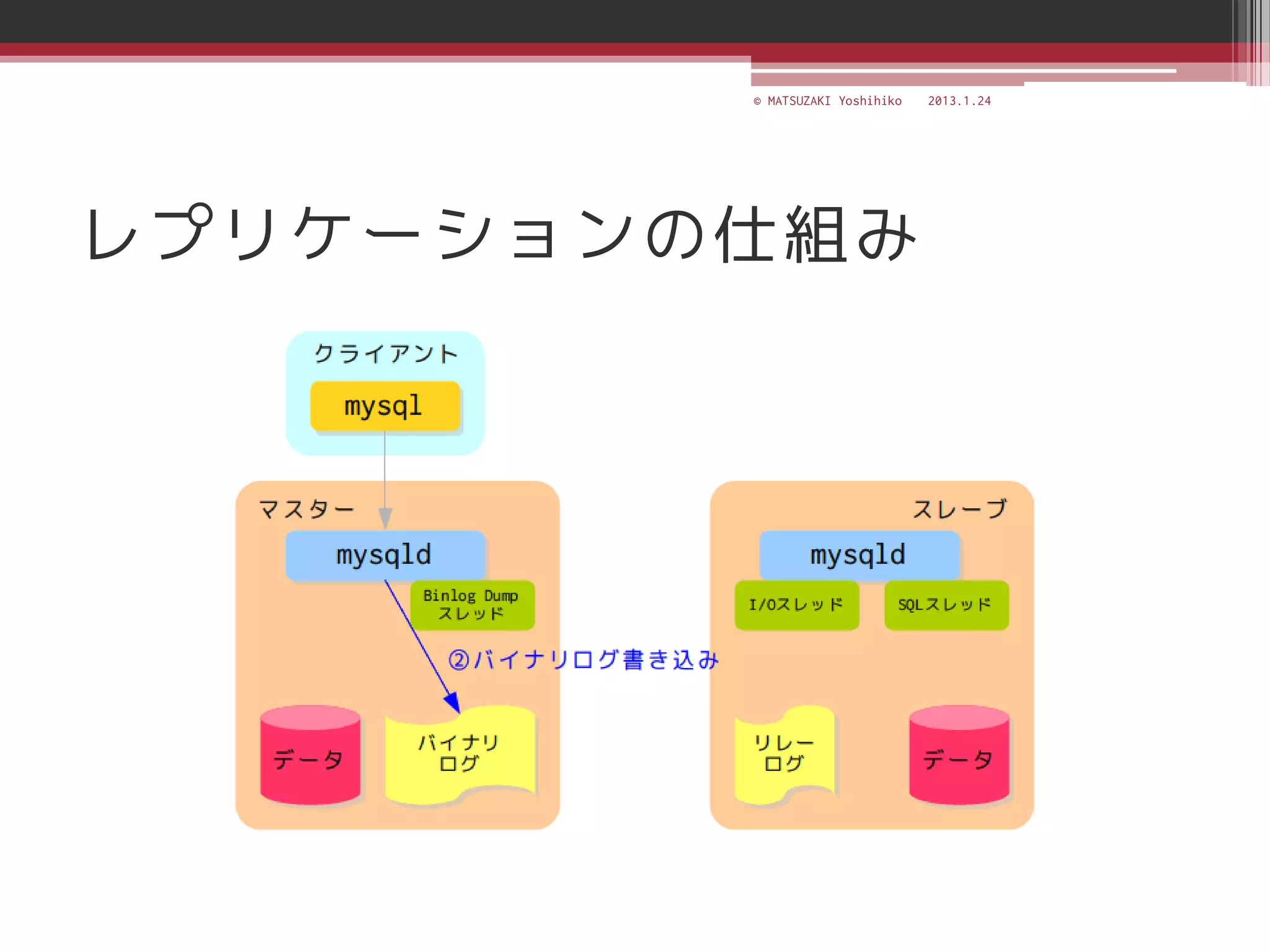
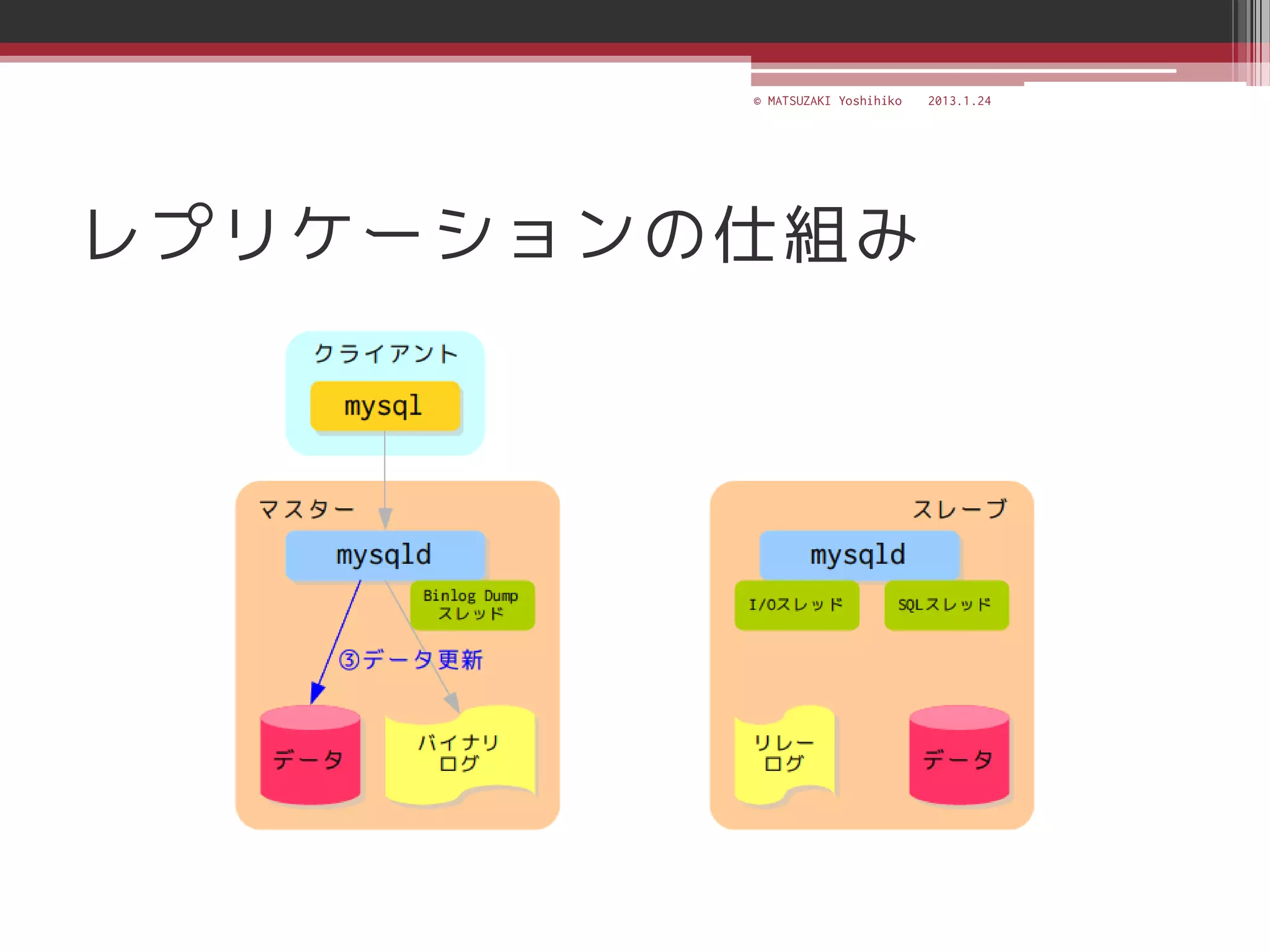
