Recommended
PDF
PDF
「Html sql」で図書館hpにアクセスしてみよう
PDF
超初心者向け!Php勉強法とプログラミングの基礎の基礎
PDF
Javaセキュアコーディングセミナー東京第4回講義
PDF
ノンプログラマーでも明日から使えるJavaScript簡単プログラム 先生:柳井 政和
PPTX
【java8 勉強会】 怖くない!ラムダ式, Stream API
PPTX
PPTX
PPTX
PDF
PDF
PDF
60分で体験する Stream / Lambda
ハンズオン
PDF
お前は PHP の歴史的な理由の数を覚えているのか
PDF
PDF
Java SE 8 lambdaで変わる プログラミングスタイル
PPT
KEY
PPTX
T sql の parse と generator
PDF
PPTX
Vanishing Component Analysisの試作と簡単な実験
PDF
Java8のstreamをダラダラまとめてみる
PDF
PDF
PDF
PPTX
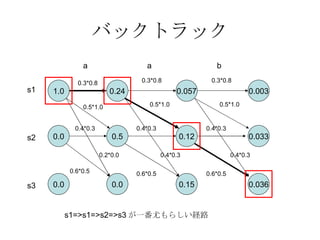
PDF
PDF
PDF
PDF
PDF
More Related Content
PDF
PDF
「Html sql」で図書館hpにアクセスしてみよう
PDF
超初心者向け!Php勉強法とプログラミングの基礎の基礎
PDF
Javaセキュアコーディングセミナー東京第4回講義
PDF
ノンプログラマーでも明日から使えるJavaScript簡単プログラム 先生:柳井 政和
PPTX
【java8 勉強会】 怖くない!ラムダ式, Stream API
PPTX
PPTX
What's hot
PPTX
PDF
PDF
PDF
60分で体験する Stream / Lambda
ハンズオン
PDF
お前は PHP の歴史的な理由の数を覚えているのか
PDF
PDF
Java SE 8 lambdaで変わる プログラミングスタイル
PPT
KEY
PPTX
T sql の parse と generator
PDF
PPTX
Vanishing Component Analysisの試作と簡単な実験
PDF
Java8のstreamをダラダラまとめてみる
Similar to 日本語形態素解析
PDF
PDF
PDF
PPTX
PDF
PDF
PDF
PDF
PDF
PPTX
PDF
PDF
PPTX
PDF
PPTX
PDF
PDF
PDF
テキスト情報と画像情報を組み合わせた論理推論システムの構築
PDF
生物統計特論3資料 2006 ギブス MCMC isseing333
PDF
Segmenting Sponteneous Japanese using MDL principle
日本語形態素解析 1. 2. はじめに 本資料の作成に辺り以下のサイト ( アーティクル ) を参考にさせていただきました。 日本語形態素解析入門 [ 山下達雄 ] http://nais.to/~yto/doc/tech/jma/jma19990514.pdf Double-Array Articles [ 矢田 晋 ] http:// nanika.osonae.com/DArray / 確率的言語モデルによる自由発話認識に関する研究 [ 村上仁一 ] http://unicorn.ike.tottori-u.ac.jp/murakami/doctor/ 3. 4. 形態素解析とは 入力 文字列 出力 形態素の列 形態素解析をざっくり説明 与えられた文字列を形態素に分解(複数候補) 上の候補から一番もっともらしいものを出力 入力:東京都 候補:東京都(名詞), 東京(名詞)-都(名詞), 東(名詞)-京都(名詞) 出力:東京都(名詞) 5. 形態素解析の必要性 情報検索 日本語分ち書き N-gram 形態素解析 なぜ形態素解析を利用するか N-gram に比べて precision( 正答率 ) が高い 2-gram の例 ( 東京都 => 東京 , 京都 ) でもめんどくさい (‘A`) 言語依存性 日本語形態素解析システムは中国語に利用できない 新語に弱い 6. 7. 8. 9. 形態素辞書探索 辞書探索の必要性 分割候補は文字列長の2のべき乗通り 辞書を使用することで候補数を抑える 涼宮ハルヒ => {(涼,宮,ハ,ル,ヒ), (涼,宮,ハ,ルヒ), (涼,宮,ハル,ヒ),(涼,宮,ハルヒ), (涼,宮ハ,ル,ヒ),(涼,宮ハ,ルヒ), (涼,宮ハル,ヒ), (涼,宮ハルヒ) , (涼宮,ハ,ル,ヒ), (涼宮,ハ,ルヒ), (涼宮,ハル,ヒ), (涼宮,ハルヒ), (涼宮ハ,ル,ヒ), (涼宮ハ,ルヒ), (涼宮ハル,ヒ), (涼宮ハルヒ)} 合計2^4通り! 10. 