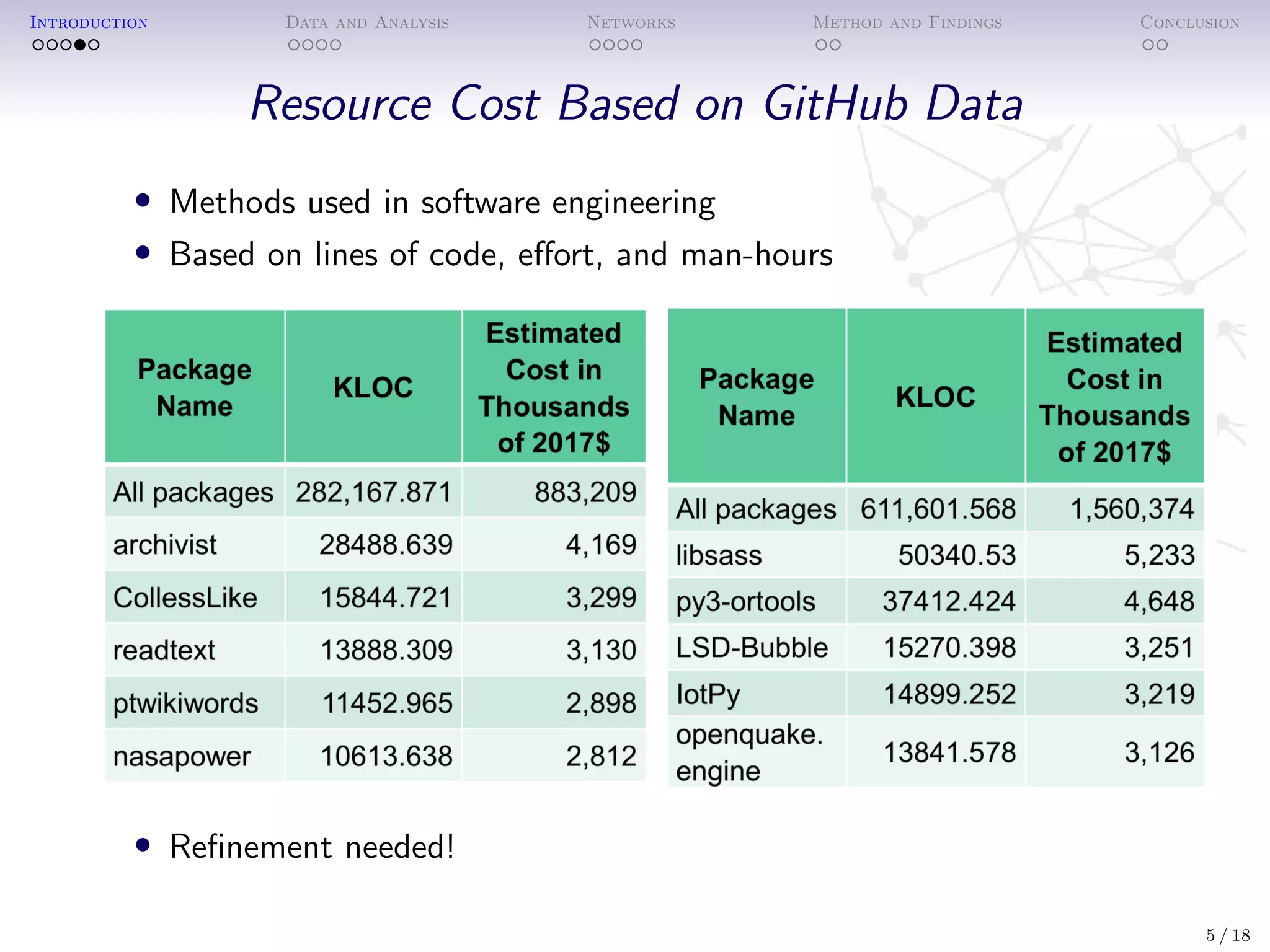
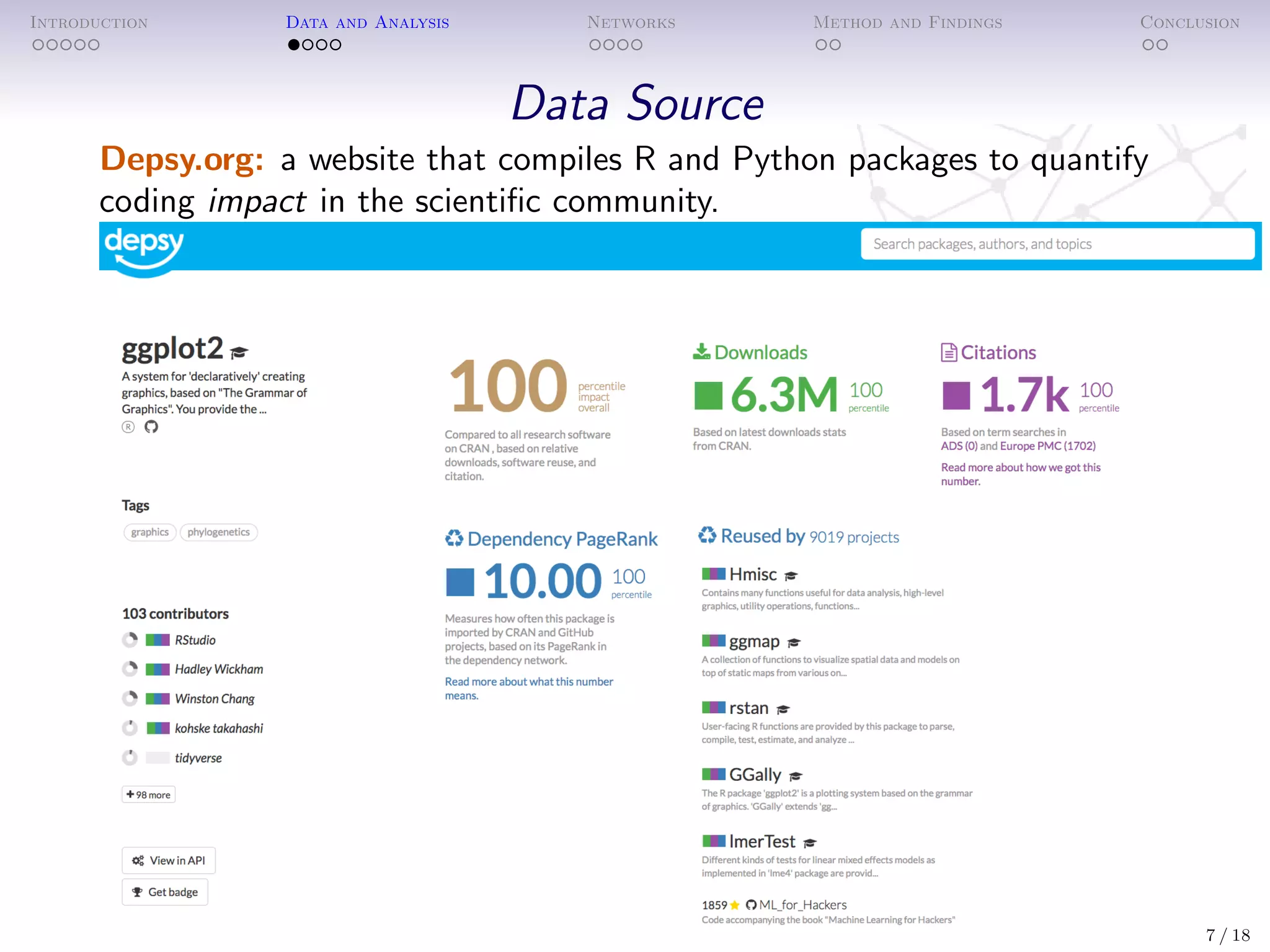
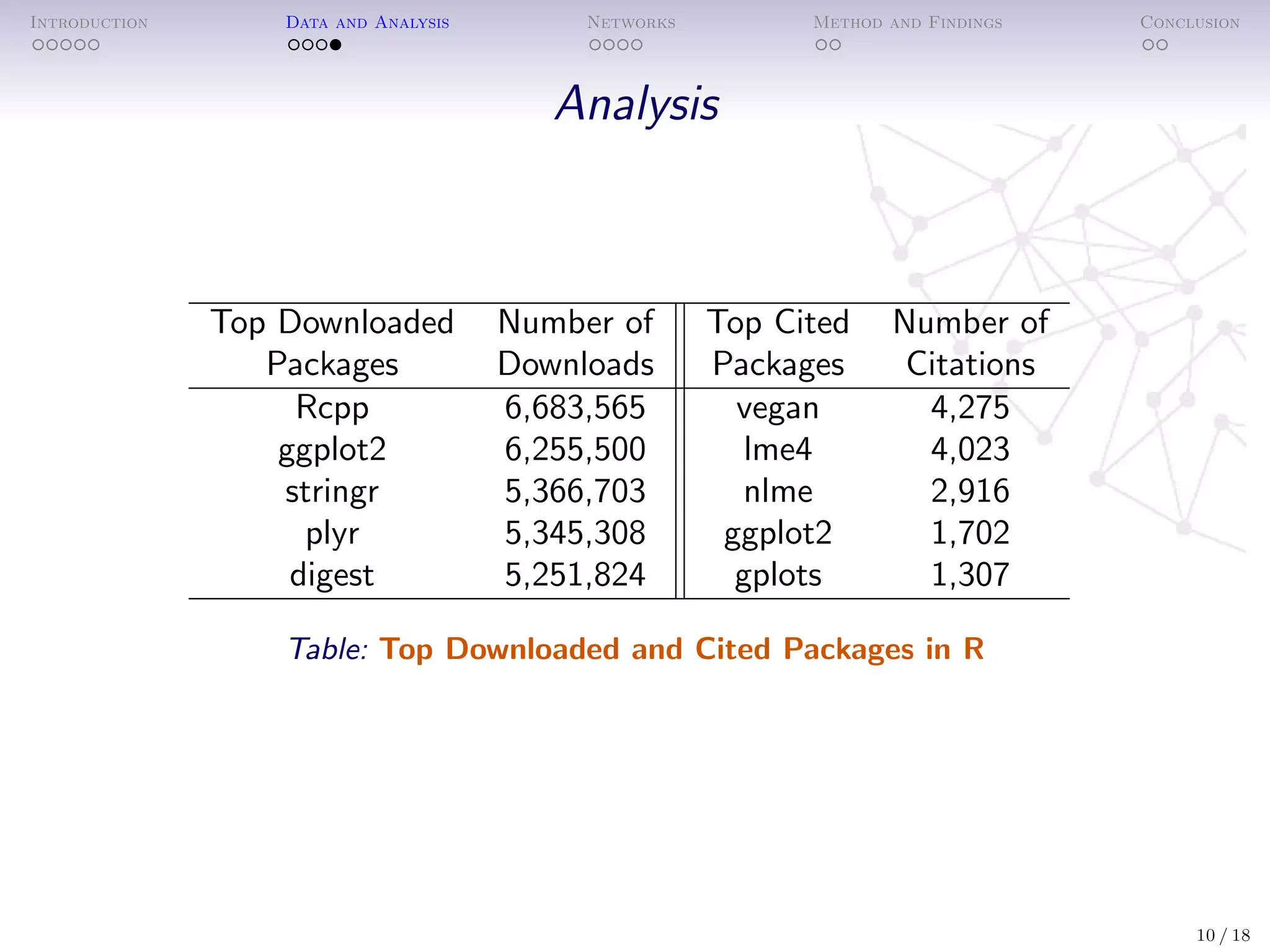
The document analyzes the impact of open-source software (OSS) packages, specifically focusing on R and Python, using methods from bibliometrics and network analysis. It details the collection of data on numerous packages, their contributors, and the relationships between them, ultimately developing statistical models to understand factors affecting package impact as measured by downloads and citations. Findings suggest that more derivative packages tend to have lower impact, and highlighting the importance of network centrality and package features in determining success.

![Introduction Data and Analysis Networks Method and Findings Conclusion
Introduction
• Open Source Software (OSS) is a computer software with its
source code made available with a license in which the copyright
holder provides the rights to study, change, and distribute the
software to anyone and for any purpose [Open Source Initiative,
1998].
• within and outside of the private sector
• universities (e.g., Stanford, MIT, UC-Berkeley), business (e.g.,
Microsoft, Google), government research institutions (e.g., Sandia
National Lab), nonprofits, and individuals
• Examples include Linux, Apache, Python, and R.
