Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Akinori Ito
36,217 views
音声認識の基礎
音声認識の基礎 東北大学情報科学研究科「学際情報科学論」スライド
Read more
54
Save
Share
Embed
Embed presentation
1
/ 35
2
/ 35
Most read
3
/ 35
4
/ 35
5
/ 35
6
/ 35
Most read
7
/ 35
8
/ 35
9
/ 35
10
/ 35
11
/ 35
12
/ 35
13
/ 35
14
/ 35
15
/ 35
16
/ 35
17
/ 35
18
/ 35
19
/ 35
20
/ 35
21
/ 35
22
/ 35
23
/ 35
24
/ 35
25
/ 35
26
/ 35
27
/ 35
28
/ 35
29
/ 35
30
/ 35
31
/ 35
32
/ 35
33
/ 35
34
/ 35
35
/ 35
Most read
More Related Content
PDF
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析
by
Shinnosuke Takamichi
ODP
音声生成の基礎と音声学
by
Akinori Ito
PDF
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
PDF
自称・世界一わかりやすい音声認識入門
by
Tom Hakamata
ODP
音声合成の基礎
by
Akinori Ito
PDF
音情報処理における特徴表現
by
NU_I_TODALAB
PPTX
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
PPTX
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
やさしく音声分析法を学ぶ: ケプストラム分析とLPC分析
by
Shinnosuke Takamichi
音声生成の基礎と音声学
by
Akinori Ito
深層生成モデルに基づく音声合成技術
by
NU_I_TODALAB
自称・世界一わかりやすい音声認識入門
by
Tom Hakamata
音声合成の基礎
by
Akinori Ito
音情報処理における特徴表現
by
NU_I_TODALAB
独立低ランク行列分析に基づくブラインド音源分離(Blind source separation based on independent low-rank...
by
Daichi Kitamura
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition
by
YosukeKashiwagi1
What's hot
PDF
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
PPTX
ウェーブレット変換の基礎と応用事例:連続ウェーブレット変換を中心に
by
Ryosuke Tachibana
ODP
音声の認識と合成
by
Akinori Ito
PDF
統計的音声合成変換と近年の発展
by
Shinnosuke Takamichi
PDF
音響信号に対する異常音検知技術と応用
by
Yuma Koizumi
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
PDF
Neural text-to-speech and voice conversion
by
Yuki Saito
PPTX
音学シンポジウム 2024 招待講演 初学者のための話者認識入門:基礎技術と応用
by
Sayaka Shiota
PDF
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
PDF
時間領域低ランクスペクトログラム近似法に基づくマスキング音声の欠損成分復元
by
NU_I_TODALAB
PDF
音源分離 ~DNN音源分離の基礎から最新技術まで~ Tokyo bishbash #3
by
Naoya Takahashi
PPTX
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
PDF
深層学習を利用した音声強調
by
Yuma Koizumi
PPTX
音声分析合成[1].pptx
by
Natsumi KOBAYASHI
PDF
人間と機械と音のコミュニケーション
by
Akinori Ito
PDF
Asj2017 3invited
by
SaruwatariLabUTokyo
PDF
深層学習と音響信号処理
by
Yuma Koizumi
PDF
End-to-End音声認識ためのMulti-Head Decoderネットワーク
by
NU_I_TODALAB
PDF
音声信号の分析と加工 - 音声を自在に変換するには?
by
NU_I_TODALAB
PDF
独立深層学習行列分析に基づく多チャネル音源分離(Multichannel audio source separation based on indepen...
