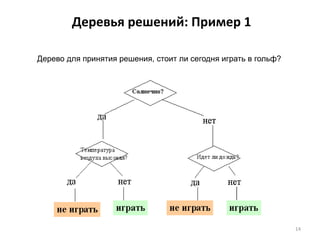
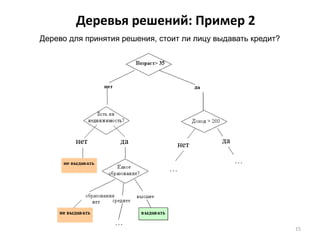
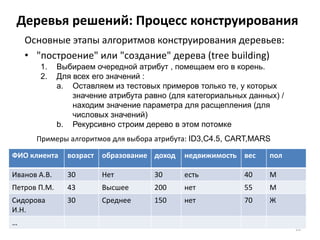
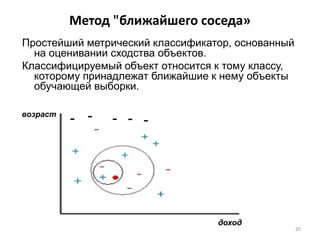
Документ подробно рассматривает интеллектуальный анализ данных (data mining), его историю, методы и области применения. Основное внимание уделяется деревьям решений и методу 'ближайшего соседа', их преимуществам и недостаткам, а также примерам применения в различных сферах, таких как розничная торговля, банковское дело и телекоммуникации. Также обсуждаются проблемы и перспективы развития технологии data mining и важные аспекты подготовки данных.