This Ebook gives an idea about how Big Data has become an indispensable part of any organization, and how exactly it can be tackled using the Various AWS Cloud Components.
HOW TO CLOUDIT BETTER
WITH
BLAZECLAN
A 360 Degree
Cloud Solution
Big Data
Solution
Data Warehouse
on AWS
AWS Boutique
Consulting
Managed Service
On AWS
Application
Development
AWS Infrastructure
Managed with Our 360
Degree Approach
Delivering Scalable,
Reliable & Cost
Effective Applications
on AWS Cloud
Unleash the Potential
of Your Data with
AWS Cloud
AWS Consulting
Tailor Made for your
Business Needs
Making Amazon Redshift
work as your Data Warehouse
Solution
Request a 2HR
Consultation FREE
3.
KINESIS REDSHIFT
EMR
DYNAMO DB
Writtenby Varoon Rajani | Designed & Compiled by Neil
Varoon D. Rajani
Founder & President
Cloud Consulting
With more than 10 Years of Experience in
Designing and Developing Enterprise Database
Solutions Varoon is an AWS Certified Solution
Architect & Product Manager for Cloudlytics, a
Big Data SaaS Solution built using AWS
Components.
His Passion lies in Cloud Computing with an
Entrepreneurial Zest for Adventure!
A Digital Marketing Strategist born in
the Clouds. Neil Manages the 4
Essential Elements of the Digital
Space – Content, Analytics, Social &
Leads for BlazeClan.
In his spare time he questions
philosophies & Strums his Guitar!
Nilotpal (Neil) Roy
Digital Marketing
Strategist
4.
KINESIS REDSHIFT
EMR
DYNAMO DB
CONTENTS
WhyAll the Buzz & the Fuzz about Big Data?
Why is Cloud Big Data’s Best Friend?
Four Major Challenges of Big Data you can’t Ignore
The Big Data Life Cycle
How AWS Components Fit in the Big Data
Life Cycle (Transfer, Storage & Databases)
Hadoop in the Clouds using AWS’s EMR
What are the Big Opportunities with Big Data?
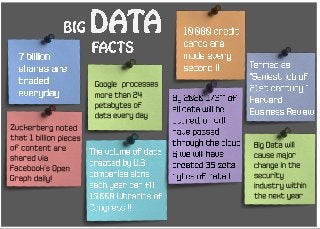
Some Interesting Big Data Facts
1.
2.
3.
4.
5.
6.
7.
8.
9. Big Data use cases across various Verticals
KINESIS REDSHIFT
EMR
DYNAMO DB
AJump Start Guide to Big Data on AWS Cloudl6
Well, as you finish reading this Sentence, more than 49k Tweets will have
been chirped, 168000k Emails Bombarded, 350k Facebook Statuses
Fired, 600+ YouTube Videos uploaded and so on, in the virtual space.
Check the Big Data Fact Sheet for more of these Facts!
Big Data simply put is data, which cannot be processed by the current tools &
technologies that we possess. So is Big Data something new? Well No, Big Data existed
since long back, where companies like Google had the resources to process & Analyze it.
But with the Evolution of Cloud computing, Open Source Frameworks & lowering of
Hardware Costs these resources to process Big Data are now available to independent
small businesses, startups & even individuals.
So what if I don’t have to tackle millions of DNA strands or monitor the fluctuations in the
Stock market, do I still need Big Data? Even If I have a small business? Well the answer
isn’t a straight forward yes, but imagine……
Is the Big Data Story Really that Big…
7.
KINESIS REDSHIFT
EMR
DYNAMO DB
Ifyour newly launched product feature created a buzz on social, with thousands
of Statuses & Tweets being Fired across the Globe (yes it does happen), won’t it
be amazing if you could track all of those in a sentiment analysis & gather
more insight into your customers? In today’s ever changing world the
only way to stay ahead of the pack is to predict & react to the
change even before it happens. For your business to do this,
a continuous feedback loop of human & machine generated
data needs to be processed. Well that, in effect is nothing
but cracking Big Data!
After web 2.0 & the explosion of the internet almost all the
data generated in these feedback loops are from the virtual
world, like sampling surveys, feedback forms, device/mobile
sensors and many more. With these mountains of data piling up,
the irritating feeling at the back of your head can be summed up in
three words. Volume, Velocity & Variety. These are the 3V’s of the Big
Data challenge. Let’s look at these 3Vs a bit more in detail.
A Jump Start Guide to Big Data on AWS Cloudl7
What to Expect?
8.
KINESIS REDSHIFT
EMR
DYNAMO DB
The3 Vs - VOLUME
Everyday a total of 2.5 quintillion bytes (Exabyte) are flooding into the virtual
world! And by all probability by the time you finish reading this Ebook the
number would have already exceeded by a few Exabytes! Imagine the
Growth since year 2000 when only 800,000 PB(Petabytes) of Data was
Stored Globally. Having trouble switching between all the Gigas, Petas
& Exas? Well there is a simple conversion; we all know that 1kb is
roughly1000 bytes. So all the units of measurement that follow are
Mega<Giga< Tera<Peta<Exa< Zetta< Yotta<Bronto<Geo
with the suffix byte attached to them, where each unit is
roughly 1000 times the previous unit.
