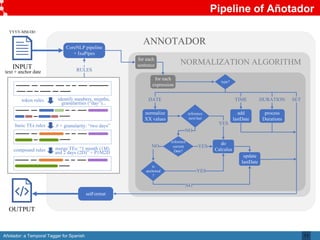
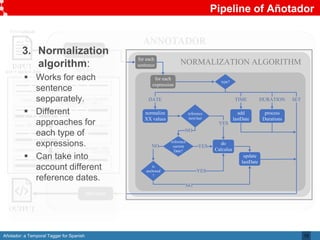
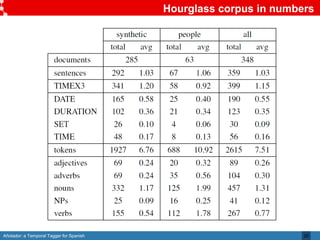
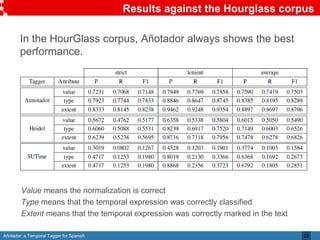
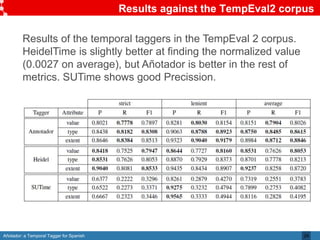
Añotador is a temporal tagger for Spanish created by researchers at the Universidad Politécnica de Madrid. It detects and normalizes temporal expressions like dates, times, durations, and sets in Spanish text. The researchers built a corpus called Hourglass to evaluate temporal taggers for Spanish, as existing resources were limited. Añotador achieved the best performance on the Hourglass corpus compared to other taggers. While Añotador performed well, the researchers note there is still work to be done, such as improving handling of challenging temporal expressions.






![Añotador: a Temporal Tagger for Spanish
Corpora
7
A lot in English!
o News:
• Timebank corpus [1]
• TempEval challenges datasets [2]
• MEANTIME corpus [3]
o Medical: THYME [4]
o Historical: Wikiwars corpus [5]
o Scientific: Abstracts [6]
o Colloquial: SMS [6] and tweets [7]
Less for Spanish…
o News: The Spanish TimeBank corpus [8], MEANTIME [3]
o Historical: The ModeS TimeBank 1.06 (texts from the 17th and
18th centuries) [9]
* TempEval 2 and TempEval 3 challenges (fragment of TimeBank)](https://image.slidesharecdn.com/2019-191104154443/85/Anotador-a-Temporal-Tagger-for-Spanish-7-320.jpg)
![Añotador: a Temporal Tagger for Spanish
Temporal Taggers
8
A lot in English!
o Rule-based:
• HeidelTime [10]
• SUTime* [11]
• SynTime [12]
o Machine-Learning-based
• ClearTK-TimeML [13]
• USFD2 [14]
• UWTime [15]
• TARSQI [16]
• CAEVO [17]
• TIPSem [18]
For Spanish, just the bold ones… (there are more in
literature, but we could not find them available!)
No corpora, no taggers!](https://image.slidesharecdn.com/2019-191104154443/85/Anotador-a-Temporal-Tagger-for-Spanish-8-320.jpg)