by
Daichi Kitamura
WaveNetが音声合成研究に与える影響
by
NU_I_TODALAB
ウェーブレット変換の基礎と応用事例:連続ウェーブレット変換を中心に
by
Ryosuke Tachibana
音声の認識と合成
by
Akinori Ito
統計的音声合成変換と近年の発展
by
Shinnosuke Takamichi
音響信号に対する異常音検知技術と応用
by
Yuma Koizumi
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス
by
Shinnosuke Takamichi
Neural text-to-speech and voice conversion
by
Yuki Saito
音学シンポジウム 2024 招待講演 初学者のための話者認識入門:基礎技術と応用
by
Sayaka Shiota
ICASSP 2019での音響信号処理分野の世界動向
by
Yuma Koizumi
時間領域低ランクスペクトログラム近似法に基づくマスキング音声の欠損成分復元
by
NU_I_TODALAB
音源分離 ~DNN音源分離の基礎から最新技術まで~ Tokyo bishbash #3
by
Naoya Takahashi
音源分離における音響モデリング(Acoustic modeling in audio source separation)
by
Daichi Kitamura
深層学習を利用した音声強調
by
Yuma Koizumi
音声分析合成[1].pptx
by
Natsumi KOBAYASHI
人間と機械と音のコミュニケーション
by
Akinori Ito
Asj2017 3invited
by
SaruwatariLabUTokyo
深層学習と音響信号処理
by
Yuma Koizumi
End-to-End音声認識ためのMulti-Head Decoderネットワーク
by
NU_I_TODALAB
音声信号の分析と加工 - 音声を自在に変換するには?
by
NU_I_TODALAB
独立深層学習行列分析に基づく多チャネル音源分離(Multichannel audio source separation based on indepen...
by
Daichi Kitamura
Similar to 音声認識の基礎
PDF
仕組みから理解する人力音声認識
by
Genki Ishibashi
PDF
pyssp
by
Shunsuke Aihara
PPTX
音声認識における言語モデル
by
KOTARO SETOYAMA
PDF
音声認識技術の変遷
by
emonosuke
PDF
【Deep Learning研修】 音声認識・音声合成技術とその応用 -基礎から最新動向まで-
by
Sony - Neural Network Libraries
ODP
音声認識
by
Ryunosuke Iwai
PPTX
Deep-Learning-Based Environmental Sound Segmentation - Integration of Sound ...
by
Yui Sudo
PDF
Speech API の概要(Microsoft Cognitive Services)
by
Atsushi Yokohama (BEACHSIDE)
PDF
Mosesdecoderコード解読の勘所
by
Jun-ya Norimatsu
PDF
DNN音響モデルにおける特徴量抽出の諸相
by
Takuya Yoshioka
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
仕組みから理解する人力音声認識
by
Genki Ishibashi
pyssp
by
Shunsuke Aihara
音声認識における言語モデル
by
KOTARO SETOYAMA
音声認識技術の変遷
by
emonosuke
【Deep Learning研修】 音声認識・音声合成技術とその応用 -基礎から最新動向まで-
by
Sony - Neural Network Libraries
音声認識
by
Ryunosuke Iwai
Deep-Learning-Based Environmental Sound Segmentation - Integration of Sound ...
by
Yui Sudo
Speech API の概要(Microsoft Cognitive Services)
by
Atsushi Yokohama (BEACHSIDE)
Mosesdecoderコード解読の勘所
by
Jun-ya Norimatsu
DNN音響モデルにおける特徴量抽出の諸相
by
Takuya Yoshioka
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割
by
Shinnosuke Takamichi
More from Akinori Ito
PPTX
いろいろなプログラミング言語による互除法
by
Akinori Ito
PDF
マルチメディア情報ハイディング
by
Akinori Ito
PPTX
音声と音楽による人間・機械間メタコミュニケーション
by
Akinori Ito
PDF
研究発表のやり方
by
Akinori Ito
PDF
高効率音声符号化―MP3詳解―
by
Akinori Ito
PPTX
歌声分析のエンタテイメント応用
by
Akinori Ito
PPTX
科学論文執筆・投稿にまつわる基礎知識
by
Akinori Ito
ODP
音楽の情報処理
by
Akinori Ito
ODP
音声の生成と符号化
by
Akinori Ito
いろいろなプログラミング言語による互除法
by
Akinori Ito
マルチメディア情報ハイディング
by
Akinori Ito
音声と音楽による人間・機械間メタコミュニケーション
by
Akinori Ito
研究発表のやり方
by
Akinori Ito
高効率音声符号化―MP3詳解―
by
Akinori Ito
歌声分析のエンタテイメント応用
by
Akinori Ito
科学論文執筆・投稿にまつわる基礎知識
by
Akinori Ito
音楽の情報処理
by
Akinori Ito
音声の生成と符号化
by
Akinori Ito
音声認識の基礎
1.
