Download to read offline



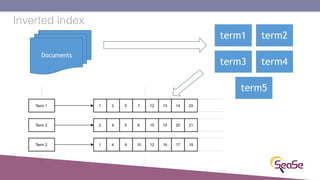

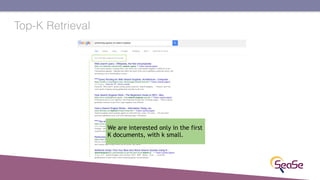
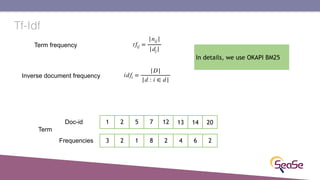
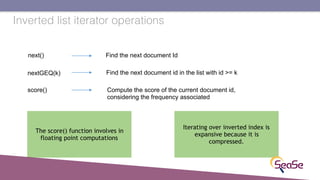



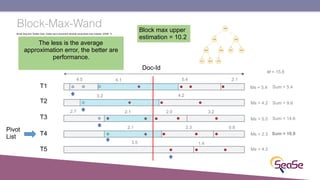

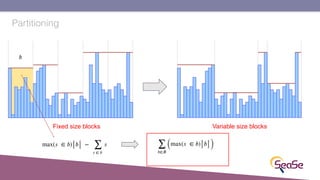
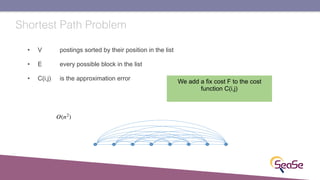
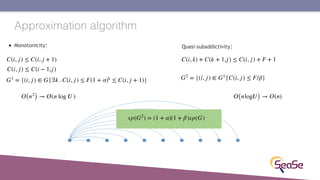

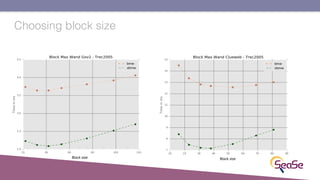
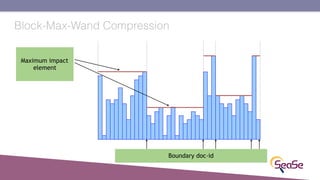
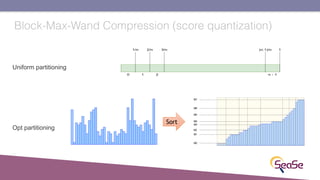
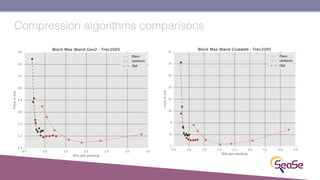
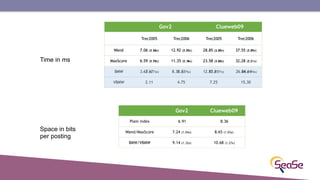
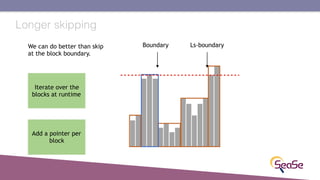
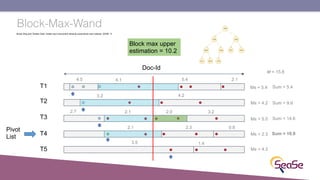



The London Information Retrieval Meetup on February 19, 2019, featured a presentation by Elia Porciani discussing improvements in top-k retrieval algorithms through dynamic programming and longer skipping techniques. Key topics included inverted indexes, early termination techniques, and compression methods for posting lists, emphasizing the efficiency of top-k document retrieval. The session highlighted various experimental analyses and comparisons of different retrieval algorithms, illustrating substantial performance enhancements in search engine queries.






















































































