Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
KK
Uploaded by
Kurumi Kurogi
PPTX, PDF
106 views
読み手の印象推定に基づくツイートのフィルタリングに関する研究
読み手の印象推定に基づくツイートのフィルタリングに関する研究 DEIM Forum 2017 D5-1 http://db-event.jpn.org/deim2017/papers/126.pdf
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PPTX
話題呼
by
eppii
PPTX
100608 キックオフ課題 鈴木 ver.1
by
argent ARG agents
PDF
マスメディアの広告効果が薄れた原因とは脳の退化?進化?
by
新潟コンサルタント横田秀珠
PPTX
第2回yokotter会議配布用20100123
by
Takuma Hosoya
ODP
第十一回課題
by
Hiroki Yoshida
PPT
Twittermap
by
twmap
PDF
UX勉強会(第十三章)
by
大騎 池本
PPT
【オプト】20110720twitterセミナー資料
by
Osamu Ise
話題呼
by
eppii
100608 キックオフ課題 鈴木 ver.1
by
argent ARG agents
マスメディアの広告効果が薄れた原因とは脳の退化?進化?
by
新潟コンサルタント横田秀珠
第2回yokotter会議配布用20100123
by
Takuma Hosoya
第十一回課題
by
Hiroki Yoshida
Twittermap
by
twmap
UX勉強会(第十三章)
by
大騎 池本
【オプト】20110720twitterセミナー資料
by
Osamu Ise
What's hot
PPTX
マイニング探検会 #01
by
Yoji Kiyota
PPTX
[WWW Conference 2011]Information Credibility on Twitter
by
Kenji Koshikawa
PDF
Twitter講習会20100922
by
Shinya ICHINOHE
PPT
Twitter講習会 #2 100922
by
Shinya ICHINOHE
PPTX
こすぎの大学(第11回)
by
Dementia Friendly Japan Initiative
PPTX
BookRecommender 発表資料
by
Yuki Nihei
PDF
最近話題の「個」の行動分析
by
Shinichiro Oho
PPTX
Hacker
by
Yosuke Fujii
PPT
イマココ新聞の取説
by
Masafumi Okura
PPTX
医学部朝活Exe第1回
by
Yuuki Tazawa
PPTX
研究活動におけるTwitter活用法
by
Hiroshi Unzai
マイニング探検会 #01
by
Yoji Kiyota
[WWW Conference 2011]Information Credibility on Twitter
by
Kenji Koshikawa
Twitter講習会20100922
by
Shinya ICHINOHE
Twitter講習会 #2 100922
by
Shinya ICHINOHE
こすぎの大学(第11回)
by
Dementia Friendly Japan Initiative
BookRecommender 発表資料
by
Yuki Nihei
最近話題の「個」の行動分析
by
Shinichiro Oho
Hacker
by
Yosuke Fujii
イマココ新聞の取説
by
Masafumi Okura
医学部朝活Exe第1回
by
Yuuki Tazawa
研究活動におけるTwitter活用法
by
Hiroshi Unzai
読み手の印象推定に基づくツイートのフィルタリングに関する研究
1.
読み手の印象推定に基づく ツイートのフィルタリングに関する研究 九州大学芸術工学部芸術情報設計学科 黒木クルミ 九州大学大学院芸術工学研究院 牛尼剛聡 D5-1
2.
背景 Twitter 国内月間利用者数4000万以上の社会インフラ 興味があるものをフォローできる トピックで検索できる 1 情報発信 コミュニ ケーション 情報収集 暇つぶし 息抜き
3.
暇つぶしには何が有効か 暇つぶしを目的にTwitterを使うとき、ユーザは「なりたい 気分になること」を求めている 2 ユーザ 何か楽しい ことないかな 何か面白い ことないかな 楽しい気分になりたい 面白い気持ちになりたい ユーザが希望する印象が得られるツイートを得られることができれば ユーザの満足度が高くなると期待できる
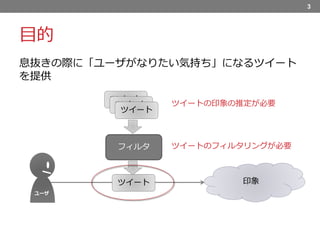
4.
