Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Toshiki Sasaki
778 views
SVM
SVM
Software
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PDF
深層学習Day4レポート(小川成)
by
ssuser441cb9
PPTX
サポートベクトルマシンを用いた自動人相判別の検討 : A study on automatic physiognomy classification wi...
by
Akira Tamamori
PDF
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
ZIP
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
PPTX
SVMについて
by
mknh1122
PDF
SVMってなに?
by
smzkng
PDF
はじめてのパターン認識 第8章 サポートベクトルマシン
by
Motoya Wakiyama
PPTX
クラシックな機械学習の入門 5. サポートベクターマシン
by
Hiroshi Nakagawa
深層学習Day4レポート(小川成)
by
ssuser441cb9
サポートベクトルマシンを用いた自動人相判別の検討 : A study on automatic physiognomy classification wi...
by
Akira Tamamori
SVM実践ガイド (A Practical Guide to Support Vector Classification)
by
sleepy_yoshi
今さら聞けないカーネル法とサポートベクターマシン
by
Shinya Shimizu
SVMについて
by
mknh1122
SVMってなに?
by
smzkng
はじめてのパターン認識 第8章 サポートベクトルマシン
by
Motoya Wakiyama
クラシックな機械学習の入門 5. サポートベクターマシン
by
Hiroshi Nakagawa
Viewers also liked
PDF
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
PDF
主成分分析
by
貴之 八木
PPTX
A Method of Speech Waveform Synthesis based on WaveNet considering Speech Gen...
by
Akira Tamamori
PDF
10分でわかる主成分分析(PCA)
by
Takanori Ogata
PDF
今日から使える! みんなのクラスタリング超入門
by
toilet_lunch
PPTX
Unit ii
by
kavukavya
DOCX
Alfred CV
by
Alfred Chikunichawa
DOCX
Costume
by
charlieround
DOCX
Folder Evidence
by
Diana Chavez
PPTX
Πρακτική εξάσκηση 2014
by
Stefanos Kyriakou
DOCX
How_To_Manually_Reinstall_SCCM2012_Agent
by
Eric Roberson
PDF
Ccartel
by
Jesús González Jarillo
PPTX
ESPACIO GEOGRAFICO
by
Jeannette Sanchez
SMO徹底入門 - SVMをちゃんと実装する
by
sleepy_yoshi
主成分分析
by
貴之 八木
A Method of Speech Waveform Synthesis based on WaveNet considering Speech Gen...
by
Akira Tamamori
10分でわかる主成分分析(PCA)
by
Takanori Ogata
今日から使える! みんなのクラスタリング超入門
by
toilet_lunch
Unit ii
by
kavukavya
Alfred CV
by
Alfred Chikunichawa
Costume
by
charlieround
Folder Evidence
by
Diana Chavez
Πρακτική εξάσκηση 2014
by
Stefanos Kyriakou
How_To_Manually_Reinstall_SCCM2012_Agent
by
Eric Roberson
Ccartel
by
Jesús González Jarillo
ESPACIO GEOGRAFICO
by
Jeannette Sanchez
Similar to SVM
PDF
コンピュータ先端ガイド2巻3章勉強会(SVM)
by
Masaya Kaneko
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
PDF
サポートベクトルマシン(SVM)の勉強
by
Kazuki Adachi
PDF
パターン認識 第12章 正則化とパス追跡アルゴリズム
by
Miyoshi Yuya
PPT
SVM&R with Yaruo!!
by
guest8ee130
PPTX
Prml revenge7.1.1
by
Naoya Nakamura
PDF
はじめてのパターン認識8章サポートベクトルマシン
by
NobuyukiTakayasu
PDF
はじめてのパターン認識8章 サポートベクトルマシン
by
NobuyukiTakayasu
PDF
サポートベクトルマシン入門
by
Wakamatz
PDF
PoisoningAttackSVM (ICMLreading2012)
by
Hidekazu Oiwa
PPT
SVM&R with Yaruo!!#2
by
guest8ee130
PDF
MMDs 12.3 SVM
by
mfumi
PDF
人工知能10 サポートベクトルマシン
by
Hirotaka Hachiya
PDF
はじめてのパターン認識第八章
by
Arata Honda
PDF
お披露目会05/2010
by
JAVA DM
PPTX
第七回統計学勉強会@東大駒場
by
Daisuke Yoneoka
PDF
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
PDF
Sakusaku svm
by
antibayesian 俺がS式だ
PPTX
SVM -R-
by
Yuu Kimy
PDF
PRML輪読#7
by
matsuolab
コンピュータ先端ガイド2巻3章勉強会(SVM)
by
Masaya Kaneko
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
サポートベクトルマシン(SVM)の勉強
by
Kazuki Adachi
パターン認識 第12章 正則化とパス追跡アルゴリズム
by
Miyoshi Yuya
SVM&R with Yaruo!!
