Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Masashi Shibata
17,469 views
pandasによるデータ加工時の注意点やライブラリの話
PyCon JP 2015 Lightning Talk
Technology
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 13
2
/ 13
3
/ 13
4
/ 13
5
/ 13
6
/ 13
7
/ 13
8
/ 13
9
/ 13
10
/ 13
11
/ 13
12
/ 13
13
/ 13
More Related Content
PDF
sqldf for pandas
by
airtoxin Ishii
PDF
pysqldf
by
airtoxin Ishii
PDF
知って得するWebで便利なpostgre sqlの3つの機能
by
Soudai Sone
PDF
今すぐ使えるクラウドとPostgreSQL
by
Soudai Sone
PPTX
組合せ最適化を体系的に知ってPythonで実行してみよう PyCon 2015
by
SaitoTsutomu
PPTX
Tokyo Webmining #12 Hapyrus
by
Koichi Fujikawa
PDF
パッケージングの今と未来
by
Atsushi Odagiri
PDF
Postgre sqlから見るnosql
by
Soudai Sone
sqldf for pandas
by
airtoxin Ishii
pysqldf
by
airtoxin Ishii
知って得するWebで便利なpostgre sqlの3つの機能
by
Soudai Sone
今すぐ使えるクラウドとPostgreSQL
by
Soudai Sone
組合せ最適化を体系的に知ってPythonで実行してみよう PyCon 2015
by
SaitoTsutomu
Tokyo Webmining #12 Hapyrus
by
Koichi Fujikawa
パッケージングの今と未来
by
Atsushi Odagiri
Postgre sqlから見るnosql
by
Soudai Sone
What's hot
PDF
PostgreSQLレプリケーション(pgcon17j_t4)
by
Kosuke Kida
PDF
パッケージングの今と未来
by
Atsushi Odagiri
PDF
Pythonはどうやってlen関数で長さを手にいれているの?
by
Takayuki Shimizukawa
PDF
PostgreSQLでスケールアウト
by
Masahiko Sawada
PPT
クラウド時代の並列分散処理技術
by
Koichi Fujikawa
PDF
Oratopostgres-hiroshima
by
Kosuke Kida
PDF
pythonでオフィス快適化計画
by
Kazufumi Ohkawa
PDF
OSC北海道2014_JPUG資料
by
Chika SATO
PDF
DDDハンズオン
by
Soudai Sone
PDF
実務で役立つデータベースの活用法
by
Soudai Sone
PDF
Web エンジニアが postgre sql を選ぶ 3 つの理由
by
Soudai Sone
PDF
PythonによるWebスクレイピング入門
by
Hironori Sekine
PDF
Chugokudb18_1
by
Kosuke Kida
PDF
パッケージングの今
by
Atsushi Odagiri
PDF
ldapvi & python-ldap で stress-free life
by
Kouhei Maeda
PDF
PostgreSQLとpython
by
Soudai Sone
PDF
商用DBからPostgreSQLへ まず知っておいて欲しいまとめ
by
Kosuke Kida
PDF
機械学習モデルフォーマットの話:さようならPMML、こんにちはPFA
by
Shohei Hido
PDF
形態素解析器 MeCab の新語・固有表現辞書 mecab-ipadic-NEologd のご紹介
by
Toshinori Sato
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
PostgreSQLレプリケーション(pgcon17j_t4)
by
Kosuke Kida
パッケージングの今と未来
by
Atsushi Odagiri
Pythonはどうやってlen関数で長さを手にいれているの?