So just to put things into perspective, every two days we create as
much Information as we did from the Dawn of civilization until 2003!
This volume cannot be handled by the traditional IT systems with data
processed in batches; it could take weeks. But today data can be processed in
massively parallel architectures, the MapReduce framework that was introduced by
Google, has played a major role in evolving the parallel architecture used in Big Data Analytics.
A Jump Start Guide to Big Data on AWS Cloudl8
9.
KINESIS REDSHIFT
EMR
DYNAMO DB
BigData is generated from social networks, various sensors
installed at store entrances, traffic lights, in airplanes, Car GPS
and countless other sources. All of this data is in varied
formats, sometimes not digestible by the existing
systems in their current form.
These variations in the formats
make it differ from the way current
systems store the data, which is
stored in a well-defined schema
in a Relational Database. All the
data fits in nicely and is easy to
understand and analyze. These
systems with static schemas
cannot handle variety.
The success of the organization depends
on analyzing the data in variety of formats
and make business sense out of it. Big Data
processing helps organizations to take this
unstructured data and extract meaningful information,
which can be processed by humans or structured databases.
The 3 Vs - VARIETY
A Jump Start Guide to Big Data on AWS Cloudl9
10.
KINESIS REDSHIFT
EMR
DYNAMO DB
TheVelocity with which this data is generated is phenomenal & makes
it virtually impossible for the conventional systems to handle it. Twitter
& Facebook generate around 5 GBs and 7 Giga Bytes of data per
minute respectively. There are numerous other organizations which
generate data at equally faster rates. The current technologies may
allow storing this streaming data,
but the challenge lies in analyzing
this data while still in flow and to
make business sense out of it.
Organizations looking for competitive
advantage over each other
therefore want this analysis done in
seconds or even micro seconds,
faster than their competitors.
For example, consider the case of
financial markets where a fraction
of a second can help organizations
make enormous profits. This Need for Speed has led to development of
various Big Data streaming technologies and fast retrieval technologies
like the key-value stores and columnar databases for static data.
The 3 Vs - VELOCITY
A Jump Start Guide to Big Data on AWS Cloudl10
11.
KINESIS REDSHIFT
EMR
DYNAMO DB
TheNew Vs- VERACITY
Big Data Veracity here would
refer to the biases, noise and
abnormality in data. This might
raise a question of whether the
data that is being stored, and
mined meaningful to the
problem being analyzed.
The answer to it would be that
veracity in data analysis is the
biggest challenge when
compares to things like volume
and velocity.
In scoping out your big data
strategy you need to have your
team and partners work to help
keep your data clean and
processes to keep ‘dirty data’
from accumulating in your
systems.
A Jump Start Guide to Big Data on AWS Cloudl11
12.
KINESIS REDSHIFT
EMR
DYNAMO DB
TheNew Vs- VALIDITY & VOLATILITY
Like big data veracity is the issue of validity
meaning is the data correct and accurate for
the intended use. Clearly valid data is the
key to making the right decisions.
The Big data volatility refers to how long is
data valid and how long should it be stored.
In this world of real time data you need to
determine at what point is data no longer
relevant to the current analysis. Big data
clearly deals with issues beyond volume,
variety and velocity to other concerns like
veracity, validity and volatility.
A Jump Start Guide to Big Data on AWS Cloudl12
KINESIS REDSHIFT
EMR
DYNAMO DB
DeployingHadoop Clusters is Not Easy!
Before we look into this question we need to understand the
criticality of a Big Data requirement in the various industry
verticals. A research survey by Gartner in 2011 showed how
there is dramatic rise in data generation as compared
to data available for analysis, which means that
more and more data is flowing out unchecked.
Gone are those days of sampling from
a data set to predict trends. The new
age is a Data Driven one, where
the schemas to tackle business
processes are now being built on
Data.
With the 3Vs of Data kicking in,
larger data sets have to be monitored
& analyzed through different parameters
for results that can truly drive business
decisions. To tackle data in larger & faster flux
through a wide variety of mediums organizations
need a ton of tools, resources, finances & time. Even to
Set up a Big Data infrastructure may take weeks. You will need
a mix of both Infrastructure/hardware scale as well as the
software/platforms/ecosystems set up, and then maintained
over a period of Time.
A Jump Start Guide to Big Data on AWS Cloudl17
18.
KINESIS REDSHIFT
EMR
DYNAMO DB
Sohere, we come across a few
challenges some of which you might
have already identified:
Infrastructure Challenge in terms of
Storage & Compute Elements.
Software Challenge in terms of choosing,
configuring & maintaining Platforms &
ecosystems
Man Power challenge of pooling talented
data scientists for setting up &
maintaining
Time challenge of setting up a Big Data
infrastructure & then managing it.
Tons of maintenance issues starting from
cooling machineries to patching up codes &
updates.
Inelastic capacities, meaning you lose out
on real time data during peak times of
business & pay for capacity you are not
using for the rest of the year.
What are the Challenges?
A Jump Start Guide to Big Data on AWS Cloudl18
19.
KINESIS REDSHIFT
EMR
DYNAMO DB
TheFigure above shows how Cloud-Based
infrastructure gives your Data wizards the
majority of their time in actually putting their Big
Data findings to use and innovate.
