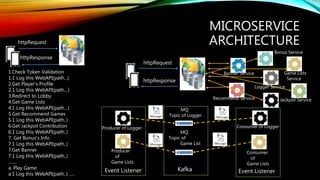
MICROSERVICE
ARCHITECTUREhttpRequest
httpResponse
1.Check Token Validation
1.1Log this WebAPI(path...)
2.Get Player’s Profile
2.1 Log this WebAPI(path…)
3.Redirect to Lobby
4.Get Game Lists
4.1 Log this WebAPI(path…)
5.Get Recommend Games
5.1 Log this WebAPI(path..)
6.Get Jackpot Contribution
6.1 Log this WebAPI(path..)
7. Get Bonus’s Info
7.1 Log this WebAPI(path..)
7.Get Banner
7.1 Log this WebAPI(path..)
…….
a. Play Game
a.1 Log this WebAPI(path..) ..…
httpRequest
httpResponse
Logger Service
Recommend Service
Game Lists
Service
Jackpot Service
Bonus Service
Banner Service
Producer of Logger
Producer
of
Game Lists
MQ
Topic of Logger
MQ
Topic of
Game List
KafkaEvent Listener
Consumer of Logger
Consumer
of
Game Lists
Event Listener
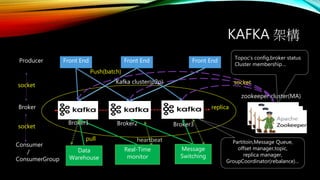
6.
KAFKA 架構
Producer
Broker
Consumer
/
ConsumerGroup
Front EndFront End Front End
Broker2 Broker3
Push(batch)
Data
Warehouse
Real-Time
monitor
pull
Message
Switching
Kafka cluster(p2p)
replica
zookeeper cluster(MA)
Topoc’s config,broker status
Cluster membership…
Partitoin,Message Queue,
offset manager,topic,
replica manager,
GroupCoordinator(rebalance)…
socket
socket
socket
Broker1
heartbeat
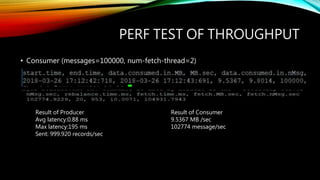
PERF TEST OFTHROUGHPUT
• Consumer (messages=100000, num-fetch-thread=2)
Result of Producer
Avg latency:0.88 ms
Max latency:195 ms
Sent: 999.920 records/sec
Result of Consumer
9.5367 MB /sec
102774 message/sec
#6 Business drawback
1.Maybe reduce revenue
Technical drawbacks
1.Result in dependencies
2.Failure affects everything
3.Chang is slow
#7 Do not co-locate zookeeper on the same boxes as Kafka
Zookeeper->Topic 有哪些Partition, Replica 存放在哪里, Leader 是誰
Controller :負責所有Partition 的leader/follower 關係
Zookeeper主要監控broker狀態,kafka依賴他達成資料一致性(sync),透過zook選出leade的partition,Leader負責讀寫、把每個partition分散在每台broker
如果有某一個broker掛了,zookeeper也會通知producer and consumer
Zookeeper cluster基本3台較好,奇數比較可以避免整個cluster crash(過半就crash)
Sync,這一步leader開始分配消費方案,即哪個consumer負責消費哪些topic的哪些partition。一旦完成分配,leader會將這個方案封裝進SyncGroup請求中發給coordinator,非leader也會發SyncGroup請求,只是內容為空。coordinator接收到分配方案之後會把方案塞進SyncGroup的response中發給各個consumer。這樣組內的所有成員就都知道自己應該消費哪些分區了
P2P(peer 2 peer):好處是沒有單點問題,壞處是很難達成資料的一致性和備份,如果其他節點掛了,將導致資料遺失。
#9 Compression=gzip,snap (https://dotblogs.com.tw/ricochen/2017/10/29/052852)
send.buffer.bytes=100*1024、batch.size=100
producer.type=async
max.in.flight.requests.per.connection=5
99%的producer不須tun
acks=-1等待所有ISR接收到消息后再给Producer發送Response(影響durability)
只找partition的leader 溝通並push message
compression codecs ('gzip', 'snappy', 'lz4’)
batch.size太大會timeout,並增加latency ( Total bytes between flush() / partition )
max.block.ms=60000
Linger.ms ( time based batching)
max.in.flight.requests.per.connection=5,由於大於1,如果producer發送失敗會retry,這是會影響排序
High batch=high throughput =High latency
#10 https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
更多partition可以提高throughput 降低latency降低records queue time
message.max.bytes=1000012
sure you set replica.fetch.max.bytes to be equal or greater than message.max.bytes
log.flush.interval.messages=10000 higher will improver performance
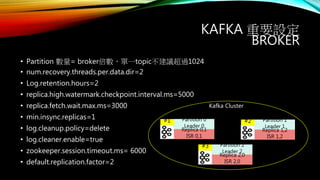
min.insync.replicas=2
num.network.threads=配置线程数量为cpu核数加1.
