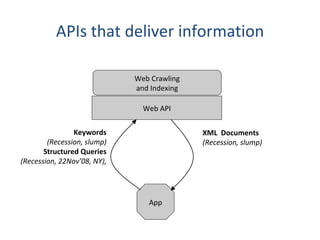
Web crawling involves automated programs called crawlers or spiders that browse the web methodically to index web pages for search engines. Crawlers start from seed URLs and extract links from visited pages to discover new pages, repeating the process until a desired size or time limit is reached. Crawlers are used by search engines to build indexes of web content and ensure freshness through revisiting URLs. Challenges include the web's large size, fast changes, and dynamic content generation. APIs allow programmatic access to web services and information through REST, HTTP POST, and SOAP.