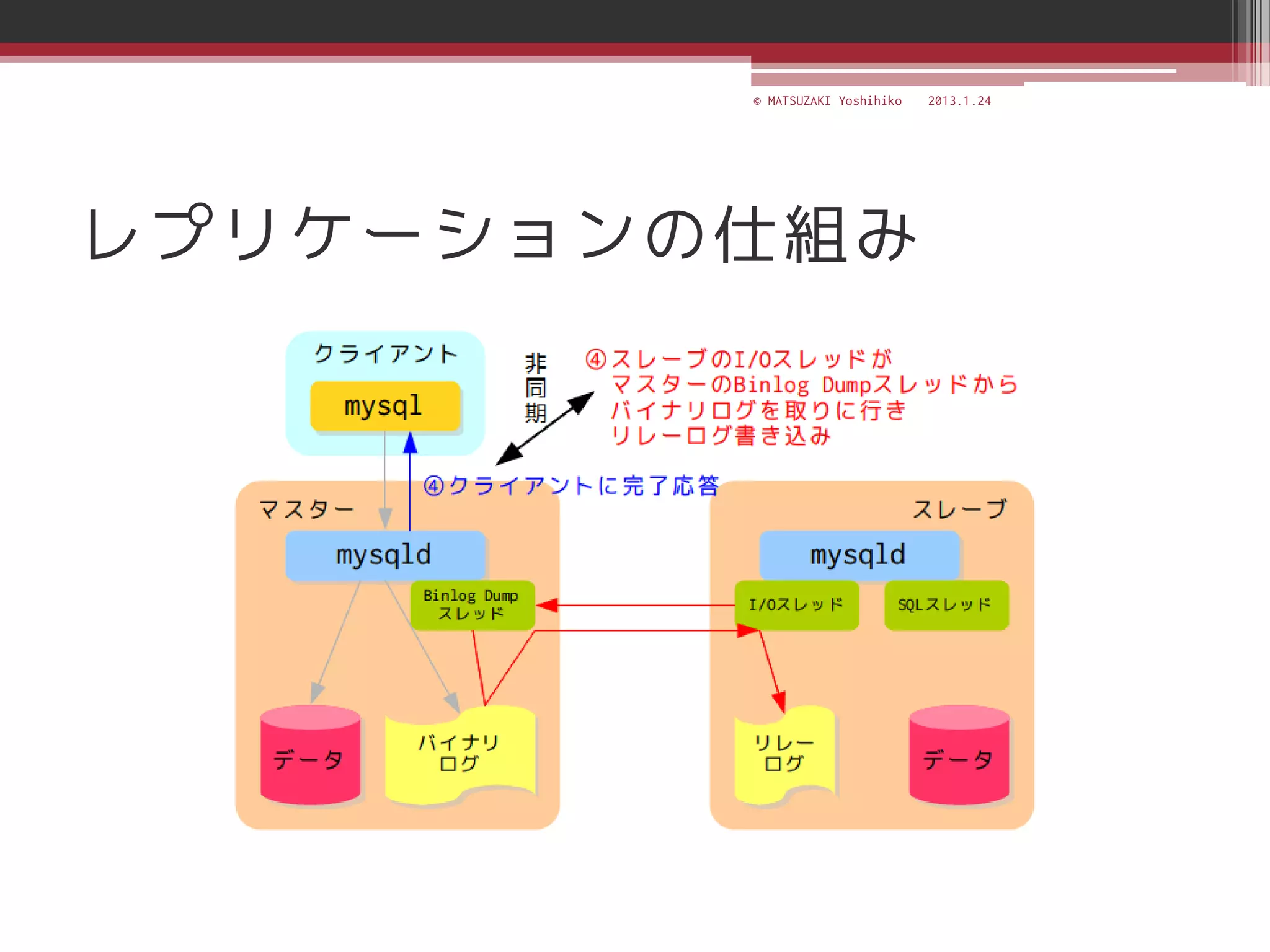
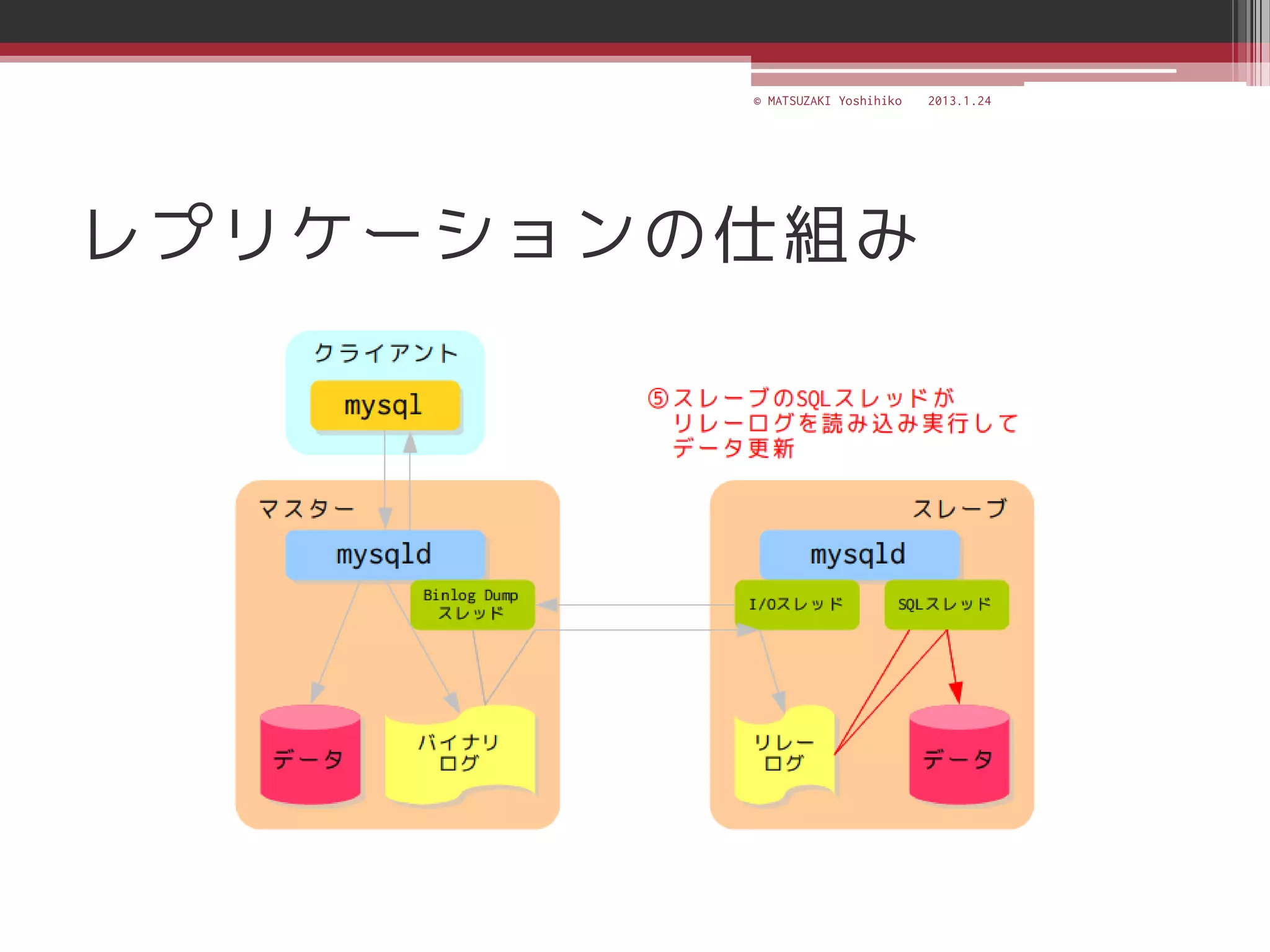







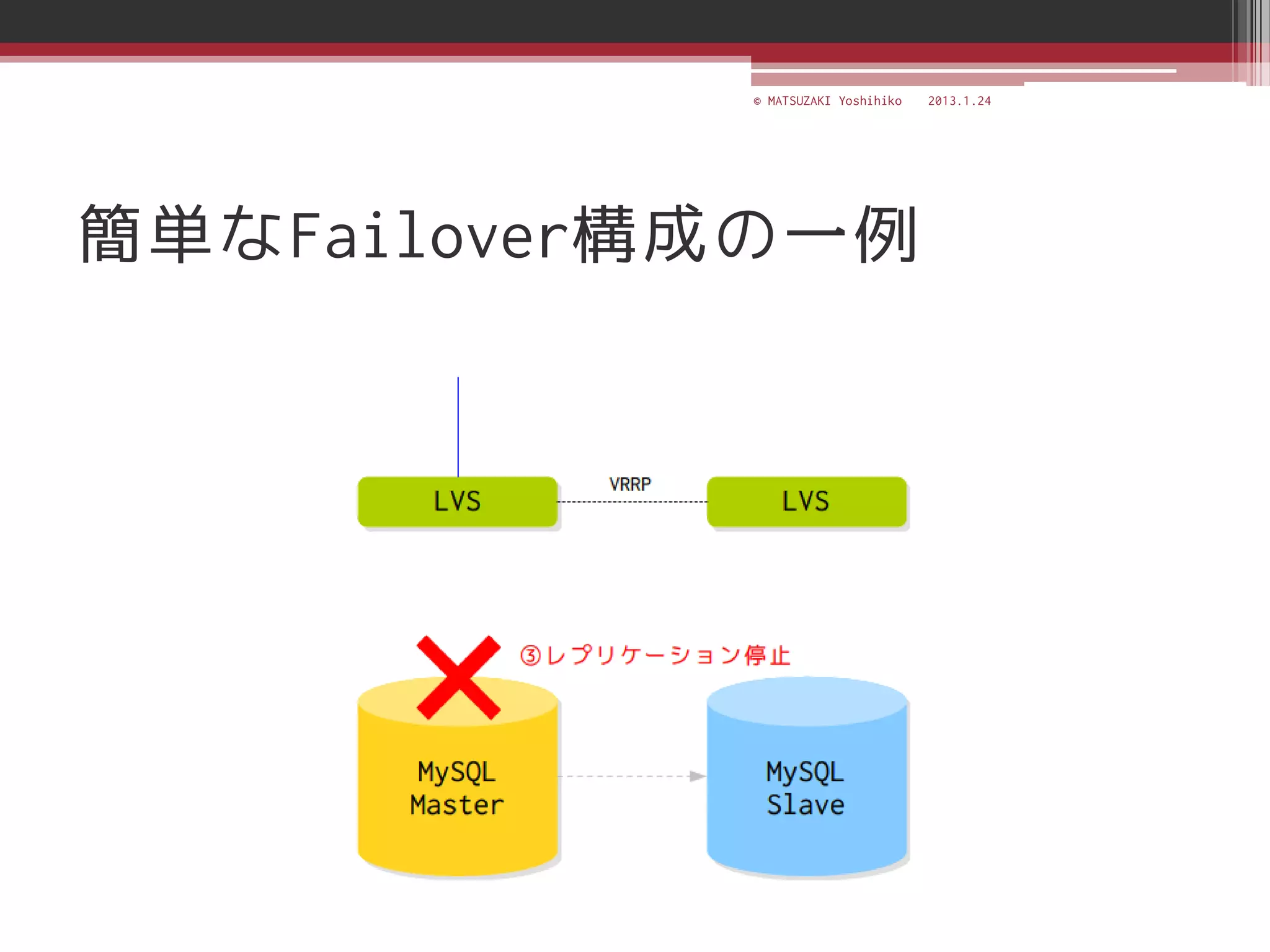
