Download as PDF, PPTX



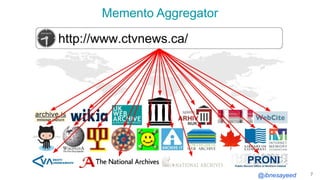
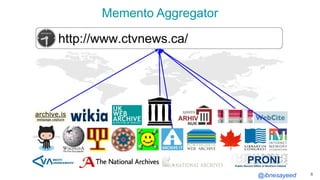
![@ibnesayeed
Broadcasting is Evil
9
From: Michael Nelson [mailto:mln@cs.odu.edu]
Sent: Wednesday, December 02, 2015 12:33 PM
To: Jones, Gina
Cc: Rourke, Patrick; Grotke, Abigail
Subject: Re: WebSciDL
Hi Gina, I'll investigate. memgator is software that one my students wrote, but I suspect the
traffic you're seeing is b/c it is deployed in http://oldweb.today/ can you share the IP
addr from where you're seeing the traffic? I presume the requests are for Memento
TimeMaps? It should not being actually scraping HTML pages.
regards,
Michael
On Wed, 2 Dec 2015, Jones, Gina wrote:
> Hi Michael, we have a slight configuration issue with the current OW
> set up for our webarchives. I think, from looking at the logs, that
> "MemGator:1.0-rc3 <@WebSciDL>" is really causing some issues on our wayback.
> Do you know who is running this scraper? Itʼs not part of memento is it?
>
> Gina Jones
> Web Archiving Team
> Library of Congress
From: Ilya Kreymer <ikreymer@gmail.com>
Date: Wed, 2 Dec 2015 10:33:56 -0800
Subject: high traffic on oldweb!
To: Herbert Van de Sompel <hvdsomp@gmail.com>, Sawood Alam
<ibnesayeed@gmail.com>
Hi Herbert, Sawood,
Herbert: Perhaps you are lucky that I am not using the LANL aggregator, as the traffic has
gotten really high, and also I was asked to remove an archive due to the traffic it was
causing temporarily..
I am thinking that ability to remove source archives quickly is an important aspect of an
aggregator.
Sawood: Hopefully yours will support something like this so I don't need to restart the
container to change the archivelist ;)
Ilya
Broadcasting is wasteful, both clients & archives suffer!](https://image.slidesharecdn.com/mementomap-jcdl2019-190604154906/85/MementoMap-Framework-for-Flexible-and-Adaptive-Web-Archive-Profiling-9-320.jpg)
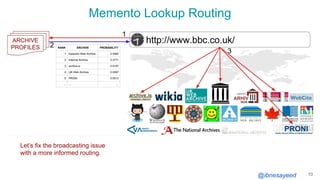

![@ibnesayeed
A MementoMap Example
14
!context ["http://oduwsdl.github.io/contexts/ukvs"]
!id {uri: "http://archive.example.org/"}
!fields {keys: ["surt"], values: ["frequency"]}
!meta {type: "MementoMap", name: "A Test Web Archive", year: 1996}
!meta {updated_at: "2018-09-03T13:27:52Z"}
* 54321/20000
com,* 10000+
org,arxiv)/ 100
org,arxiv)/* 2500~/900
org,arxiv)/pdf/* 0
uk,co,bbc)/images/* 300+/20-
https://github.com/oduwsdl/ORS/blob/master/ukvs.md](https://image.slidesharecdn.com/mementomap-jcdl2019-190604154906/85/MementoMap-Framework-for-Flexible-and-Adaptive-Web-Archive-Profiling-14-320.jpg)
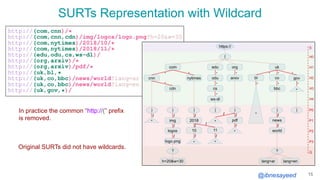
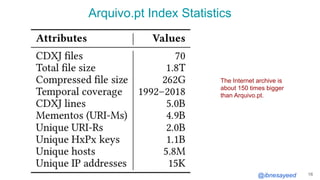
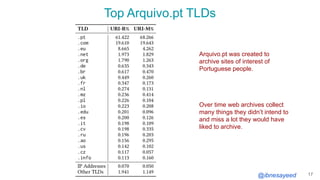
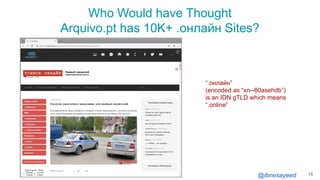
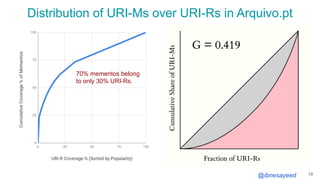
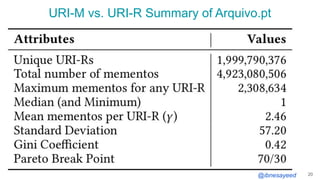
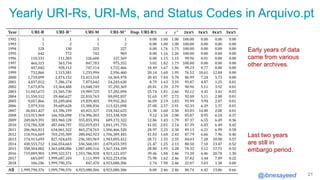
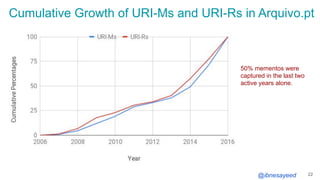

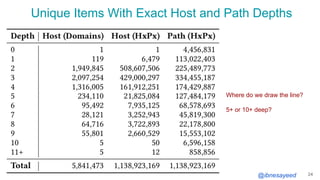
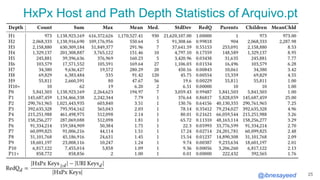
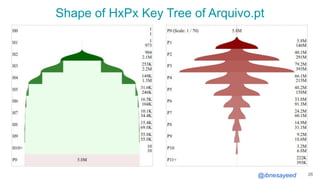
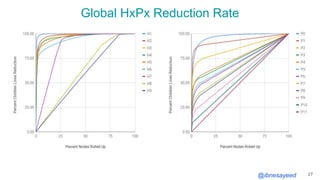
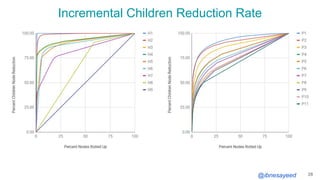
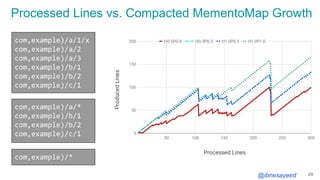





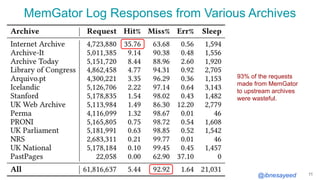
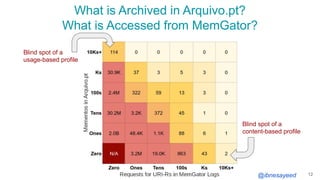
The document presents the MementoMap framework designed for flexible and adaptive web archive profiling, discussing its implementation and efficiency in reducing wasted traffic from web archives like arquivo.pt. It introduces MementoMap as a solution to enhance archive profiling by generating a summary file that can significantly reduce unnecessary requests, plus future work suggestions for broader implementation. The framework's effectiveness is validated through analysis of the index of arquivo.pt, demonstrating a potential 60% reduction in wasted traffic with minimal overhead.




























