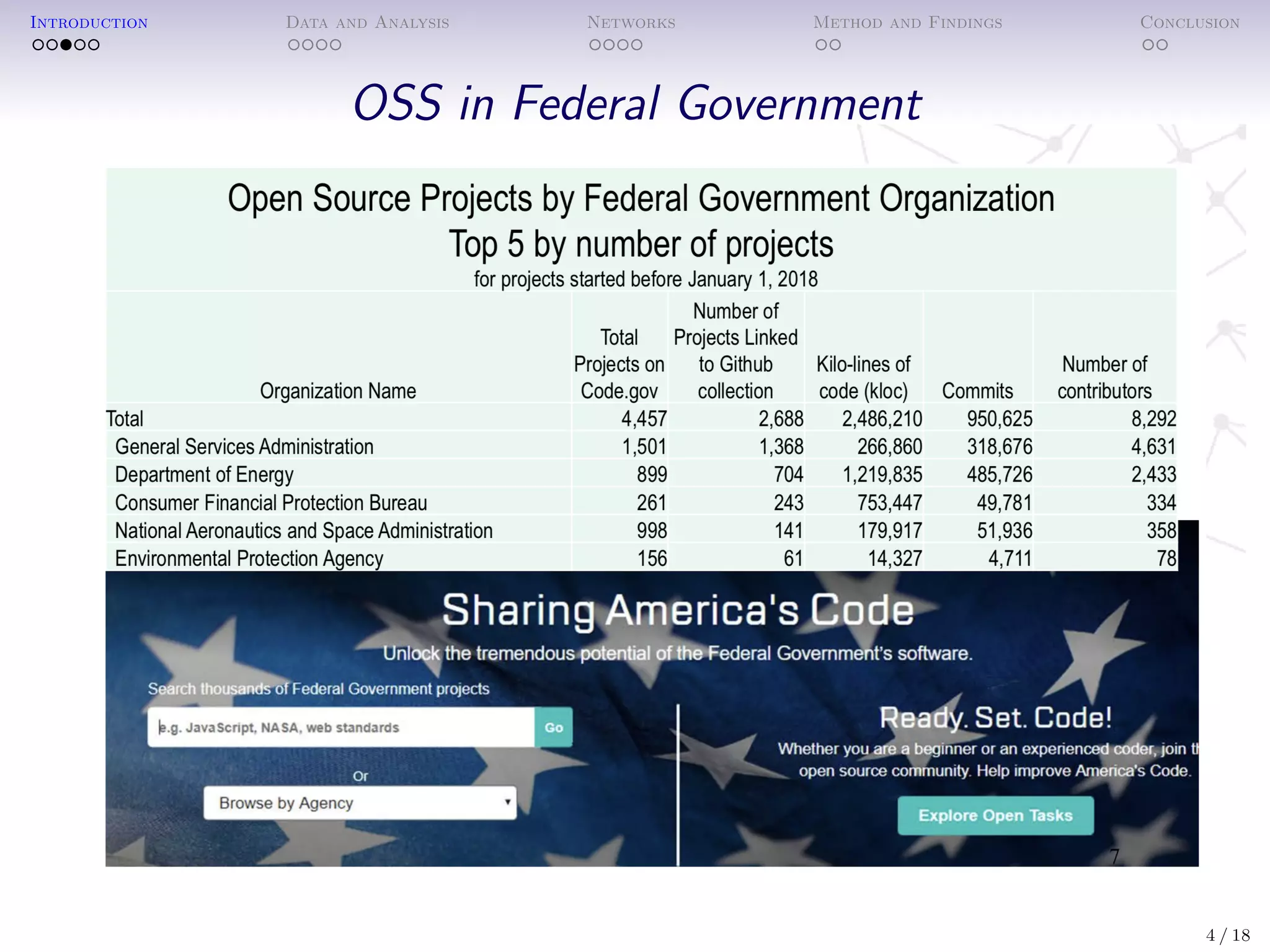
• Public funding for OSS is not fully accounted!
2 / 18](https://image.slidesharecdn.com/wids2019-korkmaz-slides-final-190427180831/75/Modeling-the-Impact-of-R-Python-Packages-Dependency-and-Contributor-Networks-2-2048.jpg)








































































![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Danica Soc - The Science Behind Marketing: Experimentation me...](https://cdn.slidesharecdn.com/ss_thumbnails/c0nofsggs9gw5ucmallr-3-251216103155-56bd64d1-thumbnail.jpg?width=640&height=640&fit=bounds)