目的 息抜きの際に「ユーザがなりたい気持ち」になるツイート を提供 3 ツイート 印象 ツイートの印象の推定が必要 フィルタ ツイート ツイート ツイート ツイートのフィルタリングが必要 ユーザ
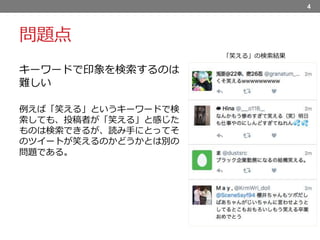
5.
問題点 キーワードで印象を検索するのは 難しい 例えば「笑える」というキーワードで検 索しても、投稿者が「笑える」と感じた ものは検索できるが、読み手にとってそ のツイートが笑えるのかどうかとは別の 問題である。 4 「笑える」の検索結果
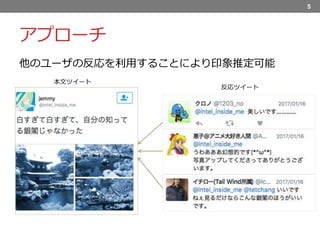
6.
アプローチ 5 本文ツイート 反応ツイート 他のユーザの反応を利用することにより印象推定可能
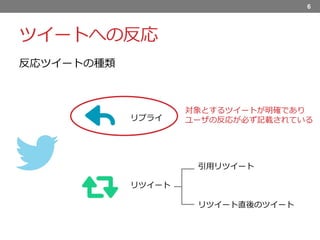
7.
ツイートへの反応 6 リプライ リツイート 反応ツイートの種類 引用リツイート リツイート直後のツイート 対象とするツイートが明確であり ユーザの反応が必ず記載されている
8.
関連研究 「Twitterにおける発話者へのリプライを用いたユーザ感情 推定手法」 堀宮ありさ,坂野 遼平,佐藤 晴彦,小山
聡,栗原 正仁,沼澤 政信 2012 - ラベルを6感情「驚き」,「悲しみ」などに人手で分類し,それを 正解データとしている - 2-gramのtf-idfで重みを計算し,SVMで判別 「ユーザの反応を利用したネタツイート自動分類手法」 林田宗一郎,牛尼剛聡 2014 - ユーザの目的や価値に応じたツイートのカテゴリの代表例として 「ネタツイート」を対象 - 2-gramの出現頻度を足し合わせたものを特徴量とし,SVMで判別 7
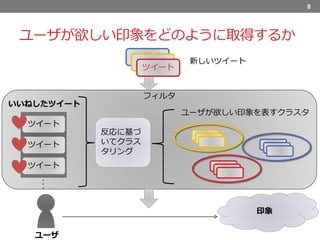
9.
8 フィルタ 印象 ツイート ツイート ツイート ユーザ ツイート ツイート ツイート ユーザが欲しい印象を表すクラスタ 反応に基づ いてクラス タリング ・ ・ ・ いいねしたツイート ユーザが欲しい印象をどのように取得するか 新しいツイート
10.
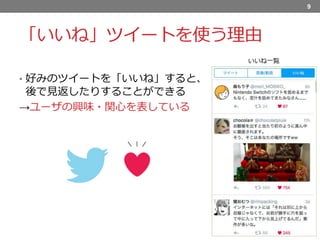
「いいね」ツイートを使う理由 • 好みのツイートを「いいね」すると、 後で見返したりすることができる →ユーザの興味・関心を表している 9 いいね一覧
11.
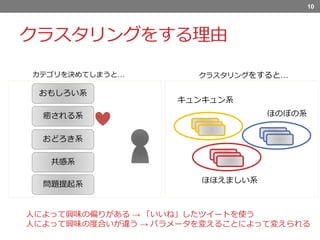
クラスタリングをする理由 カテゴリを決めてしまうと… 10 おもしろい系 癒される系 おどろき系 共感系 問題提起系 人によって興味の偏りがある → 「いいね」したツイートを使う 人によって興味の度合いが違う
→ パラメータを変えることによって変えられる キュンキュン系 ほのぼの系 ほほえましい系 クラスタリングをすると…
12.