So where does Cloud come into the picture? Well, all
the above issues can seamlessly be solved when
you’re on the Cloud. We define Cloud computing
through
its various benefits, like:
• Elasticity
• Pay per use
• Unlimited Scale
• Managed Services
How to Overcome these Challenges?
A Jump Start Guide to Big Data on AWS Cloudl19
If you think about it, these help us in just
the right way to deal with our Big Data
conundrums!
Now you can Collect, Store, Analyze & Share
(The Big Data lifecycle which we will talk
about in a later chapter) your Big Data
findings.
Also you pay for just the resources you use
for the time that you use it for.
20.
KINESIS REDSHIFT
EMR
DYNAMO DB
Arecent Study by IDC showed that
“Over the next decade, the number
of files or containers that
encapsulate the information in the
digital universe will grow by 75x.”
While the pool of IT Staff available
to manage them will grow only
slightly at 1.5x”. This fact
materializes our growing fear. If all
our Data Scientists are busy setting
up & managing Big Data systems,
then it leaves very less time to
actually work with the findings and
drive innovation.
Software / Hardware Conundrums?
A Jump Start Guide to Big Data on AWS Cloudl20
What about the Software/ Hardware Conundrums?
We need flexible language choices with easy programming models which are designed for
distribution. Also you would need platforms for abstraction & an apt ecosystem. Hadoop is the
great example for the software aspect whereas Cloud Computing is just the right fit for your
hardware needs. So wouldn’t it be great if you had something like Hadoop in the Clouds? Well
we have something just like that in AWS Cloud which we will discuss in the later chapters.
KINESIS REDSHIFT
EMR
DYNAMO DB
BusinessDecision makers everywhere yearn for the right
information that would help them make informed decisions.
30 years back business heads had a challenge of
collecting enough data to make informed decisions. Today,
the tables have turned, where they have so much data
that it is impossible to make sense out of it!
Big Data is helping organizations of all sizes
to make better business decisions, save costs,
improve customer service, deliver better user
experience, and identify security risks among
other things. We read about Big Data
everywhere; we listen to it from experts
everywhere; even governments are talking
about it. So what are these 4 challenges that
we need to consider?
• Ownership
• Data
• People
• Technology
Challenges of Big Data
A Jump Start Guide to Big Data on AWS Cloudl22
23.
KINESIS REDSHIFT
EMR
DYNAMO DB
WhoOwns the Data?
Big Data is not a technology initiative, but a business
one. The Big Data initiative has to be driven by the
leaders of the organization, be it Business Heads or
CXOs. It can help an organization to improve
operational predictability, increase sales and improve
customer service among other things. These outcomes
of the initiative have to be identified and articulated by
the Business heads.
Additionally, the procedural and in certain cases
structural changes brought in by Big Data have to be
managed carefully. Organizations do not change easily
and not everyone may appreciate the value brought to
the table with advanced analytics. This is a typical
organizational challenge that needs to be handled aptly
by the top management. Organizations have to be sure
not to label Big Data just as an IT driven initiative.
A Jump Start Guide to Big Data on AWS Cloudl23
24.
KINESIS REDSHIFT
EMR
DYNAMO DB
HowImportant is the DATA??
The most important aspect for any organization to benefit from
Big Data is the data itself. While there is variety of data
collected by various tools and processes, not all data is
relevant. It is critical for an organization to
identify relevant sources of information
depending on the outcome expected out
of the effort.
For example, say if you want to improve
customer experience on the website,
an example of relevant data would
be log details about the errors
encountered by users while
connecting to your website. In this
case, you may not want to store
or process the log details of successful
connections. Only when there is relevant
data, it can be processed and organized in a
way that provides meaningful insights to the
management to make informed decisions.
A Jump Start Guide to Big Data on AWS Cloudl24
25.
KINESIS REDSHIFT
EMR
DYNAMO DB
WhoCall the Shots?
For any successful Big Data effort there has to be a
team of people with the right skills. As I pointed out
earlier, Big Data is not a technology initiative, and the
skill sets required are not limited to technology. For a
successful Big Data effort, the team should have right
mix of,
Data Scientists: Data scientists with their skills
and expertise help in deriving right statistics and
identifying patterns to correlate variety of data
and bring out meaningful insights.
Technology Experts: Technology Experts who
bring in specific skill sets to drive the technology
that forms the backbone of the Big Data initiative.
The team of technology experts will be able to
identify the right set of software tools and hardware
infrastructure required.
Business Owners: Business owners who can drive the
Big Data effort by defining the outcome of the Big Data
effort and then working with the technology and data
scientist teams to achieve the outcome.
A Jump Start Guide to Big Data on AWS Cloudl25
26.
KINESIS REDSHIFT
EMR
DYNAMO DB
WhatTechnology is at Stake?
Technology forms the backbone for
any Big Data initiative. Technology
components for Big Data would
include,
Hardware Infrastructure:
Organizations need to identify
their needs and plan for
the hardware infrastructure
required for their efforts.
This is why Cloud
Computing is a great option
if you don’t want heavy
investments.
Software tools: You also need to
invest in the right set of tools for collection,
processing and storing of data and for deriving
analytics and visualization of data.