1 音声認識 Speech Recognition
2.
2 音声の認識 (Speech Recognition) 入力された音声を文字列に変換する (Speech-to-Text) 概要 –
特徴抽出[Feature extraction] (MFCC) – 音響モデル[Acoustic model] (HMM) – 言語モデル[Language model] (FSG, N-gram) – デコーダ[Decoder]
3.
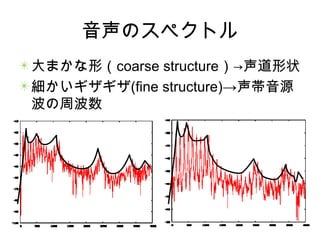
音声のスペクトル 大まかな形(coarse structure)→声道形状 細かいギザギザ(fine structure)→声帯音源 波の周波数
4.
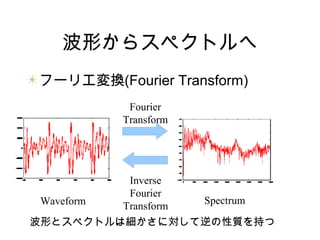
波形からスペクトルへ フーリエ変換(Fourier Transform) Waveform Spectrum Fourier Transform Inverse Fourier Transform 波形とスペクトルは細かさに対して逆の性質を持つ
5.
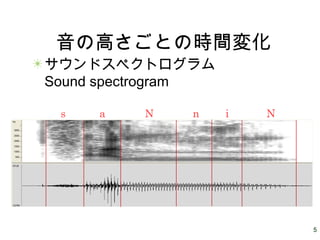
5 音の高さごとの時間変化 サウンドスペクトログラム Sound spectrogram s a
N n i N
6.
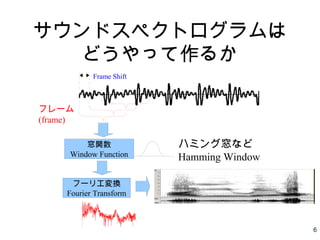
6 サウンドスペクトログラムは どうやって作るか フレーム (frame) 窓関数 フーリエ変換 Fourier Transform 窓関数 Window Function Frame
Shift ハミング窓など Hamming Window
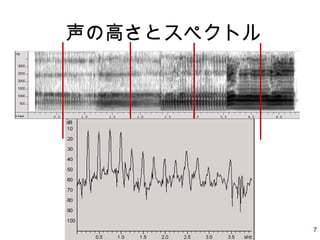
7.
7 声の高さとスペクトル
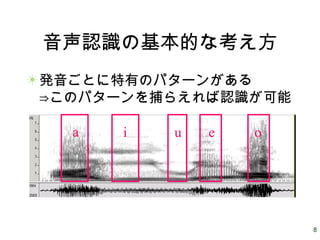
8.
8 音声認識の基本的な考え方 発音ごとに特有のパターンがある ⇒このパターンを捕らえれば認識が可能 a i u
e o
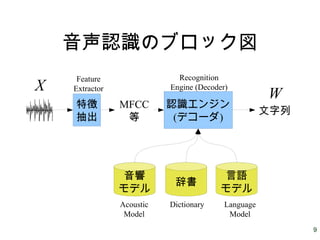
9.
9 音声認識のブロック図 特徴 抽出 MFCC 等 認識エンジン (デコーダ) 音響 モデル 辞書 言語 モデル 文字列 X W Feature Extractor Recognition Engine (Decoder) Acoustic Model Language Model Dictionary
10.