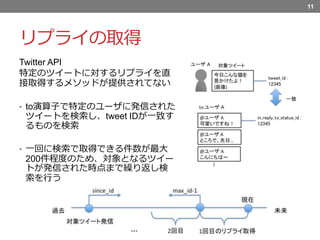
リプライの取得 Twitter API 特定のツイートに対するリプライを直 接取得するメソッドが提供されてない • to演算子で特定のユーザに発信された ツイートを検索し、tweet
IDが一致す るものを検索 • 一回に検索で取得できる件数が最大 200件程度のため、対象となるツイー トが発信された時点まで繰り返し検 索を行う 11
13.
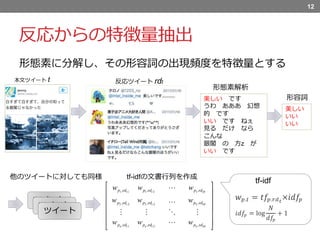
反応からの特徴量抽出 形態素に分解し、その形容詞の出現頻度を特徴量とする 12 美しい です うわ あああ
幻想 的 です いい です ねぇ 見る だけ なら こんな 銀閣 の 方z が いい です 形態素解析 本文ツイート t 反応ツイート rdt 形容詞 美しい いい いい ツイート ツイート ツイート 他のツイートに対しても同様 tf-idfの文書行列を作成 tf-idf
14.
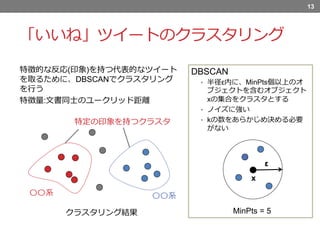
「いいね」ツイートのクラスタリング 特徴的な反応(印象)を持つ代表的なツイート を取るために、DBSCANでクラスタリング を行う 特徴量:文書同士のユークリッド距離 13 DBSCAN • 半径ε内に、MinPts個以上のオ ブジェクトを含むオブジェクト xの集合をクラスタとする • ノイズに強い •
kの数をあらかじめ決める必要 がない MinPts = 5 x ε クラスタリング結果 特定の印象を持つクラスタ 〇〇系 〇〇系
15.
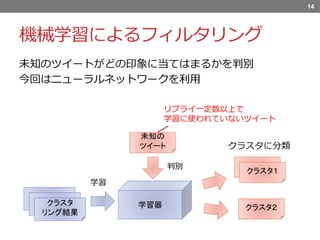
機械学習によるフィルタリング 14 学習器 学習 判別 未知の ツイート クラスタ2 不正解 クラスタ1 クラスタ リング結果 未知のツイートがどの印象に当てはまるかを判別 今回はニューラルネットワークを利用 クラスタに分類 リプライ一定数以上で 学習に使われていないツイート
16.
目的 反応ツイートに基づいて正しくクラスタリングできるか 方法 テストデータに対して提案手法に沿ってクラスタリングを行う 実験1 実験 •
テストデータ - 著者のお気に入りした中のリプライ数が10以上のツイート(117件) - 反応数10~405件 平均約65件 • 評価 - 著者自身が主観的に判断 15 目的 クラスタリングで得られたカテゴリに正しくフィルタリングできるか 方法 実験1で得られた最も良いクラスタを利用して、テストデータを分類 実験2 • テストデータ - ツイッターに投稿されたリプライ数が10件以上のツイート(15件) • フィルタリング方法 - ニューラルネットワーク • 評価 - 著者自身が主観的に判断
17.
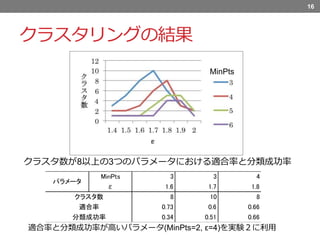
クラスタリングの結果 クラスタ数が8以上の3つのパラメータにおける適合率と分類成功率 16 MinPts MinPts 3 3
4 ε 1.6 1.7 1.8 8 10 8 0.73 0.6 0.66 0.34 0.51 0.66 パラメータ クラスタ数 適合率 分類成功率 適合率と分類成功率が高いパラメータ(MinPts=2, ε=4)を実験2に利用
18.