A Jump Start Guide to Big Data on AWS Cloudl26
KINESIS REDSHIFT
EMR
DYNAMO DB
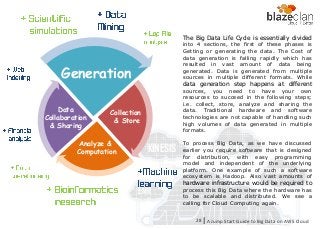
TheBig Data Life Cycle is essentially divided
into 4 sections, the first of these phases is
Getting or generating the data. The Cost of
data generation is falling rapidly which has
resulted in vast amount of data being
generated. Data is generated from multiple
sources in multiple different formats. While
data generation step happens at different
sources, you need to have your own
resources to succeed in the following steps;
i.e. collect, store, analyze and sharing the
data. Traditional hardware and software
technologies are not capable of handling such
high volumes of data generated in multiple
formats.
To process Big Data, as we have discussed
earlier you require software that is designed
for distribution, with easy programming
model and independent of the underlying
platform. One example of such a software
ecosystem is Hadoop. Also vast amounts of
hardware infrastructure would be required to
process this Big Data where the hardware has
to be scalable and distributed. We see a
calling for Cloud Computing again.
Generation
Collection
& Store
Analyze &
Computation
Data
Collaboration
& Sharing
A Jump Start Guide to Big Data on AWS Cloudl28
KINESIS REDSHIFT
EMR
DYNAMO DB
Transferringthe Data
In Order to begin the ETL (Extract, Transfer & Load)
process, you first need to transfer your Data sets onto the
Cloud Storage services. You can do this by using any of
AWS’s Data Transfer services based on your type, size &
criticality of your data. There are 3 main services used,
1. AWS Import/Export:
AWS Import/Export allows you to transfer large amounts
of data into and out of AWS using portable storage
devices that are shipped to AWS data centers directly.
AWS transfers your data directly onto and off of storage
devices using Amazon’s high-speed internal network
bypassing the internet. For significantly large data sets,
AWS Import/Export is often faster option than Internet
transfer and more cost effective than upgrading your
connectivity.
AWS Import/Export
Move large amounts of data into and out of
AWS using portable storage devices for
transport
A Jump Start Guide to Big Data on AWS Cloudl30
31.
KINESIS REDSHIFT
EMR
DYNAMO DB
2.AWS Direct Connect:
AWS Direct Connect makes it easy to establish a dedicated
network connection from your premise directly to AWS. Using
AWS Direct Connect, you can establish private connectivity
between AWS and your datacenter, office, or colocation
environment, which in many cases can reduce your network
costs, increase bandwidth throughput, and provide a more
consistent network experience than Internet-based
connections. 802.1q VLANs, this dedicated connection can be
partitioned into multiple virtual interfaces allowing you to use
the same connection to access both private & public
resources.
3. AWS Storage Gateway:
The AWS Storage Gateway is a service that allows you to
connect your on-premises software appliances with the
cloud-based storage providing a seamless and secure
integration between an organization’s on-premises IT
environment and AWS’s storage infrastructure. The service
allows you to securely store data in the AWS cloud for
scalable and cost-effective storage. There are 3 major types
of storage gateway configurations, and you can select yours
based on the kind of data & operations you want to perform
on them.
AWS Direct Connect
AWS Storage Gateway
Establish a dedicated network
connection from your premises to AWS
Secure Integration between an On-
premises IT & AWS’s storage infrastructure
A Jump Start Guide to Big Data on AWS Cloudl31
Transferring the Data
32.
KINESIS REDSHIFT
EMR
DYNAMO DB
Collectingand Storing the Data
Once the data is Transferred it can be collected & Stored
for analytics. A variety of AWS Resources are present to
help you collect and store information & based on the
type of Data, you can Store it in Simple Storage
Components using AWS's S3 service, relational or NoSQL
database services. The following are the service
components in Detail:
1. AWS Simple Storage Service (S3):
Amazon S3 is storage for the Internet. It is designed to
make web-scale computing easy and reliable. Amazon S3
provides a simple web services interface that can be used
to store and retrieve any amount of data, at any time,
from anywhere on the web. Amazon S3 is an ideal way to
store large amount of data for analysis because of its
reliability and cost effectiveness. Apache Hadoop file
systems can be hosted on S3, as its requirements of a file
system are met by S3. As a result, Hadoop can be used to
run MapReduce algorithms on EC2 servers, reading data
and writing results back to S3.
Simple Storage Service (S3)
Write, read, and delete objects containing
from 1 byte to 5 terabytes of data each.
A Jump Start Guide to Big Data on AWS Cloudl32
33.
KINESIS REDSHIFT
EMR
DYNAMO DB
2.Amazon Relational Database Service (RDS):
Amazon RDS is a managed service that makes it easy to
setup, operate and scale a relational database on AWS
infrastructure. AWS RDS currently supports Postgres,
MYSQL, Oracle and MS SQL Server relational database
technologies. If you require a relational database to store
large amount of data, Amazon RDS is a good fit.
3. AWS DynamoDB:
DynamoDB is a fully managed NoSQL database service
by AWS. DynamoDB is a fast, highly reliable and cost-
effective NoSQL database service designed for internet
scale applications. It is designed to provide fast
performance at any scale.
Once you have your Data Stored, it’s time for the
Analysis part which we will cover in the next Chapter.