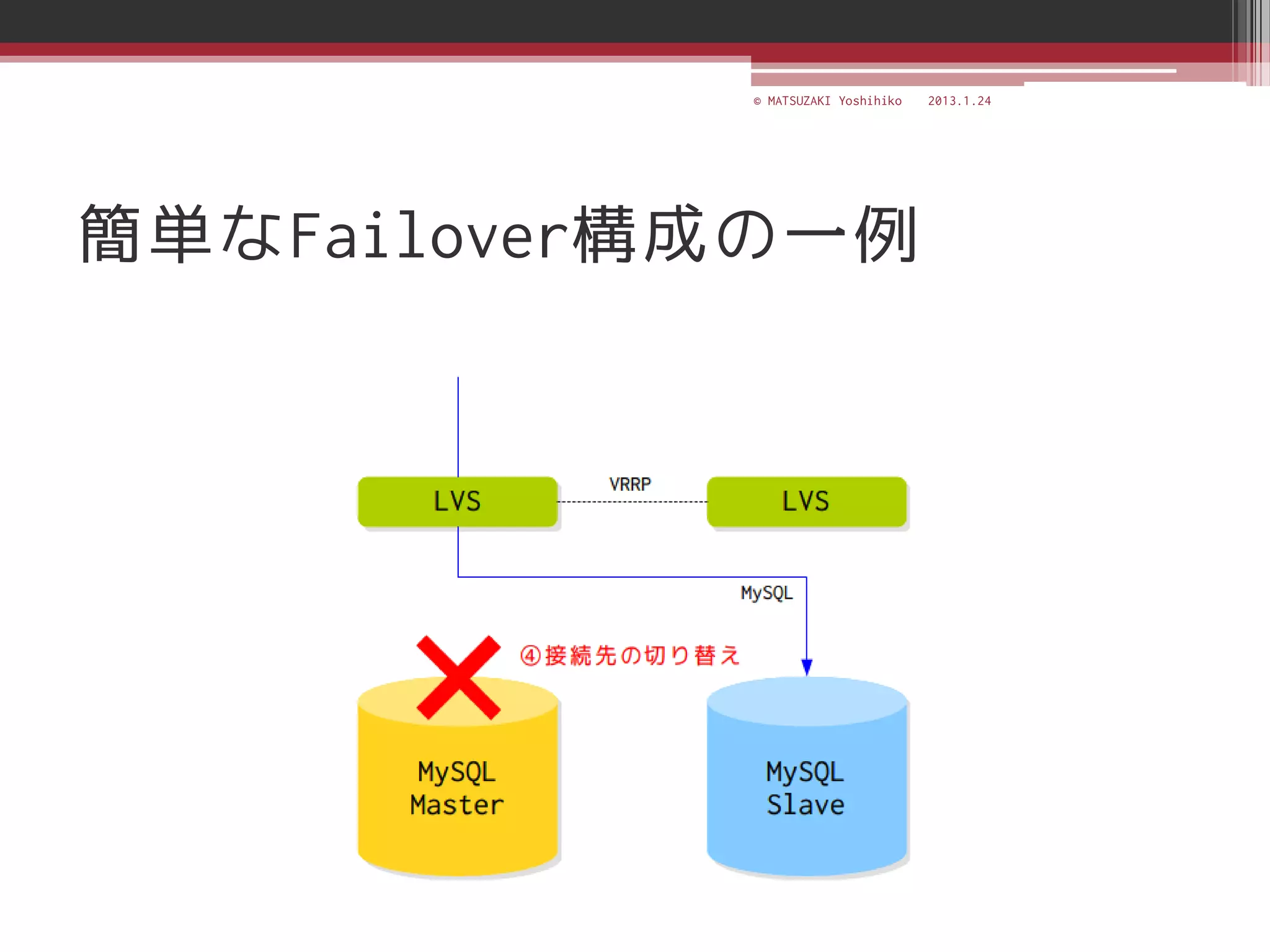








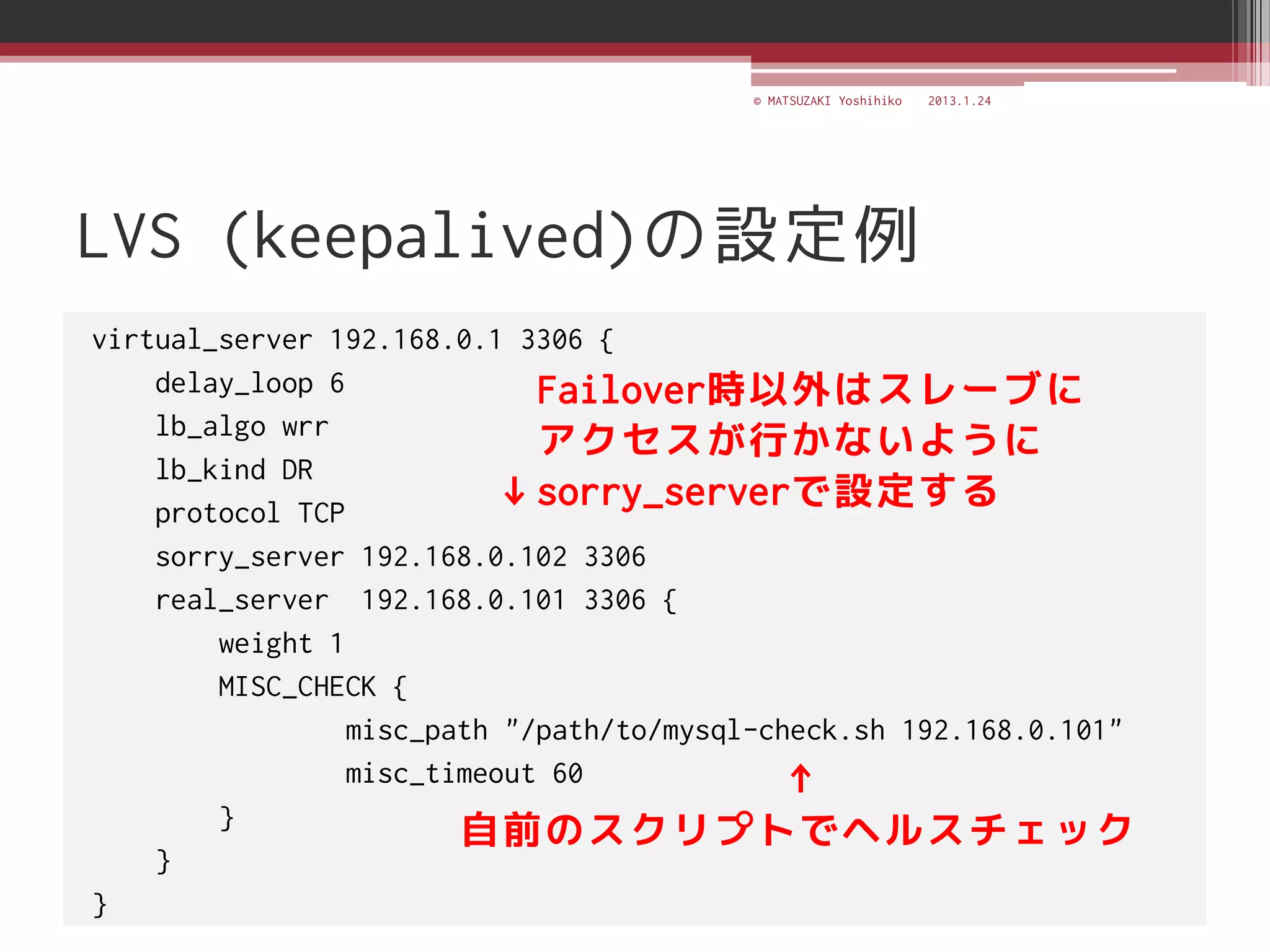