クラスタリングの内容 17 →美味しそう系 →かわいい系 クラスタ2 クラスタ3 成功例 MinPts=4,
ε=1.8 クラスタID 1 2 3 4 5 6 7 8 解釈 問題提起系 美味しそう系 かわいい系 感嘆系 懐かしい系 問題提起系 おもしろ系 ? 個数 8 5 21 22 4 7 4 6 正解数 5 4 21 9 4 4 4 0 反応ツイート 反応ツイート
19.
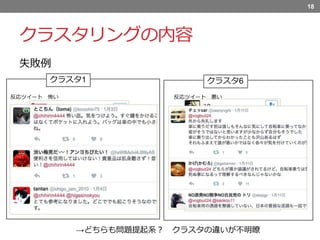
失敗例 18 クラスタ1 クラスタ6 →どちらも問題提起系? クラスタの違いが不明瞭 反応ツイート
怖い 反応ツイート 悪い クラスタリングの内容
20.
目的 反応ツイートに基づいて正しくクラスタリングできるか 方法 テストデータに対して提案手法に沿ってクラスタリングを行う 実験1 実験 •
テストデータ - 著者のお気に入りした中のリプライ数が10以上のツイート(117件) - 反応数10~405件 平均約65件 • 評価 - 著者自身が主観的に判断 19 目的 クラスタリングで得られたカテゴリに正しくフィルタリングできるか 方法 実験1で得られた最も良いクラスタを利用して、テストデータを分類 実験2 • テストデータ - ツイッターに投稿されたリプライ数が10件以上のツイート(15件) • フィルタリング方法 - ニューラルネットワーク • 評価 - 著者自身が主観的に判断
21.
フィルタリングに対する評価 フィルタリング方法:ニューラルネットワーク • 学習データをフィルタリングした結果 - 正解率
116/117件 = 0.99 • 実験1のデータを用いた場合のフィルタリング結果 - 正解率 8/15件 = 0.53 20 ツイート 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 正解クラスタ C3 C7 C7 C1 C7 C3 C4 C6 C3 0 C3 C1 0 C7 C3 NN結果 C3 C4 C4 0 0 C3 C4 C6 C3 0 C3 C4 0 C4 0
22.
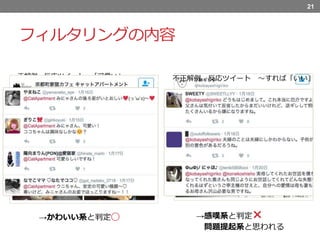
フィルタリングの内容 正解例 反応ツイート 「可愛い」 21 →かわいい系と判定◯
→感嘆系と判定× 問題提起系と思われる 不正解例 反応ツイート 〜すれば「いい」
23.
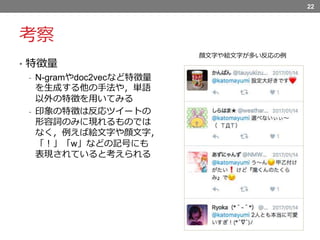
考察 • 特徴量 - N-gramやdoc2vecなど特徴量 を生成する他の手法や,単語 以外の特徴を用いてみる -
印象の特徴は反応ツイートの 形容詞のみに現れるものでは なく,例えば絵文字や顔文字, 「!」「w」などの記号にも 表現されていると考えられる 22 顔文字や絵文字が多い反応の例
24.
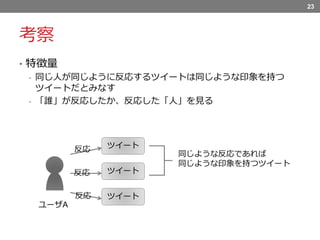
考察 • 特徴量 - 同じ人が同じように反応するツイートは同じような印象を持つ ツイートだとみなす -
「誰」が反応したか、反応した「人」を見る 23 ツイート ツイート ツイート 反応 ユーザA 反応 反応 同じような反応であれば 同じような印象を持つツイート
25.
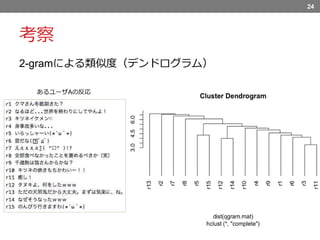
考察 2-gramによる類似度(デンドログラム) 24 あるユーザAの反応
26.