A full featured relational databases giving you access
to capabilities of a MySQL, Oracle, SQL Server, or
PostgreSQL databases engines
AWS Relational
Database Service (RDS)
A fast, fully managed NoSQL database service
making it simple & cost-effective to store & retrieve
any amount of data, and serve any level of request traffic.
AWS DynamoDB
A Jump Start Guide to Big Data on AWS Cloudl33
Collecting and Storing the Data
34.
KINESIS REDSHIFT
EMR
DYNAMO DB
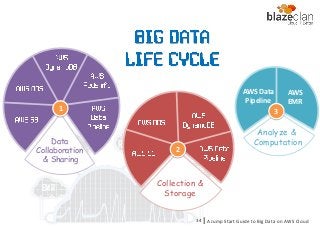
Collection
&Store
Collection &
Storage
Data
Collaboration
& Sharing
Analyze &
Computation
AWS Data
Pipeline
AWS
EMR
A Jump Start Guide to Big Data on AWS Cloudl34
1 3
2
KINESIS REDSHIFT
EMR
DYNAMO DB
Continuingwith the Big Data lifecycle Story, let us get to the
core, i.e. the Analysis section. When we talk about Big Data
one of the First technologies frequently spoken about is
Hadoop, if you want to dive down deep into Hadoop
Technologies, you can refer to this Blog post comparing apache
Hadoop with the other commonly used Hadoop Technologies.
So before we understand what exactly EMR is, let’s keep in
mind that the EMR service basically allows us to automate
Hadoop Processes on AWS Cloud.
So, what is Amazon EMR?
Amazon EMR is a managed Hadoop distribution by Amazon
Web Services. Amazon EMR helps us analyze & process large
amount of data by distributing data computation across
multiple nodes in a cluster on AWS Cloud. It uses a
customized Apache Hadoop framework to achieve large scale
distributed processing of data. Hadoop framework uses
distributed data processing architecture known as MapReduce,
in which a data processing task is mapped to a set of servers
in a cluster for processing. The results of the computation
performed by these servers are reduced to a single output.
Amazon Elastic Map
Reduce (EMR)
A Jump Start Guide to Big Data on AWS Cloudl36
Amazon Cloud’s Managed Hadoop!
37.
KINESIS REDSHIFT
EMR
DYNAMO DB
Allthe open source projects that work with Apache
Hadoop also work seamlessly with Amazon EMR. In
addition to this Amazon EMR is well integrated with
various AWS services like EC2 (Compute Instances
used to launch master and slave nodes),S3 (used as an
alternative to Hadoop Distributed File Systems –HDFS
for Storage), CloudWatch (to monitor jobs on EMR),
Amazon RDS, DynamoDB etc.
Amazon EMR allows you run your custom map-reduce
programs, written in Java. You have the flexibility to
launch any number of EC2 instances with various
server configurations. EMR also allows you to update
the default Hadoop configurations to tune your job
flows (job flow is a set of steps to process a specific
data set using a cluster of EC2 instances) according to
your specific needs. EMR allows writing Bootstrap
actions, which provides a way to run custom set-up
prior to execution your job flow. Bootstrap actions can
be used to install software or configure instances before
running a job flow.
Overall, Amazon EMR provides a simpler and cost
effective way to deploy your own Hadoop cluster
without the overheads of buying and maintaining your
own hardware and deploying your own Hadoop cluster.
.
A Jump Start Guide to Big Data on AWS Cloudl37
What Power’s Amazon EMR?
38.
KINESIS REDSHIFT
EMR
DYNAMO DB
UseCases of Amazon EMR
Amazon EMR can be used to process applications with data intensive workloads.
Some of the common use case examples for Amazon EMR are:
• Data Mining
• Log file analysis
• Web indexing
• Machine learning
• Financial analysis
• Scientific simulations
• Data warehousing
• Bioinformatics research
Apart from these there could be several specific use cases in your organization that
might require large scale data computation, for all such use cases you can use
Amazon EMR.
USE CASES
A Jump Start Guide to Big Data on AWS Cloudl38
39.
KINESIS REDSHIFT
EMR
DYNAMO DB
MajorAdvantages of EMR
• No upfront investments in hardware
Infrastructure:
• Simple and managed cluster launching
• Easy to scale up or down
• Integration with other Amazon Web
Services including S3 as an alternative
to HDFS:
• Integration with other Apache Hadoop
projects, including Hive and Pig:
• Multiple EC2 instance options for clusters
gives a lot of flexibility
• Integration with leading BI Tools
• Multiple management tools including CLI,
SDKs and User Console
• Limitations of Amazon EMR
• Amazon EMR is not open source, so
you have limited control over the source code
There are increased latencies as typical EMR jobs use data stored in S3 which is processed on
EC2, moving data from S3 to EC2 takes some time. Amazon EMR does not support the latest
version of Hadoop; current versions supported by EMR are Hadoop 0.20.205 and Hadoop 1.0.3
with custom patches. If your application requires using the latest features of Hadoop, EMR may
not be the best option
A Jump Start Guide to Big Data on AWS Cloudl39
KINESIS REDSHIFT
EMR
DYNAMO DB
Therise of internet and open source software
along with Cloud &Mobile computing have
ensured that information technology is no
longer an advantage for large enterprises nor a
bottle neck for SMEs Start Ups. Open Source
Software & Cloud Computing have
democratized the way Information Technology
is being utilized with organizations. With a level
playing field created in terms of technology, the
next frontier for business leadership is shifting
towards the use of vast amount of Information.