by
guest8ee130
Prml revenge7.1.1
by
Naoya Nakamura
はじめてのパターン認識8章サポートベクトルマシン
by
NobuyukiTakayasu
はじめてのパターン認識8章 サポートベクトルマシン
by
NobuyukiTakayasu
サポートベクトルマシン入門
by
Wakamatz
PoisoningAttackSVM (ICMLreading2012)
by
Hidekazu Oiwa
SVM&R with Yaruo!!#2
by
guest8ee130
MMDs 12.3 SVM
by
mfumi
人工知能10 サポートベクトルマシン
by
Hirotaka Hachiya
はじめてのパターン認識第八章
by
Arata Honda
お披露目会05/2010
by
JAVA DM
第七回統計学勉強会@東大駒場
by
Daisuke Yoneoka
Infinite SVM [改] - ICML 2011 読み会
by
Shuyo Nakatani
Sakusaku svm
by
antibayesian 俺がS式だ
SVM -R-
by
Yuu Kimy
PRML輪読#7
by
matsuolab
SVM
1.
2016/04/15 Python課題発表 改定 佐々木俊樹
2.
1. 課題テーマ 1.1. 課題の内容 1.2.
データセット 2. SVMについて 2.1. SVMとは 2.2. 識別面の決定 2.3. マージン最大化 マージン最大化の条件 2.4. ソフトマージンSVM 3. コード説明と結果 3.1. コードの説明 3.2. 交差検定 3.3. 結果 4. まとめ アジェンダ 1
3.
1. 課題の内容 2
4.
課題の内容 手書き文字の3と8を SVMを用いて識別し その正解率を求める ( ソフトマージンSVM ) 3
5.
ラベルが3のデータ:183枚 ラベルが8のデータ:174枚 データセット [F.
Pedregosa+2011] 4 データサイズ:8画素 × 8画素 64次元
6.
2. SVMとは 5
7.
パターン認識手法の一種 【マージン最大化】という基準で、 2クラスのパターン識別器を構成する 非線形SVMもあるが、今回は線形SVMに関して SVMとは [Bishop2012] 6参考:http://home.hiroshima-u.ac.jp/tkurita/lecture/svm.pdf Support Vector
Machineの略称
8.
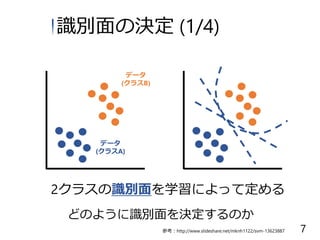
データ (クラスB) データ (クラスA) 2クラスの識別面を学習によって定める 識別面の決定 (1/4) どのように識別面を決定するのか 7参考:http://www.slideshare.net/mknh1122/svm-13623887
9.
・学習サンプル群: 𝒙 𝒙 𝒙
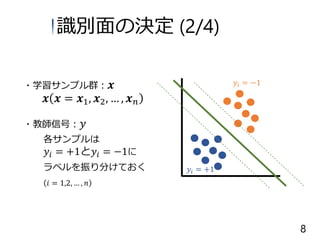
= 𝒙1, 𝒙2, … , 𝒙 𝑛 ・教師信号: 𝑦 各サンプルは 𝑦𝑖 = +1と𝑦𝑖 = −1に ラベルを振り分けておく 𝑖 = 1,2, … , 𝑛 𝑦𝑖 = −1 𝑦𝑖 = +1 識別面の決定 (2/4) 8
10.