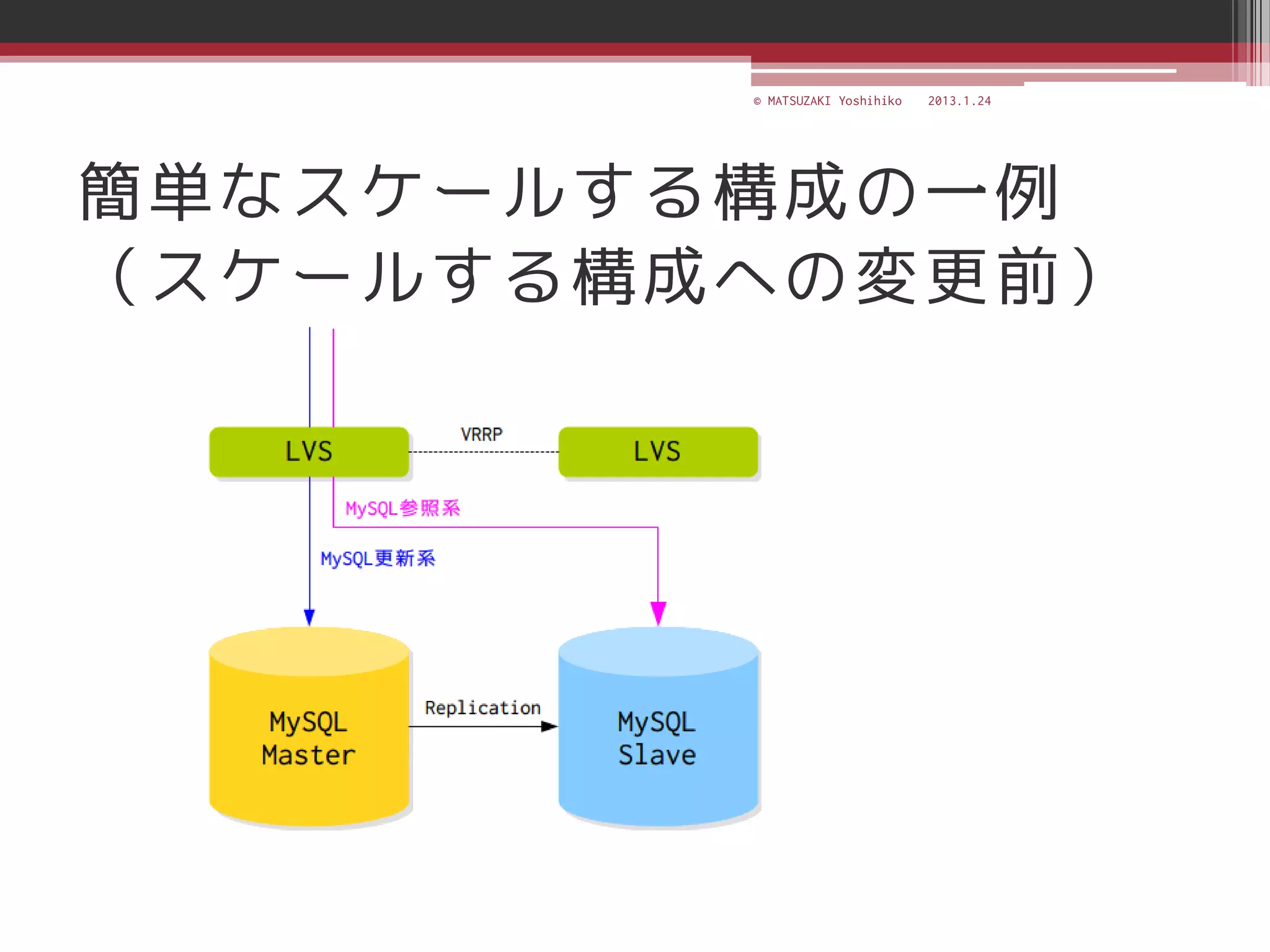
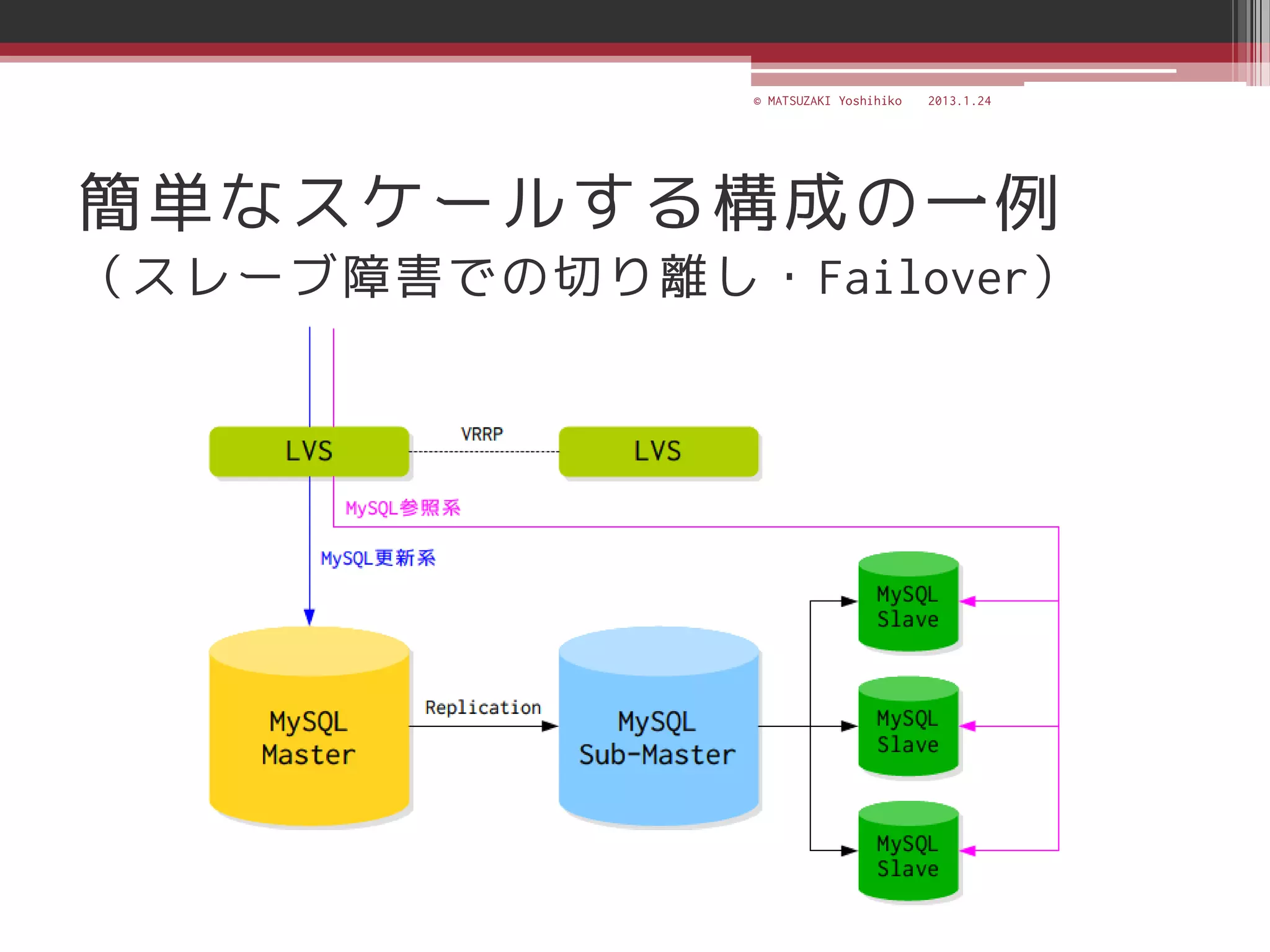