In the fast changing world of business and technology, information plays an important role in ensuring
the success of an organization. In the recent past, the most successful companies have been the ones
that have successfully tackled the challenge of Big Data. Big Data is helping organizations of all sizes
to make better business decisions, save costs, improve customer service, deliver better user
experience, and identify security risks among other things, it is no more a farfetched idea, it is here.
So let’s talk about some opportunities that Big Data provides:
• Operational Predictability
• Improved Customer Service
• Managing Security Risks
A Jump Start Guide to Big Data on AWS Cloudl41
What are these Opportunities?
42.
KINESIS REDSHIFT
EMR
DYNAMO DB
OperationalPredictability
Technology has enabled to track operations across different units of business to the most
granular level. Collecting and analyzing data from the past can help companies to identify
patterns and predict opportunities or issues in a better way.
A Jump Start Guide to Big Data on AWS Cloudl42
You can track data generated
from machines to sensors to
computers to cash registers.
Correlating this data can help
you get insights in to your
operations, real time view of
transactions and customer
behavior.
43.
KINESIS REDSHIFT
EMR
DYNAMO DB
ImprovedCustomer Service
Companies already collect data about
their customers in various formats.
For a large company consolidating
multiple views of the same customer
can help in giving a 360-degree view
of the existing customers that can
further improve customer service.
Further to improve on this existing
set of data, these customer views
can be now expanded to include
various internal or external sources
of data, for example extracting feed
of data about your products from
social media. This can help you gain
better understanding of customers,
on how they perceive your brand vis
a vis a competitor or what
improvements customers are looking
for in your products among other
things.
A Jump Start Guide to Big Data on AWS Cloudl43
44.
KINESIS REDSHIFT
EMR
DYNAMO DB
ManagingRisks
Big Data analytics can help with lowering risk of fraud and
cyber threats if used correctly. Large banking, financial
and insurance companies have implemented various big
data solutions that help them identifying investment risks,
reducing fraud threats among other things. Governments
across the globe have implemented solutions that help
them uncover suspicious activities. Of course, not all of
these initiatives are well received by everyone, think NSA
& Edward Snowden.
Organizations also deploy big data to predict online
attacks on their cyber assets and mitigate them before
they could do any harm. Big Data solutions can really help
organizations to solve a whole bunch of problems which
were previously difficult if not impossible to resolve.
Use of Big Data is not limited to large industries, today
SMEs can take equally take advantage of Big Data using
Open Source and Cloud Computing technologies. Correct
use of Big Data can help SMEs challenge the large
incumbents in their industry successfully. Each industry
and company has various use cases of Big Data. In the
next few posts, I will write about some of these use cases
specific to certain industries.
A Jump Start Guide to Big Data on AWS Cloudl44
KINESIS REDSHIFT
EMR
DYNAMO DB
Ring– Ring – Anyone there?
You have your Networks Spread over 1000
Cities, some with Over a Million Connections,
Telecom Industry faces Challenges such as:
• Customer Churning & Retention
• Understanding Payment Details for new
Schemes
• Providing Customized Payment & Service
models to the Right Customers
• Understand Competitor Pricing Models &
faster innovation
• Checking Which Offers & Schemes are
popular in which Geographies
A Jump Start Guide to Big Data on AWS Cloudl46
47.
Operational
Efficiency: (10-
15% Open
Reduction)
Innovative
Business
Models
•Create Data Driven API models for improved
customer service.
• Using Payment Data from Retail Chains & Outlets to
create Coupons & Offers, Combining them with
NFC(Near Field Communication) to increase Buying
frequency of Customer .
• Creating World Class customer care, by tracking in
depth subscriber activity, tracking issues and
reducing call center iterations & time.
• Anticipating & Implementing Network Planning
even before the demand & predict Network stress
points & Under utilized Network areas.
Telecom – Opportunities using Big Data
A Jump Start Guide to Big Data on AWS Cloudl47
48.
Precise
Business
Models
Real Time Analysis&
Decision Making:
(Revenue Potential
Inc. 5-10%)
• Optimizing Offers based on Subscriber Network usage
patterns & Traffic to come up with newer offers which is
critical on driving value added service adoption.
• Help Service providers understand what behaviors will
trigger churn events & what actions will prevent
churning, by dynamic offers created by complaint
triggers in real time. Reducing Churn Rates by 8-12% .
• Controlling RAN(Radio Access Network) Congestion by
dividing Subscribers to Individual Sub Cell Levels & by
assimilating data of past geographic positions & real
time data on current locations can provide priority to
certain subscribers over others.
• Cyber Cop Initiatives where pattern matches of
subscriber activities can be used to detect malicious
activities and determine traffic changing abnormal
consumptions to predict Fraud activities.
A Jump Start Guide to Big Data on AWS Cloudl48
Telecom – Opportunities using Big Data
49.
KINESIS REDSHIFT
EMR
DYNAMO DB
Whatare You Buying Today? - RETAIL
In retail, big data generally refers to the use of sets of information from inside and outside a
company that can then be analyzed and used to improve profits.