課題 • 対象ツイート - 反応がないツイートや,ユーザのお気に入りの量が少ない場合は 使えない -
対象件数増やす - ユーザのお気に入りでないものとも比較 • フィルタリング方法 - 機械学習のパラメータなどの調整を行う • 評価 - 被験者実験など実施し,より客観性のある評価を得て有効性を確 かめる 25
27.
まとめ 概要 • ユーザの希望する印象を持つツイートを提供するため、 ツイートの印象推定をすることを目的 • 「いいね」したツイートの反応ツイートを取得 •
その形容詞のtf-idf値を特徴量としたクラスタリング • その結果を正解データとして機械学習でフィルタリング • 実験の正誤は半々程度 今後の課題 • 形容詞以外の特徴を用いたクラスタリング • 人による反応の違いを使ったアプローチ 26
28.
27 ご静聴ありがとうございました
Editor's Notes
#2
今から九州大学の黒木が発表します タイトルは読み手の印象推定に基づくツイートのフィルタリングに関する研究です
#3
現在Twitterは〜であり、〜したり、〜することが可能です。 そのような中で、Twitterはいろんな人がいろんな目的に使っている その目的とは ・情報発信 ・情報収集 ・コミュニケーション ・暇つぶし・息抜き 本研究では息抜きとしての目的に注目しました ─────────────── ユーザーの興味を見つける 単にトピックではなく~
#4
暇つぶしを目的にTwitterを使うとき、〜と考えられます。 例えば、〜、〜という場合において、〜、〜ということを求めていると考えられます。 つまり、〜
#5
そこで本研究は、息抜きの際にユーザがなりたい気持ちになるツイートを提供することを目的とします あるツイートを読んである気分になることを、ツイートが持つ印象と呼びます. このツイートを選ぶためには、数あるツイートの中からフィルタリングが必要です. また、そのフィルタリングをするために、これらのツイートの印象推定が必要になります。
#6
そこで問題となることは、〜ということが挙げられます。 例えばこのように、〜
#7
そこで、アプローチとして、他のユーザの反応を利用することを考えます。 例えばここに、〜というツイートがあるとして、本文のみでは、白い,とか銀閣,ということはわかるかもしれませんが そのツイートがどのような印象を与えるのかはわかりません。 ,一方、反応においては、このように〜のような印象に関連する言葉が出てくる場合があるため、 これらを使って印象を推定していきます。
#8
あるツイートの内容をふまえて投稿されるツイートを「反応ツイート」と呼ぶ. Twitterでは,反応ツイートを投稿するために,いくつかの方法が存在します. 具体的には,リプライ,引用ツイート,リツイート直後のツイートなどである. 本研究では,対象とするツイートが明確であり,ユーザの反応が必ず記載されているリプライを対象とする.
#9
関連研究についてです まず,〜という研究では,同じようにリプライを用いてユーザの感情を推定するものがありますが,これはまず人手でラベルを〜など6感情で分類し, それに対して〜のようにしています 〜という研究では,〜を対象としたもので,ツイートがネタかそうでないかを分類し,判別しています. 本研究ではネタツイートを含めた,より一般的な印象を持つツイートを対象としています. また,感情分析・センチメントのような指標を用いないことによって,言語化しにくい印象も取れるのではないかと考えて研究を進めました.
