Downloaded 37 times
















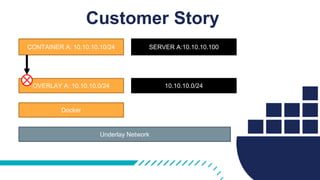
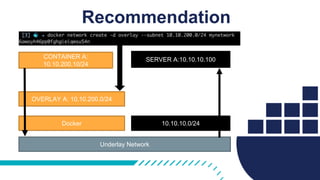



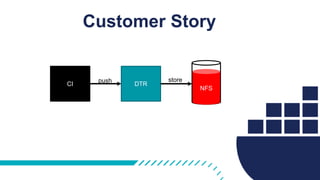



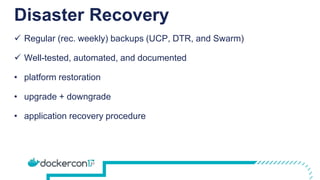









The document provides a comprehensive Docker production readiness checklist for enterprise IT, focusing on critical aspects like infrastructure, orchestration management, security, and disaster recovery. It outlines specific requirements for clusters, image storage, network design, and logging, emphasizing the importance of monitoring and integration. Additionally, the document highlights the necessity of regular backups and testing to ensure efficient operations and disaster recovery in a Docker environment.



































