10 確率的音声認識の原理 事後確率最大となる確率的推定問題 (Maximum a posteiori
probability) W = arg max W PW∣X = arg max W p X∣W PW p X = arg max W p X∣W PW
11.
11 特徴量の抽出 スペクトルの概形を表すパラメータを 使う – スペクトルの概形⇔声道伝達関数⇔音韻 – スペクトルの微細構造(⇔ピッチ)は使わな い 概形自体は冗長⇒よりコンパクトな特徴 –
ケプストラム (Cepstrum) 時間構造の利用 – Δケプストラム,ΔΔケプストラム
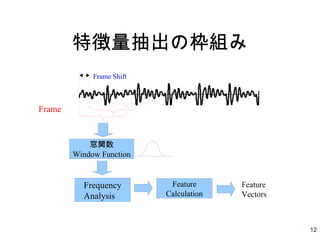
12.
12 特徴量抽出の枠組み Frame 窓関数 Frequency Analysis 窓関数 Window Function Feature Calculation Feature Vectors Frame Shift
13.
13 スペクトルとケプストラム FFTケプストラム (FFT Cepstrum): 対数パワースペクトルのフーリエ変換 –
低次のケプストラム係数が対数スペクトル の概形に対応→音声認識に利用 – 高次のケプストラムのピークが基本周波数 に対応→ピッチ抽出に利用 C =F [log∣X ∣ 2 ]
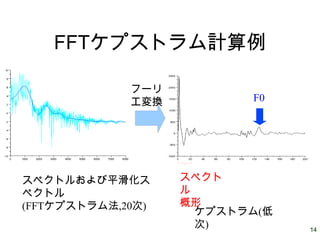
14.
14 FFTケプストラム計算例 スペクトルおよび平滑化ス ペクトル (FFTケプストラム法,20次) ケプストラム(低 次) スペクト ル 概形 F0 フーリ エ変換
15.
15 ケプストラムの仲間たち(1) FFTケプストラム (FFT Cepstrum) –
音声→パワースペクトル→対数パワースペ クトル→ケプストラム LPCケプストラム (LPC Cepstrum) – 音声→線形予測係数→LPCスペクトル→対数 LPCスペクトル→ケプストラム
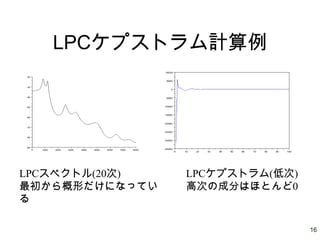
16.
16 LPCケプストラム計算例 LPCスペクトル(20次) 最初から概形だけになってい る LPCケプストラム(低次) 高次の成分はほとんど0
17.
17 ケプストラムの仲間たち(2) メル周波数軸上のケプストラム – LPCメルケプストラム (LPC
mel cepstrum) • LPCケプストラム係数を変換 – メルLPCケプストラム (Mel LPC cepstrum) • 音声波形をフィルタでメル周波数変換してLPC分 析 – MFCC (Mel Frequency Cepstral Coefficients) • メル周波数間隔のバンドパスフィルタ出力のコサ イン変換
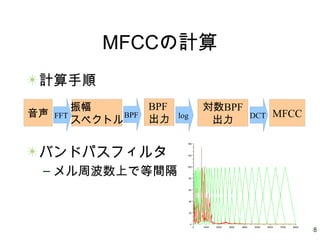
18.
18 MFCCの計算 計算手順 バンドパスフィルタ – メル周波数上で等間隔 音声 振幅 スペクトル 対数BPF 出力 BPF 出力 MFCCFFT logBPF
DCT
19.
19 特徴ベクトル系列 あるフレームの特徴量は、数十個の数 字の組(ベクトル):特徴ベクトル – i番目のフレームの特徴ベクトルをxiとする と 音声認識は、数字の組Xがどんな単語列 に対応するかを決定する問題に帰着す る X =x1 x2 …
xN
20.