#10
ユーザが欲しい印象をどのように取得するかについてですが、 まずユーザがお気に入りしたツイートを反応に基づいてクラスタリングします。 その結果として出されたクラスタがユーザの欲しい印象を表すという仮説を立てます. これらのクラスタを正解データとしてフィルタリングを行ないます。 ユーザがこの中の一つを選ぶと、それと同じ印象を持つツイートをユーザに提示します。
#11
Twitterの「いいね」機能についてですが、〜するとこのように一覧となって後で〜
#12
クラスタリングする理由は 例えば癒される系のツイートを多く好むユーザーがいたとして、 先にカテゴリを決めてしまうと、癒される系以外のカテゴリはそのユーザにとってはあまり有益ではない可能性が高くなります。 また、癒される系の中で細かく分類されているものが見たい時もあれば、 幅広いカテゴリを見たい場合もあります。 これらの問題に対しては、お気に入りを使ってパラメータを変えながらクラスタリングをすることによって動的に対応することができます。 ─────────────── 8 ユーザによって違う 階層で決めるよりも 動的にその人にあった りゅうど
#13
リプライの取得には、TwitterAPIを用います。 〜 そこで,to演算子を指定することで特定のユーザに発信されたツイートの検索を行い、対象ツイートとのツイートのIDが一致するかを調べて,リプライを取得する. また、〜工夫を行いました。 ─────────────── ツイートを検索する際のパラメータとして,指定したツイートIDより過去のツイートのみを取得するmax_id 指定したツイートIDより未来のツイートのみを取得するsince_idがある. また,ツイートIDは未来に投稿されたものほど数が大きくなるように設定されている. また,検索結果は未来のものから取得される. そこで,since_idに対象ツイートのツイートIDを指定し,2回目以降の検索ではそれに加えmax_idに前回取得した反応ツイートのツイートIDから1を引いたものを指定する. これを繰り返すことによってより効率的に反応ツイートを取得する.
#14
特徴量を取るために,反応を形態素に分割し,その形容詞の出現頻度を求めます 先ほどの例で言えば,このように形態素で分割され,形容詞である「美しい」,「いい」などの言葉が抽出されます。 これを他のツイートに対しても同様にして、ツイートごとの特徴量を抽出します。
#15
文書同士のユークリッド距離を特徴量として用いて,DBSCNAでクラスタリングを行います DBSCANはノイズに強いということと,生成されるクラスタの数をあらかじめ決める必要がないため、 特徴的な反応つまり印象を持つ代表的なツイートをパラメータによって動的に取得することが可能です。 ─────────────── 10 お気に入りツイートのクラスタリング カテゴリとして使う
#16
クラスタリングをした結果を用いて,機械学習でフィルタリングを行います. クラスタリング結果を正解データとして学習器を作成し,未知のツイートがどのクラスタに属するか判別します 未知のツイートは,リプライが多く,かつクラスタリングに用いられていないツイートから取得しました. 今回は機械学習の手法にニューラルネットワークを利用しました.
#17
評価を求めるために二つの実験を行いました。 まず、実験1では〜 実験2では〜 特徴量の計算以降は統計ソフトであるRを用いました。 まず、実験1についての結果です ─────────────── 11 反応の件数を入れる
#18
まず、DBSCANの密度を決定するパラメータを決定するため, パラメータの値を変化させ,その中でクラスタ数が8以上の3つのパラメータを実験の対象としました. その中で適合率と分類成功率を求め、最も評価が良かった3つ目のパラメータminPts=2とε=4を実験2に利用しました。
#19
クラスタリングの内容と解釈は、このようになりました クラスタは8つ生成され、それぞれの解釈としては〜のようなものがありました クラスタリングの成功例としては、このように分類されました。 お菓子の写真など、美味しそう系と言えるものや、猫や芸能人の写真など、可愛い系と言えるものがありました。 反応を見てみると、やはり「美味しそう」や「可愛い」が多く見られました。
#20
失敗例としては,このようにどちらも問題提起系と言えるような似たような印象のツイートが別々のクラスタに分類され、 クラスタ間での印象の違いが不明瞭でした ただ、反応の特徴量を見てみると、主にクラスタ1は「怖い」と言う単語の共通が多く、「問題だ」と思えるツイートの中でも「怖い」と思える内容のツイートが多かったです。 一方、クラスタ6は、「悪い」と言う単語の共通が多く見られ、どちらが悪いか議論するようなツイートが多かったです。 そう考えてみると、そこまで失敗したとは言えないかもしれません。
#21
次に実験2についての結果です
#22
まず、学習データをそのままテストデータとしてフィルタリングしました。 その場合、117件中1件のみ不正解で、正解率は0.99となり、フィルタリングそのものの精度は問題ないことがわかりました。 実験1のデータを用いたフィルタリング結果は、〜