𝑔 𝑥 =
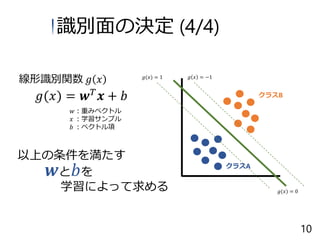
0 : 識別面 𝑔 𝑥 > +1 : クラスAと判定 𝑔 𝑥 < −1 : クラスBと判定 𝑔 𝑥 = −1𝑔(𝑥) = 1 𝑔(𝑥) = 0 クラスB𝑔(𝑥) = 𝒘 𝑇 𝒙 + 𝑏 線形識別関数 𝑔 𝑥 𝑤:重みベクトル 𝑥 :学習サンプル 𝑏 :ベクトル項 クラスA 識別面の決定 (3/4) 9
11.
𝑔(𝑥) = 𝒘
𝑇 𝒙 + 𝑏 線形識別関数 𝑔 𝑥 クラスB 𝑤:重みベクトル 𝑥 :学習サンプル 𝑏 :ベクトル項 以上の条件を満たす 𝒘と 𝑏を 学習によって求める 𝑔 𝑥 = −1𝑔(𝑥) = 1 クラスA 𝑔(𝑥) = 0 識別面の決定 (4/4) 10
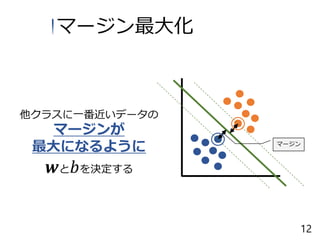
12.
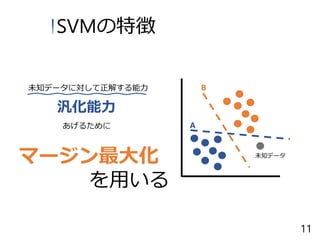
未知データに対して正解する能力 汎化能力 マージン最大化 未知データ あげるために を用いる A B SVMの特徴 11
13.
他クラスに一番近いデータの マージンが 最大になるように 𝒘と 𝑏を決定する マージン マージン最大化 12
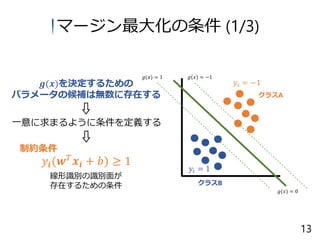
14.
クラスA クラスB 𝑦𝒊(𝒘 𝑇 𝒙𝒊
+ 𝑏) ≥ 1 線形識別の識別面が 存在するための条件 𝑦𝑖 = −1 𝑦𝑖 = 1 𝑔 𝑥 = −1𝑔(𝑥) = 1 𝑔(𝑥) = 0 𝒈(𝒙)を決定するための パラメータの候補は無数に存在する 一意に求まるように条件を定義する 制約条件 マージン最大化の条件 (1/3) 13
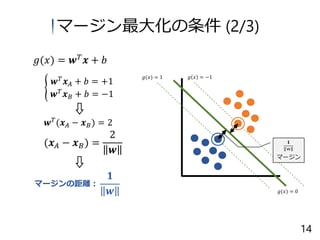
15.
𝑔 𝑥 =
−1𝑔(𝑥) = 1 𝑔(𝑥) = 0 𝒘 𝑇 (𝒙 𝐴 − 𝒙 𝐵) = 2 (𝒙 𝐴 − 𝒙 𝐵) = 2 𝒘 𝟏 𝒘 マージンの距離: ൝ 𝒘 𝑇 𝒙 𝐴 + 𝑏 = +1 𝒘 𝑇 𝒙 𝐵 + 𝑏 = −1 マージン マージン最大化の条件 (2/3) 𝑔(𝑥) = 𝒘 𝑇 𝒙 + 𝑏 14 𝟏 w
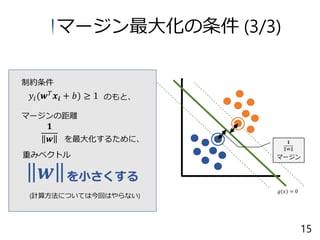
16.
𝑔(𝑥) = 0 𝑦𝑖(𝒘
𝑇 𝒙𝒊 + 𝑏) ≥ 1 𝟏 𝒘 マージンの距離 を最大化するために、 を小さくする 制約条件 のもと、 𝒘 重みベクトル (計算方法については今回はやらない) マージン 𝟏 w マージン最大化の条件 (3/3) 15
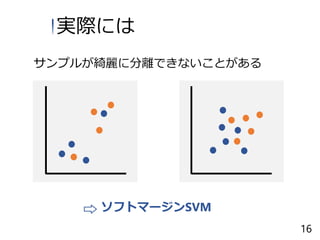
17.