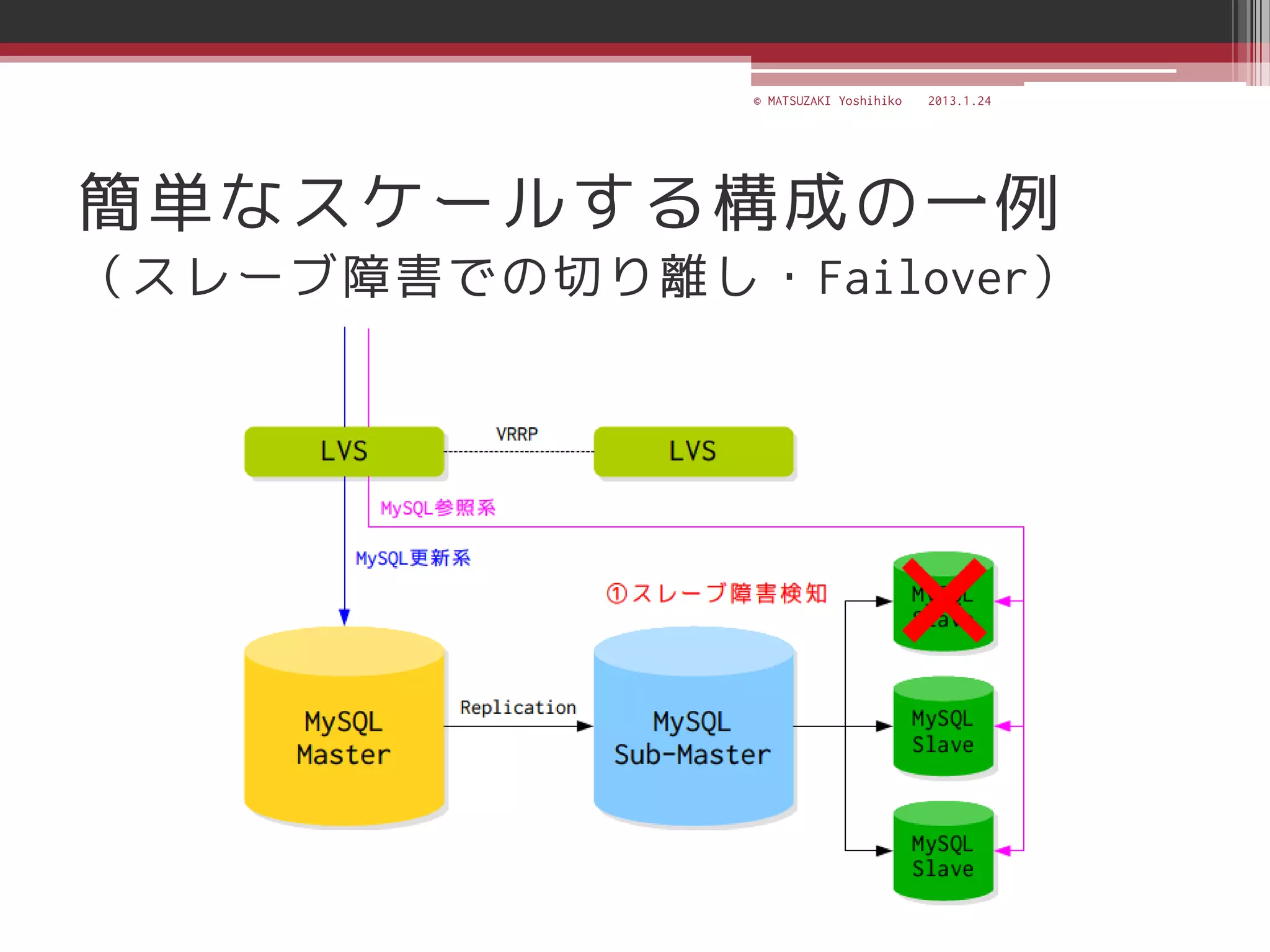
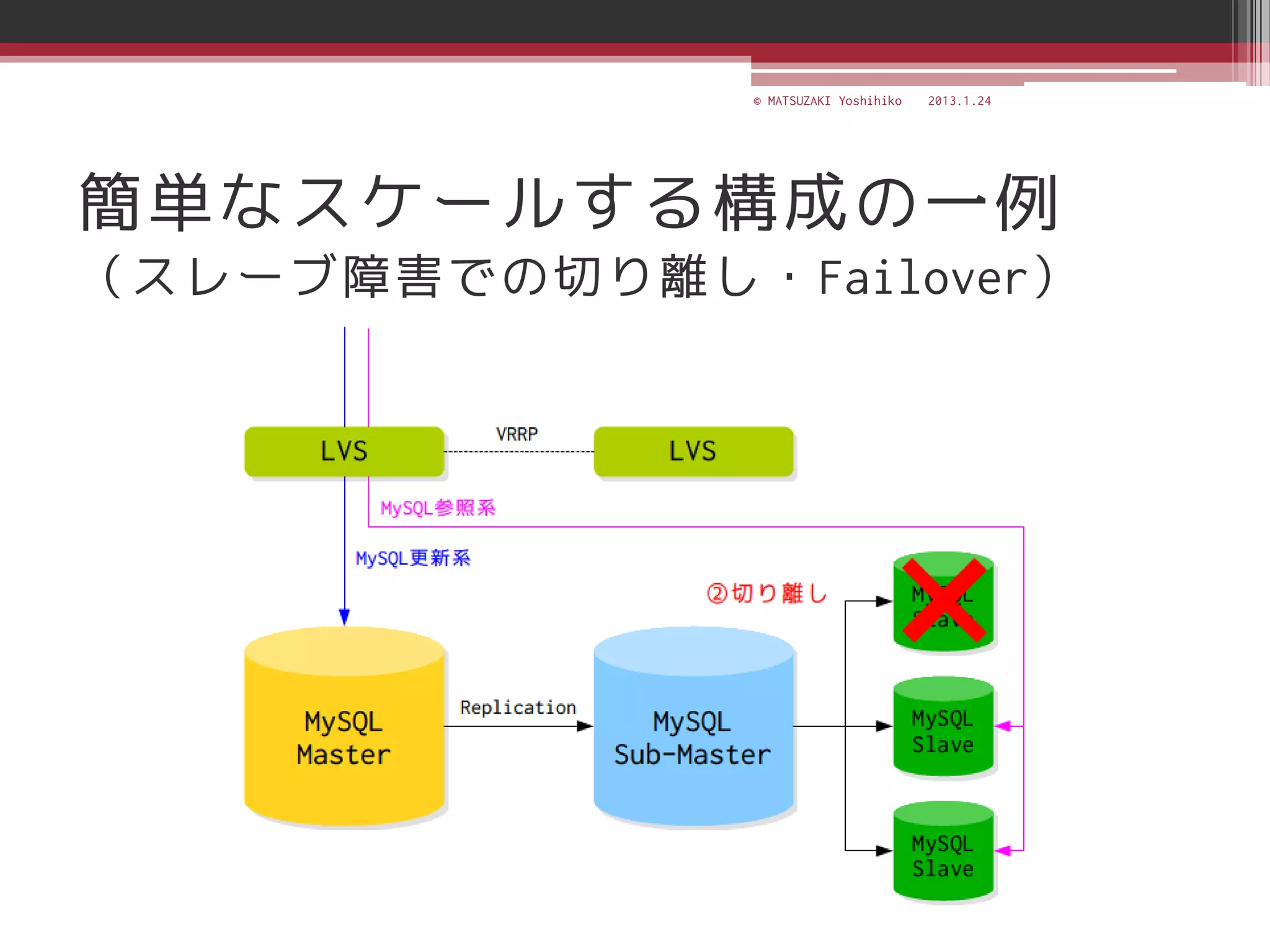