11. 12. Trie 概要 Trie とは文字列探索 (reTRIEval) のためのデータ構造 (DFA の一種 ) “ bird”, “bison”, “cat”, “birdie” を格納する Trie 13. Trie のデータ構造 Trie は抽象的なデータ構造なので実装のためにはより具体的なデータ構造を考える リスト実装 ( 速度:遅 , 領域:小 ) 配列実装 ( 速度:速 , 領域 : 大 ) Double 配列実装 ( 速度:速 , 領域:小 ) 14. Double Array概要 Double Arrayは小さい領域で高速な実装 2つの配列BASEとCHECKを用いてデータを格納する 節 x から節 y に至る文字 c に対応する枝が存在するとき BASE[x]+CODE[c]=y x = CHECK[y] が成り立つ。 また , x が葉 BASE[x] < 0 15. Double Array Trie による文字列探索 “bird”を検索 BASE[1]+CODE[‘b’] = 4, CHECK[4]=1 BASE[4]+CODE[‘i’] = 7, CHECK[7]=4 BASE[7]+CODE[‘r’] = 10, CHECK[10] = 7 BASE[10]+CODE[‘d’] = 6, CHECK[6] = 10 BASE[6] + CODE[‘#’] = 2, CHECK[2]=6 BASE[2] < 0 “bird” が見つかった!! 16. 17. 18. 19. 20. コスト最小法 文字列”さかなだよ”に対する辞書探索結果 さ - かな - だ - よ さか - なだ - よ さかな - だ - よ 上記各候補に生起コスト , 連接コストを付与 さ (100)-(30) かな (200)-(30) だ (10)-(30) よ (10) さか (200)-(30) なだ (200)-(45) よ (10) さかな (200)-(30) だ (10)- よ (10) 21. 22. 23. 24. 式 (2) が最小であるとき式 (1) は最大である。 確立が最大となる組を求めることはコストが最小となる組をみつけることに等しい!! =>人手によるコストとコーパスでの確立をマージできる 生起コスト 連接コスト 25. Viterbi のアルゴリズム start end a b c e d g f 20 10 30 20 30 10 10 40 10 20 10 startからendまでの最もコストの低いパスを見つける startからendまでの最も確立の高いパスを見つける 26. Viterbi のアルゴリズム このアルゴリズムが解く問題 観測された系列に対し , 最適な状態系列を求める 既に以下のことがわかっている “ 晴れ” => 秋葉原でメイド喫茶に行く (70%) “ 晴れ” => 家でニコニコ動画を見る (30%) “ 雨” => 秋葉原でメイド喫茶に行く (40%) “ 雨” => 家でニコニコ動画を見る (60%) 晴れの確率 (70%) 前日が晴れのとき , 次の日が晴れの確率 (80%) 前日が雨のとき , 次の日が晴れの確率 (40%) 土曜日は家でニコニコ動画を見 , 日曜日は秋葉原のメイド喫茶に行った ( ということが観測された ) 土曜日 , 日曜日の天気は? ( 尤もらしい状態の系列は? ) 27. Viterbi のアルゴリズム 次のようなオートマトンを考える. s1 s2 s3 0.2 a:0 b:1.0 0.3 a:0.8 b:0.2 0.5 a:1.0 b:0 0.4 a:0.3 b:0.7 0.6 a:0.5 b:0.5 状態 s1 から s2 に遷移する確率は 0.2 でこのとき、 a を出力する確率は 0, b は 1. 28. 前述のオートマトンが” abb” を出力する確率 “ aab” を出力する各状態系列の確率の総和 s1->s1->s1->s3 ((0.3*0.8)*(0.3*0.8)*(0.2*0.1) = 0.01152) s1->s1->s2->s3 ((0.3*0.8)*(0.5*1.0)*(0.6*0.5) = 0.036) s1->s2->s2->s3 ((0.5*1.0)*(0.4*0.3)*(0.6*0.5) = 0.018) “ aab” が出力されていたとき , 一番尤もらしい状態系列 s1->s1->s2->s3 ((0.3*0.8)*(0.5*1.0)*(0.6*0.5) = 0.036) Viterbi のアルゴリズム 29. 