#23
フィルタリングの内容は、正しく判定された例では,このように可愛いと思えるツイートがかわいい系と判定されました. 一方,不正解の例では,問題提起系と思われるツイートが,感嘆系と判定されてしまいました. それぞれの反応はこのようなものがありました。 こちらはやはり「可愛い」という反応が多かったのですが、不正解の例では そもそも「感嘆系」と解釈したクラスタでは、「いい」というとても抽象的な単語を主としたクラスタであって、 この問題提起系と思われるツイートはこうすれば「いい」、というような言葉が多くて、それが間違いの原因でした。
#24
考察です。 特徴量において、N-gramやdoc2vecなど特徴量を生成する他の手法や、単語以外の特徴を用いて検討する必要があると考えられます。 〜ためです。
#25
そのほかに考えられるアプローチとして、〜ということも考えられます。 〜という考え方で、〜だとみなせると考えられます。
#26
そのため、試しにこのように小規模で2-gramによる類似度を計算して見ました。 あるユーザAの反応ツイート15件を取得し、2-gramで特徴量を取りました。 そして最遠隣法のデンドログラムでクラスタリングすると、このような結果となりました、 縦は類似度を表しています。 このように微笑んでる顔文字や、笑いを表す「w」の並びなどが同じ反応のツイートは、 それぞれほんわかしたツイートに対してだったり、笑える中でも突っ込みたくなるようなツイートで、同じような印象を持つようなものでした。
#27
その他の課題では、以下のようなものが考えられます。
#28
まとめです 本研究は〜を目的としたものであり、 〜であり、印象推定するものとしては可能性があることがわかりました。 今後の課題としては、〜が考えられるため、改善を重ねていきたいと考えています。
#29
言い方や語尾 ~と考えられる 可能性がある理由を説明 理由・意義を説明 反応があるツイートというのは そもそも反応したくなる何かを人に引き起こすツイートである そのため息抜きに有効である
#31
可能性 印象(形容詞)で検索すると、それに一致するクラスタやツイートを表示するようなシステム 自分でパラメータを変えてカテゴリの幅を変えられる
#33
評価はこのようになりました. この条件のパラメータで生成されたクラスタ数は8個で, 〜となりました. フィルタリングの正解率は〜でした. ─────────────── うまくいった例 何が原因?
#35
クラスタリング結果の一部です クラスタリングされたいい例では,あるクラスタに食べ物の写真のツイートが多く含まれました.これに名前をつけるとすれば,〜と言えます.
#36
過学習を緩和するため,〜します. 一万件ほどのツイートをAとして〜,←いる?
#37
クラスタリング方法では、複数ラベルをとるべきであったと考えられます
#38
正誤が半々程度で,評価はあまり良いとは言えないものであるが,印象を推定する方法としては可能性があることを示した ─────────────── 1.グループ分けの対象 2.分類の形式 階層的方法、非階層的方法、ハードクラスタリング、ソフトクラスタリング 3.分類に用いる対象間の類似度 ユークリッド距離、マハラノビス距離、コサイン類似度… 4.クラスター間の距離の測定方法 ウォード法、群平均法、最短距離法、最長距離法… 「1.グループ分けの対象」は目的が決まれば自動的に決まる。 「2.分類の形式」はビッグデータにおいては非階層的方法を用いることが多いので迷うことはほとんどない。 「4.クラスター合併方法」も非階層的方法では選択する必要はなく、 最も難しいのが 「3.分類に用いる対象間の距離」の選択だ。クラスター分析は「似たもの集めの手法」だと述べたが、「似ている」または「似ていない」をどう定義するかが、ビッグデータにおけるクラスター分析では、最も大きな問題にも関わらず遅れている分野といっても過言ではない。 アンケートデータなどの密なデータと異なり、購買データは非常にスパース(疎)である。このようなデータを扱う場合、そもそも平均や分散に意味を持たなかったり、類似度を表す距離を一般的なユークリッド距離を用いたのではうまくいかなかったりという問題がある。 クラスター分析は手法や指定するパラメータの種類が多く、「これが最適」という選択方法や「これが最高」というクラスターの定義もない。例えば、最適なクラスター数の正解はなく、初期値をどう設定するかによって結果が異なるというやっかいな問題もあり、とても難しい分析手法の1つに数えられる。
Download





















![[WWW Conference 2011]Information Credibility on Twitter](https://cdn.slidesharecdn.com/ss_thumbnails/2011-www-informationcredibilityontwitter-110511095843-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








