Download to read offline




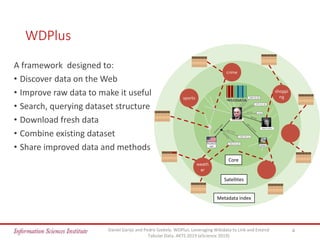
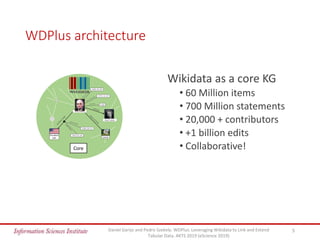
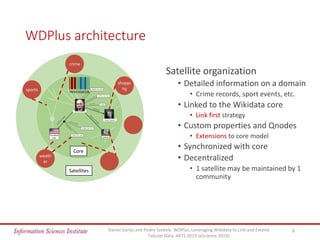
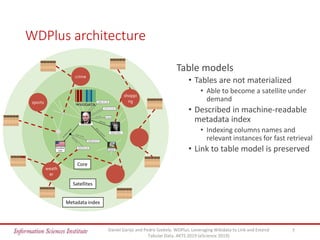
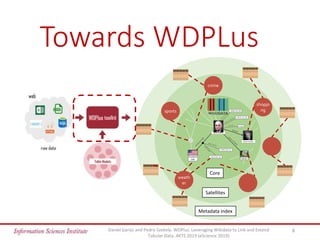






The document discusses the wdplus framework, which aims to leverage Wikidata for enhancing and linking tabular data. It addresses challenges related to discovering, augmenting, and sharing datasets, while outlining architectural features such as a metadata index and collaborative contributions. The framework also proposes solutions for improving the usability of tabular data through automated processes and community involvement.


































