by
Takayuki Shimizukawa
PostgreSQLでスケールアウト
by
Masahiko Sawada
クラウド時代の並列分散処理技術
by
Koichi Fujikawa
Oratopostgres-hiroshima
by
Kosuke Kida
pythonでオフィス快適化計画
by
Kazufumi Ohkawa
OSC北海道2014_JPUG資料
by
Chika SATO
DDDハンズオン
by
Soudai Sone
実務で役立つデータベースの活用法
by
Soudai Sone
Web エンジニアが postgre sql を選ぶ 3 つの理由
by
Soudai Sone
PythonによるWebスクレイピング入門
by
Hironori Sekine
Chugokudb18_1
by
Kosuke Kida
パッケージングの今
by
Atsushi Odagiri
ldapvi & python-ldap で stress-free life
by
Kouhei Maeda
PostgreSQLとpython
by
Soudai Sone
商用DBからPostgreSQLへ まず知っておいて欲しいまとめ
by
Kosuke Kida
機械学習モデルフォーマットの話:さようならPMML、こんにちはPFA
by
Shohei Hido
形態素解析器 MeCab の新語・固有表現辞書 mecab-ipadic-NEologd のご紹介
by
Toshinori Sato
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
More from Masashi Shibata
PDF
MLOps Case Studies: Building fast, scalable, and high-accuracy ML systems at ...
by
Masashi Shibata
PDF
実践Djangoの読み方 - みんなのPython勉強会 #72
by
Masashi Shibata
PDF
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
by
Masashi Shibata
PDF
サイバーエージェントにおけるMLOpsに関する取り組み at PyDataTokyo 23
by
Masashi Shibata
PDF
Implementing sobol's quasirandom sequence generator
by
Masashi Shibata
PDF
DARTS: Differentiable Architecture Search at 社内論文読み会
by
Masashi Shibata
PDF
Goptuna Distributed Bayesian Optimization Framework at Go Conference 2019 Autumn
by
Masashi Shibata
PDF
PythonとAutoML at PyConJP 2019
by
Masashi Shibata
PDF
Djangoアプリのデプロイに関するプラクティス / Deploy django application
by
Masashi Shibata
PDF
Django REST Framework における API 実装プラクティス | PyCon JP 2018
by
Masashi Shibata
PDF
Django の認証処理実装パターン / Django Authentication Patterns
by
Masashi Shibata
PDF
RTMPのはなし - RTMP1.0の仕様とコンセプト / Concepts and Specification of RTMP
by
Masashi Shibata
PDF
システムコールトレーサーの動作原理と実装 (Writing system call tracer for Linux/x86)
by
Masashi Shibata
PDF
Golangにおける端末制御 リッチなターミナルUIの実現方法
by
Masashi Shibata
PDF
How to develop a rich terminal UI application
by
Masashi Shibata
PDF
Introduction of Feedy
by
Masashi Shibata
PDF
Webフレームワークを作ってる話 #osakapy
by
Masashi Shibata
PDF
Pythonのすすめ
by
Masashi Shibata
PDF
Pythonistaのためのデータ分析入門 - C4K Meetup #3
by
Masashi Shibata
PDF
テスト駆動開発入門 - C4K Meetup#2
by
Masashi Shibata
MLOps Case Studies: Building fast, scalable, and high-accuracy ML systems at ...
by
Masashi Shibata
実践Djangoの読み方 - みんなのPython勉強会 #72
by
Masashi Shibata
CMA-ESサンプラーによるハイパーパラメータ最適化 at Optuna Meetup #1
by
Masashi Shibata
サイバーエージェントにおけるMLOpsに関する取り組み at PyDataTokyo 23
by
Masashi Shibata
Implementing sobol's quasirandom sequence generator
by
Masashi Shibata
DARTS: Differentiable Architecture Search at 社内論文読み会
by
Masashi Shibata
Goptuna Distributed Bayesian Optimization Framework at Go Conference 2019 Autumn
by
Masashi Shibata
PythonとAutoML at PyConJP 2019
by
Masashi Shibata
Djangoアプリのデプロイに関するプラクティス / Deploy django application
by
Masashi Shibata
Django REST Framework における API 実装プラクティス | PyCon JP 2018
by
Masashi Shibata
Django の認証処理実装パターン / Django Authentication Patterns
by
Masashi Shibata
RTMPのはなし - RTMP1.0の仕様とコンセプト / Concepts and Specification of RTMP
by
Masashi Shibata
システムコールトレーサーの動作原理と実装 (Writing system call tracer for Linux/x86)
by
Masashi Shibata
Golangにおける端末制御 リッチなターミナルUIの実現方法
by
Masashi Shibata
How to develop a rich terminal UI application
by
Masashi Shibata
Introduction of Feedy
by
Masashi Shibata
Webフレームワークを作ってる話 #osakapy
by
Masashi Shibata
Pythonのすすめ
by
Masashi Shibata
Pythonistaのためのデータ分析入門 - C4K Meetup #3
by
Masashi Shibata
テスト駆動開発入門 - C4K Meetup#2
by
Masashi Shibata
Recently uploaded
PDF
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
PDF
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
PDF
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
PDF
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
PPTX
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
20251210_MultiDevinForEnterprise on Devin 1st Anniv Meetup
by
Masaki Yamakawa
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #2
by
Tasuku Takahashi
流行りに乗っかるClaris FileMaker 〜AI関連機能の紹介〜 by 合同会社イボルブ
by
Evolve LLC.