20 音響モデル (Acoustic model) 記号(音素,単語など)
W が特徴量系列 X に対応する確率 p(X|W)を計算する – どうやって確率をつけるか? – XもWも可変長⇒どう対応付けるか? 隠れマルコフモデル(HMM)によるモデ ル化 – 特徴量系列を,特定の確率分布に従う系列 の連続としてモデル化
21.
21 HMM:隠れマルコフモデル HMMは特徴量系列を生成するモデル – 非決定性有限状態オートマトン – 「現在の状態」が確率的に変わりながら, 確率的に特徴ベクトルを生成する 状態iからjへの遷移 確率 状態iでの特徴ベク トルxの出力確率密 度 状態iの初期確率
i ai j bi x 多次元混合正規分布がよく用い られる
22.
22 HMMによる特徴ベクトルの生 成 HMMの「動作」 – 現在、ある状態にいる – ある確率で状態遷移 –
状態遷移と同時に特徴ベクトルを1個生成 する – どんな特徴ベクトルを生成するかは確率的 に決まっている – 生成された特徴ベクトルから、どの状態を 経てそれが出力されたかを知ることができ ない
23.
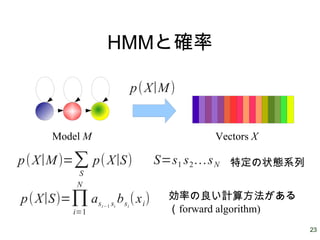
23 HMMと確率 Model M Vectors
X p(X∣M) p(X∣M)=∑ S p(X∣S) S=s1 s2…sN 特定の状態系列 p(X∣S)=∏ i=1 N asi−1 si bsi (xi) 効率の良い計算方法がある (forward algorithm)
24.
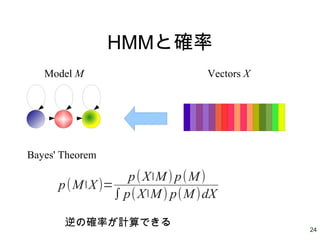
24 HMMと確率 Model M Vectors
X p(M∣X)= p(X∣M) p(M) ∫ p(X∣M) p(M)dX Bayes' Theorem 逆の確率が計算できる
25.
25 HMMの特徴 生成モデルである (vs. 識別モデル) –
音声の特徴量系列が出力される「確率密度」を計算する ことができる 任意の長さの系列が生成できる – 伸び縮みする系列を扱うのに適している – 系列と状態を対応付ける方法が確立している(ビタビアル ゴリズム) 学習によってパラメータが推定できる – サンプルを与えることで,そのサンプルを生成する確率 が高いHMMを推定することができる (Baum-Welch のア ルゴリズム)
26.
26 HMMの学習 (Training) 各シンボル(音素など)のデータを大量に 与えることでHMMが学習できる /a/ /i/ /o/ /a/のサンプ ル /i/のサンプル /o/のサンプ ル
27.
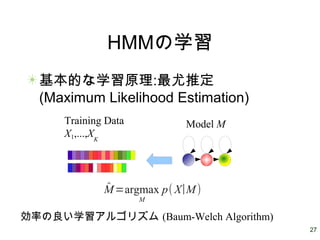
27 HMMの学習 基本的な学習原理:最尤推定 (Maximum Likelihood Estimation) Training
Data X1,...,XK Model M ̂M=argmax M p( X∣M) 効率の良い学習アルゴリズム (Baum-Welch Algorithm)
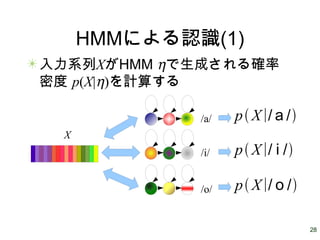
28.
28 HMMによる認識(1) 入力系列XがHMM ηで生成される確率 密度 p(X|η)を計算する /a/ /i/ /o/ X p
X∣/ a / p X∣/ i / p X∣/ o /
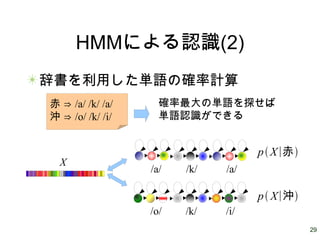
29.
