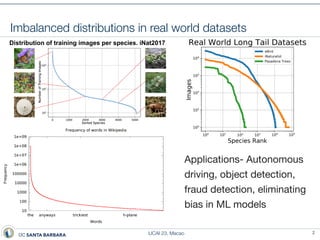
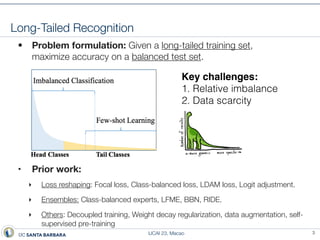
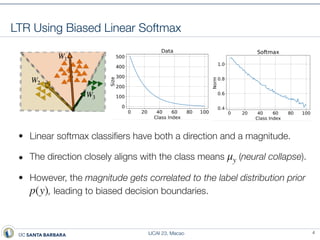
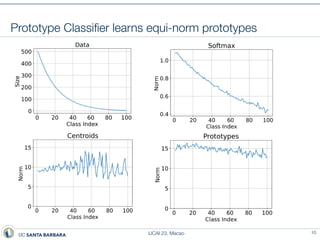
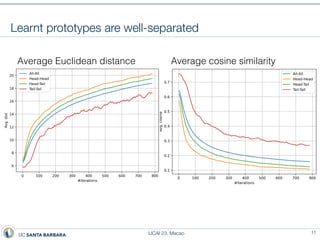
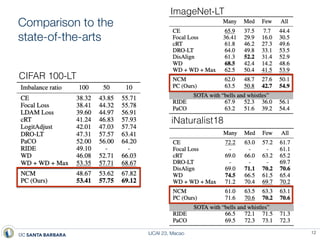
This document presents a method called prototype classifiers for long-tailed recognition (LTR). Prototype classifiers learn a prototype representation for each class and classify examples based on distance to the prototypes. This overcomes biases in linear softmax classifiers caused by imbalanced class distributions. The prototypes are learned to be equi-norm and well-separated. Evaluation on long-tailed benchmarks like CIFAR-100-LT and ImageNet-LT shows prototype classifiers outperform state-of-the-art LTR methods.







































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)