Machine Tests Benchmark Suite. Explain github.com/alexziskind1/machine_tests #1
by
Tasuku Takahashi
エンジニアが選ぶべきAIエディタ & Antigravity 活用例@ウェビナー「触ってみてどうだった?Google Antigravity 既存IDEと...
by
NorihiroSunada
楽々ナレッジベース「楽ナレ」3種比較 - Dify / AWS S3 Vector / Google File Search Tool
by
Kiyohide Yamaguchi
pandasによるデータ加工時の注意点やライブラリの話
1.
pandas によるデータ加工時の 注意点やライブラリの話 Masashi Shibata October
10 2015, PyCon JP 2015
2.
@c_bata_ 明石高専 専攻科 akashi.py 主催 PyCon
APAC/Taiwan 2015 BePROUD で Django 研究で pandas ← 今日はこれ
3.
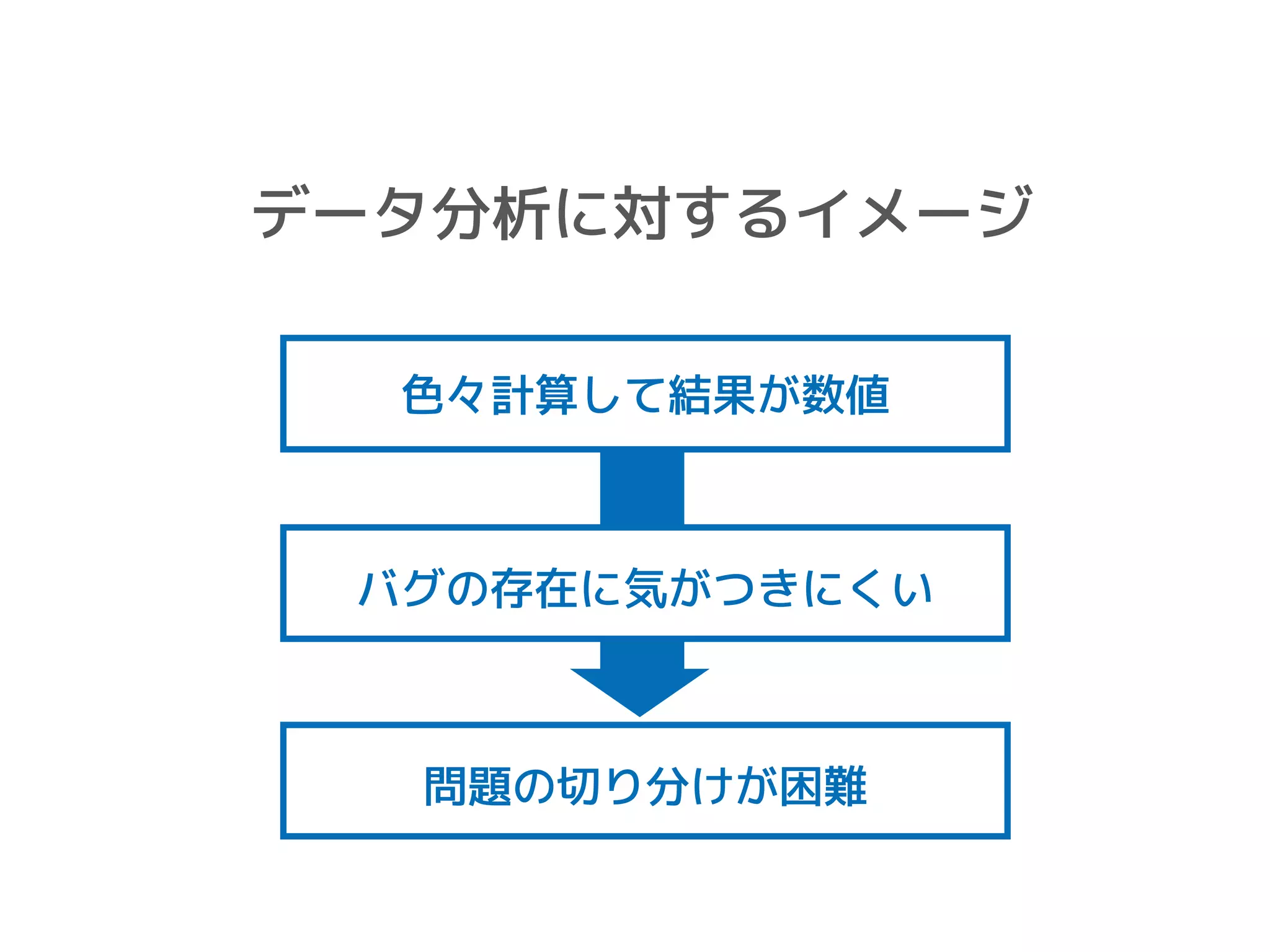
データ分析に対するイメージ 色々計算して結果が数値 問題の切り分けが困難 バグの存在に気がつきにくい
4.
ユニットテスト 最低限、テストに記述された振舞いは満たすはず ある程度、怪しい箇所の予測ができそう
5.
それでもおかしい テストケースに漏れがある? デバッガを使ってみたけど原因は分からず
6.
テストケースに漏れがある? デバッガを使ってみたけど原因は分からず それでもおかしい 対象データの一部に変な値が混ざってた
7.
何故気づけなかったのか フィクスチャデータと実データは違う ユニットテストの限界 大量の入力ファイル デバッガの限界
8.
pandas-validator https://github.com/c-bata/pandas-validator $ pip install
pandas_validator
9.
使い方 import pandas_validator as