num.io.threads= 配置线程数量为cpu核数2倍,最大不超过3倍.
num.replica.fetchers 配置多可以提高follower的I/O并发度,单位时间内leader持有跟多请求,相应负载会增大,需要根据机器硬件资源做权衡
replica.fetch.min.bytes=1 太大可能follower讀取消息不及時
replica.fetch.max.bytes= 1MB,这个值太小,5MB为宜,根据业务情况调整
replica.high.watermark.checkpoint.interval.ms=5000
replica.fetch.wait.max.ms=500 follow拉取频率,频率过高,会导致cpu飙升,因为leader无数据同步,leader会积压大量无效请求情况,影響吞吐量
#11 https://dotblogs.com.tw/ricochen/2017/10/29/015517
max.poll.records=5000
fetch.max.wait.ms=500
fetch.min.bytes=1
只找partition的leader溝通poll message
At most once—Messages may be lost but are never redelivered.
At least once—Messages are never lost but may be redelivered.
Exactly once—this is what people actually want, each message is delivered once and only once.
数据一致性保证
一致性定义:若某条消息对Consumer可见,那么即使Leader宕机了,在新Leader上数据依然可以被读到
1.HighWaterMark简称HW: Partition的高水位,取一个partition对应的ISR中最小的LEO作为HW,消费者最多只能消费到HW所在的位置,另外每个replica都有highWatermark,leader和follower各自负责更新自己的highWatermark状态,highWatermark <= leader. LogEndOffset
2.对于Leader新写入的msg,Consumer不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被Consumer消费,即Consumer最多只能消费到HW位置
这样就保证了如果Leader Broker失效,该消息仍然可以从新选举的Leader中获取。对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里
#12 Zookeeper:Make sure you allocate sufficient JVM , good starting point is 4Gb
Min/MaxMetaspaceFreeRatio:avoid high frequency trigger GC
MaxGCPauseMillis:设置最大GC停顿时间(GC pause time)指标(target). 这是一个软性指标(soft goal), JVM 会尽量去达成这个目标.
InitiatingHeapOccupancyPercent:启动并发GC周期时的堆内存占用百分比. G1之类的垃圾收集器用它来触发并发GC周期,基于整个堆的使用率,而不只是某一代内存的使用比. 值为 0 则表示"一直执行GC循环". 默认值为 45.
G1HeapRegionSize:使用G1时Java堆会被分为大小统一的的区(region)。此参数可以指定每个heap区的大小. 默认值将根据 heap size 算出最优解. 最小值为 1Mb, 最大值为 32Mb.
頻繁GC會讓application 延遲
G1也是并发收集器,G1解决了CMS碎片,同时增加了更多响应时间优先的特性。
-XX:G1HeapRegionSize=4m: 设置内存分块的大小。范围是1MB~32MB。是一个很常用的参数。当系统中存在大量大对象的时候,大的Region会提升GC效率。
XX:InitiatingHeapOccupancyPercent=50: 设置使用整个对的x%时,系统开始进行并行GC。注意是整个堆的百分比。这与CMS收集器的类似参数不同
-XX:MaxGCPauseMillis=200: 单位为毫秒。此值为建议JVM的最长暂停时间。只是建议值,G1只能尽量保证,而无法完全保证。
Tuning JVM Garbage Collection for Production Deployments
https://docs.oracle.com/cd/E40972_01/doc.70/e40973/cnf_jvmgc.htm
Garbage First Garbage Collector Tuning
http://www.oracle.com/technetwork/articles/java/g1gc-1984535.html
#13 1.HA test
2.Message delivery test
3.Auto rebalance(RR) test
4.Message order test