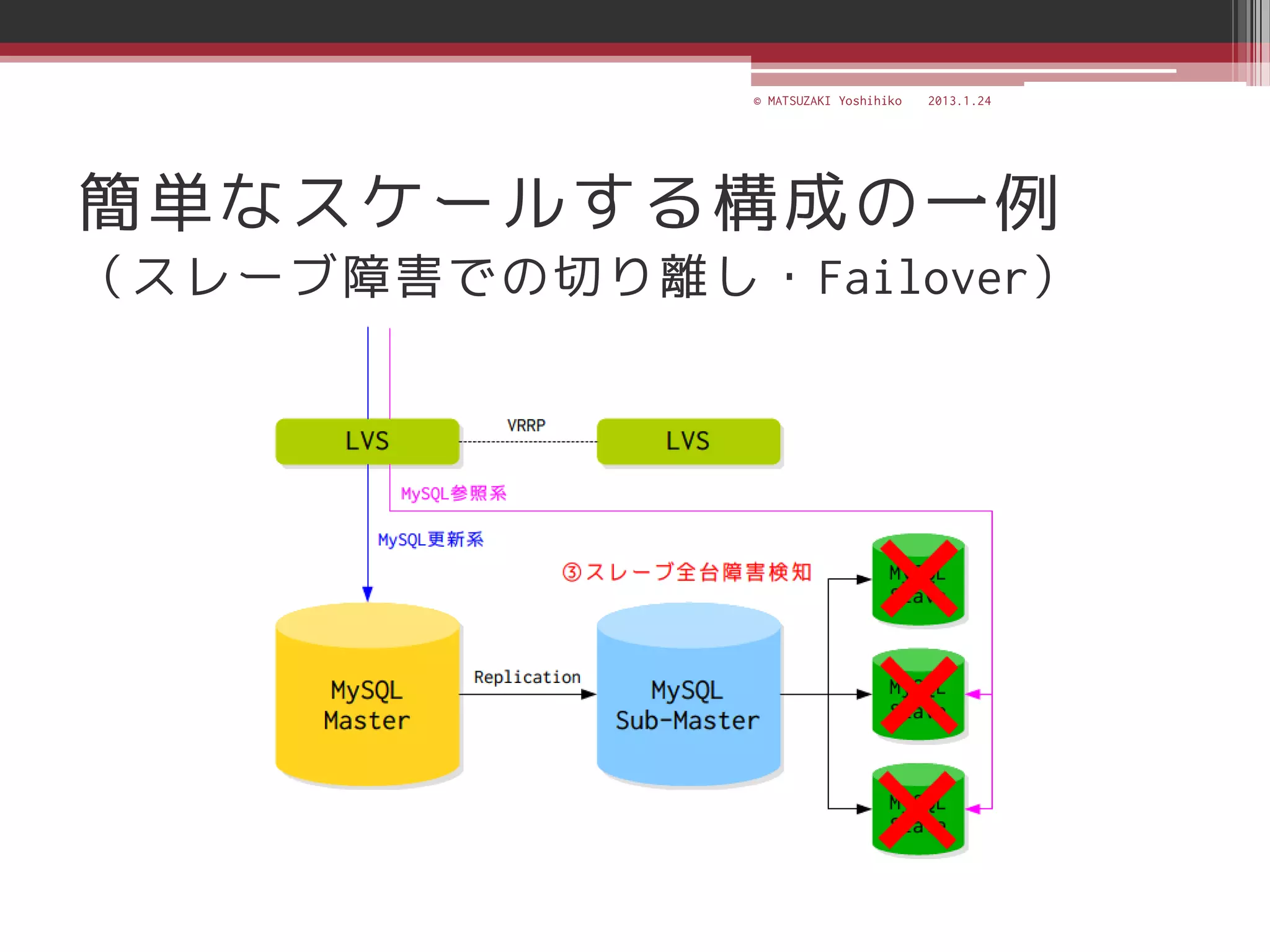


























































![[C21] MySQL Cluster徹底活用術 by Mikiya Okuno](https://cdn.slidesharecdn.com/ss_thumbnails/c21mysql-cluster-techniques-rev3-131206023325-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