pv class SampleDataFrameValidator(pv.DataFrameValidator): row_num = 20 axis_x = pv.IntegerColumnValidator('axis_x', min_value=0, max_value=10) axis_y = pv.IntegerColumnValidator('axis_y', min_value=0, max_value=10) speed = pv.FloatColumnValidator('speed', min_value=0) pressure = pv.FloatColumnValidator('pressure', min_value=0, max_value=1) validator = SampleDataFrameValidator()
10.
使い方 import pandas as
pd df = pd.DataFrame({ 'axis_x': [6, 5, 6, 3, 4, ...], 'axis_y': [3, 2, 5, 1, 9, ...], 'speed': [3.2, 3.5, 3.3, 3.7, 3.2, ...], 'pressure': [0.2, 0.2, 0.1, 0.7, 0.6, ...] }) validator.is_valid(df) # True.
11.
わかったこと ユニットテストやデバッガでは検出が困難 DataFrame はイレギュラーな値を許容 データが正しいとは限らない
12.
今後やりたいこと DataFrame の構造を明示的に記述 Django のように
Fixture データの生成など
13.
Sprint! with @sinhrks pandas コードリーディング PR
を送っていこう
Download









![使い方
import pandas as pd
df = pd.DataFrame({
'axis_x': [6, 5, 6, 3, 4, ...],
'axis_y': [3, 2, 5, 1, 9, ...],
'speed': [3.2, 3.5, 3.3, 3.7, 3.2, ...],
'pressure': [0.2, 0.2, 0.1, 0.7, 0.6, ...]
})
validator.is_valid(df) # True.](https://image.slidesharecdn.com/pyconjp2015lt-151010132936-lva1-app6891/75/pandas-10-2048.jpg)
























