サンプルが綺麗に分離できないことがある ソフトマージンSVM 実際には 16
18.
マージンが最大である必要が ないようにする 識別面で分離に失敗するデータが あっても許容する 特徴 ソフトマージンSVM 17
19.
3. コードの解説と結果 18
20.
パッケージのインポート 手書き文字の読み込み 手書き文字データから 3と8の画像データを とりだす それぞれ+1と-1に ラベルを振り分ける コードの解説 (1/4) 19
21.
コードの解説 (2/4) さきほどのデータ data_three ,
data_eight label_three , label_eight を連結 交差検定 のためにデータを分割 20
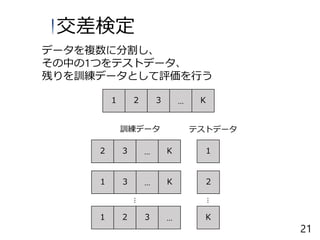
22.
データを複数に分割し、 その中の1つをテストデータ、 残りを訓練データとして評価を行う 1 2 3
… K 12 3 … K 訓練データ テストデータ 1 2 3 … K … … 交差検定 21 3 … K 21
23.
コードの解説 (3/4) ソフトマージンSVMを 用いて3と8を識別 最終的な正解率を 求めるため 加算する 混同行列を求めるために データを連結 モデルごとの正解率を 計算・表示 交差検定で分割した分を 繰り返す 22
24.
コードの解説 (4/4) 正解率の計算 正解率の表示 混同行列を表示 混同行列を計算 23
25.
結果 (1/2) 24 グループ 1
2 3 4 5 混同行列 [ [ 41 0 ] [ 0 31 ] ] [ [ 31 0 ] [ 1 40 ] ] [ [ 30 0 ] [ 0 42 ] ] [ [ 40 0 ] [ 0 32 ] ] [ [ 37 0 ] [ 0 35 ] ] 正解率 1.0 0.99 1.0 1.0 1.0
26.
結果 (2/2) 25 99.7 % 汎化能力 [
[ 190 0 ] [ 1 169 ] ] 混同行列 T r u e predict 3 8 3 8
27.
4. まとめ 26
28.
高い正解率で3と8を識別することができた まとめ Pythonの使い方に少し慣れた SVMの理解にはまだ時間が必要である 27
Download






![ラベルが3のデータ:183枚 ラベルが8のデータ:174枚
データセット [F. Pedregosa+2011]
4
データサイズ:8画素 × 8画素 64次元](https://image.slidesharecdn.com/pythonsvm-160424151525/85/SVM-5-320.jpg)

![パターン認識手法の一種
【マージン最大化】という基準で、
2クラスのパターン識別器を構成する
非線形SVMもあるが、今回は線形SVMに関して
SVMとは [Bishop2012]
6参考:http://home.hiroshima-u.ac.jp/tkurita/lecture/svm.pdf
Support Vector Machineの略称](https://image.slidesharecdn.com/pythonsvm-160424151525/85/SVM-7-320.jpg)







![結果 (1/2)
24
グループ 1 2 3 4 5
混同行列
[ [ 41 0 ]
[ 0 31 ] ]
[ [ 31 0 ]
[ 1 40 ] ]
[ [ 30 0 ]
[ 0 42 ] ]
[ [ 40 0 ]
[ 0 32 ] ]
[ [ 37 0 ]
[ 0 35 ] ]
正解率 1.0 0.99 1.0 1.0 1.0](https://image.slidesharecdn.com/pythonsvm-160424151525/85/SVM-25-320.jpg)
![結果 (2/2)
25
99.7 %
汎化能力
[ [ 190 0 ]
[ 1 169 ] ]
混同行列
T
r
u
e
predict
3 8
3
8](https://image.slidesharecdn.com/pythonsvm-160424151525/85/SVM-26-320.jpg)







































![Infinite SVM [改] - ICML 2011 読み会](https://cdn.slidesharecdn.com/ss_thumbnails/isvm-icml11a-110719050617-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