Imagine Your Retail Outlets over a 100s of cities, with more than 10 outlets per city. Even if you
have 10,000 customers per month buying at a frequency of 5, you will end up with 5, 00, 00,000
unique records! This Does not even take into Consideration the Age, Gender, Geographic Trend,
Weather, Time of the month & more!
Challenges faced by Retail Industry are :
•Buying Patterns
•Shopping Offers
•Cross Selling Success
•Loyalty & Retention
•Effective Marketing Campaigns
•Predictive Demands
•Dynamic Price Optimization
A Jump Start Guide to Big Data on AWS Cloudl49
50.
Personalized
Recommendations
• Data Collectedbased on previous online & offline purchases,
even online clicks, likes & wish lists are recorded to generate
recommendations in real time.
• Online Shoppers are given recommendations at reduced
prices based on their previous purchase trends. Amazon.com
has increased their sales volumes by 25% on this.
Dynamic
Pricing
• Online Shoppers are given reduced prices based on data on
time of the day, Festive offers validity period, loyalty of
customers and more.
• Offline shoppers use these data driven approaches to map
shopping patterns and based on proximity of customers
allow price variations with RFID price tags.
Retail – Opportunities using Big Data
A Jump Start Guide to Big Data on AWS Cloudl50
51.
In Store
Experience
• Geo-Fencingwhich allows retailers to provide real time
offers to customers on their cell phones(based on their
previous shopping sprees) as they enter a geo fenced area.
• Optimized Product Placement is done Scientifically where
algorithms check buyer tendencies & have products placed
in the right geography, this becomes very important for
bigger players like Wal-Mart & Macy's.
Micro
Segmentation
& Inventory
Management
• Segmenting Customers have been taken to the next level,
with social media interactions, marketing campaign results,
wish lists. Targeted offers are now made to granular
customer segments with promo codes & coupons!
• With Big Data Retailers can get predictive analytics on
prices as they fluctuate through the supply chain. This
allows them to set prices, and also react proactively to
demand spikes to avoid over stock-outs.
A Jump Start Guide to Big Data on AWS Cloudl51
Retail – Opportunities using Big Data
52.
KINESIS REDSHIFT
EMR
DYNAMO DB
WillI Get Money for this Accident? - INSURANCE
What is the most challenging business issue for insurers
today, and what role does analytics play in addressing it?
Currently only the largest insurers have traditional policy rating and
claims data that would be considered “big” (i.e. potentially
unmanageable with a relational database). But insurance
companies of all sizes are encountering big data from
new sources such as their website traffic, vehicle
telematics programs, and social media.
Some Big Data Facts about Insurance Industry
are:
$80 Billion Loss in U.S. per Year due to
Frauds!
15% of premium costs in South Africa are
Frauds!
Claims on Automobiles have a 25-33% Fraud !
• What Policies are best Suited for Customers?
• How to tackle Increasing Diseases & ailments?
• How to reduce customer Hassles?
A Jump Start Guide to Big Data on AWS Cloudl52
53.
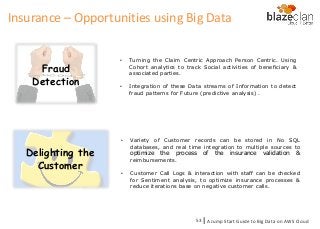
Fraud
Detection
• Turning theClaim Centric Approach Person Centric. Using
Cohort analytics to track Social activities of beneficiary &
associated parties.
• Integration of these Data streams of Information to detect
fraud patterns for Future (predictive analysis) .
Delighting the
Customer
• Variety of Customer records can be stored in No SQL
databases, and real time integration to multiple sources to
optimize the process of the insurance validation &
reimbursements.
• Customer Call Logs & interaction with staff can be checked
for Sentiment analysis, to optimize insurance processes &
reduce iterations base on negative customer calls.
Insurance – Opportunities using Big Data
A Jump Start Guide to Big Data on AWS Cloudl53
54.
Predictive
Analysis
Understand Customer Lifestyleby integrating
feeds of social networks to determine Disease
Patterns so that insurance schemes 10-15 years
into the future insurance companies can identify
these degenerating lifestyles & offer schemes at
higher premiums.
Improving
Product
Opportunities
Checking out the Success of Insurance Schemes &
Which are most popular, to drive similar scheme
models & understand why other schemes are not
popular. This can be done by mapping the
successful customer base lifestyle trends.
A Jump Start Guide to Big Data on AWS Cloudl54
Insurance – Opportunities using Big Data
55.
KINESIS REDSHIFT
EMR
DYNAMO DB
IWant a Smart CAR too! -AUTOMOTIVE
In the automotive industry that ranges from your
vehicle’s driving data to analyzing how efficient
an assembly line worker’s movements are when
assembling a vehicle.
“Big data” is one of the key points and
opportunities for automakers regarding
information technology solutions.
Some Big Data Facts about Automotive Industry
are:
• Number of Internet Capable Vehicles in
Europe will be 48Mil by 2016!
• There are more than 74 Sensors in Ford’s
Connected Cars!
• These Hybrid Cars can generate
25GBs/Hour of Data!!
A Jump Start Guide to Big Data on AWS Cloudl55
56.
Vehicle
Insurance
• Using "Telematics",driver's driving patterns
can be analyzed. These can be used by
insurance companies to give out alerts,
warnings in real time & even give
personalized pricing.