29 HMMによる認識(2) 辞書を利用した単語の確率計算 /a/ /a//k/ /o/ /i//k/ X 赤
⇒ /a/ /k/ /a/ 沖 ⇒ /o/ /k/ /i/ p X∣赤 p X∣沖 確率最大の単語を探せば 単語認識ができる
30.
30 言語モデル (Language model) 文を構成する単語の並びの制約を表現するモ デル ある文の並びを「評価」する –
1/0の評価:文法 (受理可能/不可能) • 有限状態文法(有限状態オートマトン) • 文脈自由文法(CFG) – 並びの「良さ」を確率的に評価: 統計的言語 モデル • N-gram • その他の確率的言語モデル
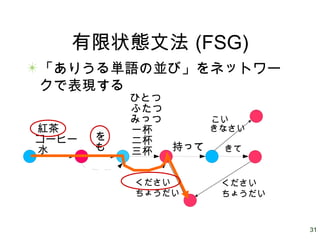
31.
31 有限状態文法 (FSG) 「ありうる単語の並び」をネットワー クで表現する 紅茶 コーヒー 水 を も ひとつ ふたつ みっつ 一杯 二杯 三杯 持って こい きなさい きて ください ちょうだい ください ちょうだい
32.
32 統計的言語モデル もっと大規模な文を認識するには? – 文章の音声入力など ある単語が並ぶ確率(並びやすさ)を 使う これを直接求めるのは難しい →近似によって求める Pw1 w2wN
=∏i Pwi∣w1wi−1
33.
33 N-gram言語モデル ある単語の生起確率が直前のn-1単語に のみ依存すると仮定 – n=2の場合 Pw1wN =∏i Pwi∣wi−1 n=1:
unigram n=2: bigram n=3: trigram
34.
34 一番良い文を探そう 20000種類の単語を知っている音声認識 …システムでは – 7個の単語からなる文は 200007 =1.28×1030 通り – 文1個の計算に1/10000秒かかったとする –
全部調べるには400京年(400億年の1億 倍)かかる
35.
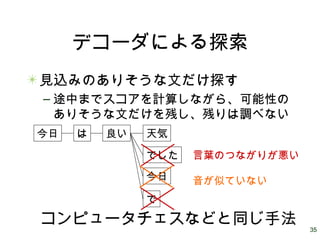
35 デコーダによる探索 見込みのありそうな文だけ探す – 途中までスコアを計算しながら、可能性の ありそうな文だけを残し、残りは調べない 今日 は
良い 天気 でした 今日 で 言葉のつながりが悪い 音が似ていない コンピュータチェスなどと同じ手法


![2
音声の認識 (Speech Recognition)
入力された音声を文字列に変換する
(Speech-to-Text)
概要
– 特徴抽出[Feature extraction] (MFCC)
– 音響モデル[Acoustic model] (HMM)
– 言語モデル[Language model]
(FSG, N-gram)
– デコーダ[Decoder]](https://image.slidesharecdn.com/2-130702212108-phpapp02/85/slide-2-320.jpg)


![13
スペクトルとケプストラム
FFTケプストラム (FFT Cepstrum):
対数パワースペクトルのフーリエ変換
– 低次のケプストラム係数が対数スペクトル
の概形に対応→音声認識に利用
– 高次のケプストラムのピークが基本周波数
に対応→ピッチ抽出に利用
C =F [log∣X ∣
2
]](https://image.slidesharecdn.com/2-130702212108-phpapp02/85/slide-13-320.jpg)

































![音声分析合成[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/random-220616063344-815a6360-thumbnail.jpg?width=640&height=640&fit=bounds)

