30. 31. 32. 33. “ aab” が出力されたとき , 一番尤もらしい状態系列を Viterbi のアルゴリズムを使って導出してみる s1 s2 s3 0.2 a:0 b:1.0 0.3 a:0.8 b:0.2 0.5 a:1.0 b:0 0.4 a:0.3 b:0.7 0.6 a:0.5 b:0.5 34. 35. 時刻t=1 1.0 0.0 0.0 s1 s2 s3 0.24 0.5 0.0 a 0.3*0.8 0.5*1.0 0.2*0.0 0.6*0.5 0.4*0.3 36. 時刻t=2 1.0 0.0 0.0 s1 s2 s3 0.24 0.5 0.0 a 0.3*0.8 0.5*1.0 0.2*0.0 0.6*0.5 0.4*0.3 0.057 0.12 0.15 a 0.3*0.8 0.5*1.0 0.4*0.3 0.4*0.3 0.6*0.5 37. 時刻t=3 1.0 0.0 0.0 s1 s2 s3 0.24 0.5 0.0 a 0.3*0.8 0.5*1.0 0.2*0.0 0.6*0.5 0.4*0.3 0.057 0.12 0.15 a 0.3*0.8 0.5*1.0 0.4*0.3 0.4*0.3 0.6*0.5 0.003 0.033 0.036 b 0.3*0.8 0.5*1.0 0.4*0.3 0.4*0.3 0.6*0.5 一番尤もらしい終了状態がわかった! 38. バックトラック 1.0 0.0 0.0 s1 s2 s3 0.24 0.5 0.0 a 0.3*0.8 0.5*1.0 0.2*0.0 0.6*0.5 0.4*0.3 0.057 0.12 0.15 a 0.3*0.8 0.5*1.0 0.4*0.3 0.4*0.3 0.6*0.5 0.003 0.033 0.036 b 0.3*0.8 0.5*1.0 0.4*0.3 0.4*0.3 0.6*0.5 s1=>s1=>s2=>s3 が一番尤もらしい経路 39. Viterbi のアルゴリズムの 形態素解析への利用 “ 東京都”が出現したときに ,” 東京都”が出力される系列中で尤もらしいものを探す . 開始 ->“ 東” -> “ 京都” 開始 ->“ 東京” ->” 都” 開始 ->“ 東京都” 品詞連接確率が遷移確率 単語の出現確率が出力する確率 として Viterbi のアルゴリズムを適用


![はじめに 本資料の作成に辺り以下のサイト ( アーティクル ) を参考にさせていただきました。 日本語形態素解析入門 [ 山下達雄 ] http://nais.to/~yto/doc/tech/jma/jma19990514.pdf Double-Array Articles [ 矢田 晋 ] http:// nanika.osonae.com/DArray / 確率的言語モデルによる自由発話認識に関する研究 [ 村上仁一 ] http://unicorn.ike.tottori-u.ac.jp/murakami/doctor/](https://image.slidesharecdn.com/ss-1233139559568445-1/85/slide-2-320.jpg)











![Double Array概要 Double Arrayは小さい領域で高速な実装 2つの配列BASEとCHECKを用いてデータを格納する 節 x から節 y に至る文字 c に対応する枝が存在するとき BASE[x]+CODE[c]=y x = CHECK[y] が成り立つ。 また , x が葉 BASE[x] < 0](https://image.slidesharecdn.com/ss-1233139559568445-1/85/slide-14-320.jpg)
![Double Array Trie による文字列探索 “bird”を検索 BASE[1]+CODE[‘b’] = 4, CHECK[4]=1 BASE[4]+CODE[‘i’] = 7, CHECK[7]=4 BASE[7]+CODE[‘r’] = 10, CHECK[10] = 7 BASE[10]+CODE[‘d’] = 6, CHECK[6] = 10 BASE[6] + CODE[‘#’] = 2, CHECK[2]=6 BASE[2] < 0 “bird” が見つかった!!](https://image.slidesharecdn.com/ss-1233139559568445-1/85/slide-15-320.jpg)