Integrating with
Geo Fencing &
Social Media
• GPS trackers can provide customized alerts
as vehicles pass a particular location. These
alerts are real time & based on your social
media likes & shared combined with discount
coupons & offers!
Automotive – Opportunities using Big Data
A Jump Start Guide to Big Data on AWS Cloudl56
57.
Self Repair &
Maintenance
•Your Car's intelligence system will keep
a track of all parts & liquids to be
changed or repaired for periodic
maintenance, giving you real time alerts
as you pass repair shops, which will also
bid for discounted pricing!
Learning from
the Mistakes
• Using The Black Box mechanism similar
to airplanes, product engineers can
understand if any vehicle part was the
cause & how parts can be improved in
design to reduce future accidents.
A Jump Start Guide to Big Data on AWS Cloudl57
Automotive – Opportunities using Big Data
58.
KINESIS REDSHIFT
EMR
DYNAMO DB
MyFavorite CARTOON is ON! - MEDIA
Among the big data issues M&E executives
cite:
“Poor data reliability, inability to integrate
data from different customer touch points
and a shortfall in the skills and tools
needed to derive useful insights from
customers as they click, engage or turn
away from the content and services being
offered.”
Challenges – The Media Industry
• What Content is popular?
• Where are my viewers coming from?
• What are my viewer’s opinions about my
content?
• How Do I monetize my Content?
A Jump Start Guide to Big Data on AWS Cloudl58
59.
• Using BigData Tools to analyze
current content viewed, the
storylines, characters etc. to
determine which type of
movies and or soaps are going
to be a success in the future.
• Analyzing Viewer demographics,
the popular content, devices
used to view and download data,
detecting spams, browsers and
OS used to generate actionable
reports driving business
decisions.
Media – Opportunities using Big Data
A Jump Start Guide to Big Data on AWS Cloudl59
60.
• Tracking usercomments, likes,
shares, tweets & other user
interactions with media content on
social networks to track popularity &
promote content similar to the hits.
Website
Optimization
• Based on Navigational pattern analysis
that are popular among users, website
builders can optimize the ease of reach of
the content.
Ad
Targeting
& Scope to
Monetize
• Ad servers based on Visitor Cookie
analysis & bid values generated
sometimes even in real time, deliver ads
to visitors in real time & continuously
update for successful clicks & failures.
A Jump Start Guide to Big Data on AWS Cloudl60
Media – Opportunities using Big Data
61.
KINESIS REDSHIFT
EMR
DYNAMO DB
What’sthe Interest Rate? - BANKING
Banks that can harness big data, in the form of transactions, real-time market
feeds, customer-service records, correspondence
and social media posts, can derive more
insight about their business than ever before
and build competitive advantage.
Successfully harnessing big data can help
banks achieve three critical objectives for
banking transformation:
Create a customer-focused enterprise
Optimize enterprise risk management
Increase flexibility and streamline operations
Challenges – The Banking Industry
•Detecting Frauds
•Which Schemes for which customers?
•When is my Customer Not Happy?
•How Do I Segment my customer base?
A Jump Start Guide to Big Data on AWS Cloudl61
62.
Creating
Customer
Segmentation
• Banks arenow pooling in all types of customer
buying patterns, lifestyle habits & interests to
create segmentations. With this 360 degree
view from Big Data Analytics integration, banks
can now customize product offerings & re
distribute spending from non profitable to
profitable customers.
Fraud
Detection
• Financial & Banking Institutes are using
credit/debit card purchases to understand
spending habits and detect suspicious patterns
of buying to detect frauds.
Banking – Opportunities using Big Data
A Jump Start Guide to Big Data on AWS Cloudl62
63.
• Banks andFinancial Institutions
can now track the success or
failure of their product or schemes
as they integrate social sentiments
of their products and track user
complaints.
Sales &
Marketing
Campaigns
• Using 360 Degree Customer Insights
banks are generating smarter
marketing & sales campaigns
integrating them with offers &
schemes that are more successful to
the different customer segments.
Analyzing
Voice
Sentiments
• Many Banks are now using highly unstructured data, such as
customer voices, and using complex data analysis to track
customer complaints . They are also trying to integrate the
information with the transactional data warehouse to reduce
attrition, drive up sales & even detect frauds.
A Jump Start Guide to Big Data on AWS Cloudl63
Banking – Opportunities using Big Data
64.
Hope You Enjoyed
theRead!
Read more on the Cloud!
Talk to Us!
Get Connected on Social!
www.blazeclan.com



































































![[TechTalks] Learning Configuration Management with SaltStack (Advanced Concepts)](https://cdn.slidesharecdn.com/ss_thumbnails/learningconfigurationmanagementwithsaltstackadvancedconcepts-160322054557-thumbnail.jpg?width=640&height=640&fit=bounds)








![[TechTalks] Effects of UI/ UX Designs on Customer Satisfaction & Loyalty](https://cdn.slidesharecdn.com/ss_thumbnails/effectsofuiuxdesignsoncustomersatisfactionandloyalty-151105071458-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
































