Download to read offline
































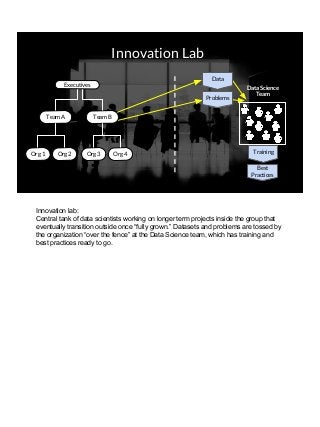
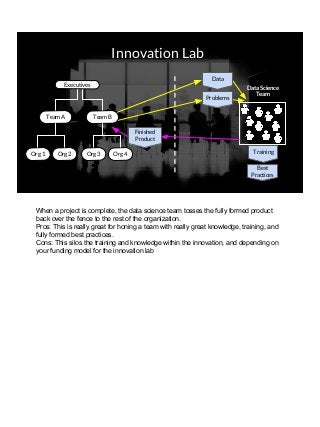
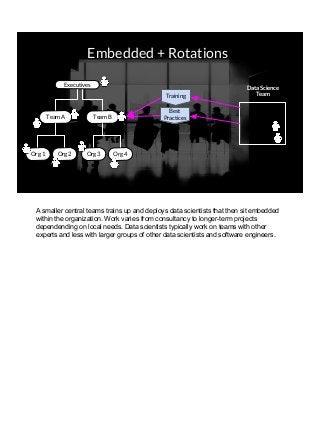
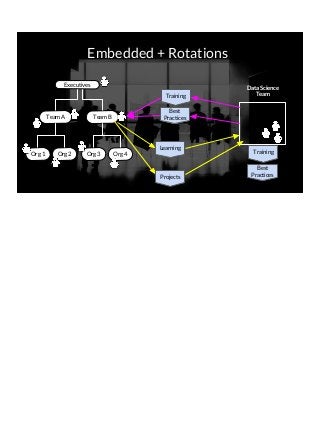
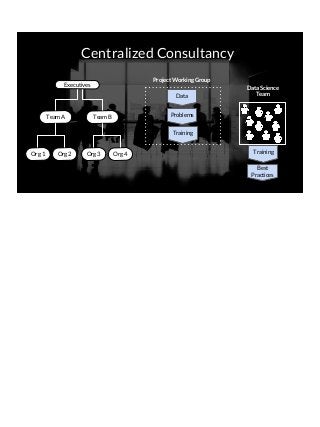
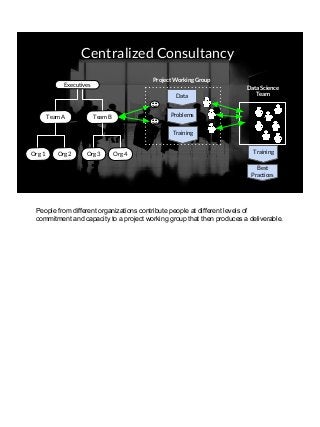
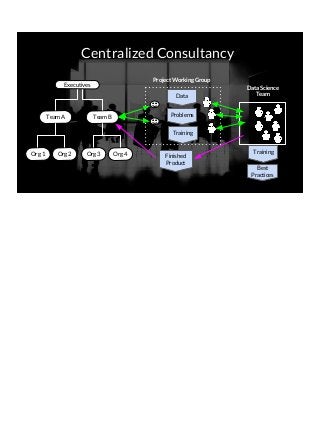





THIS VERSION INCLUDES SPEAKER NOTES IN SLIDES: It was delivered at the 2017 Rice Data Science Conference. As opposed to the typical data science talk on math, models, or frameworks, this talk discusses the need to successfully manage people relationships when doing data science consulting and prototyping in a large organization. Common traps to avoid, key questions to answer early, how organizational procurement patterns influences tool selection and the importance of having a good local partner close to the data are all discussed. The in-person presenter of this talk at Rice Data Science Day was Yulan lin - https://www.linkedin.com/in/yulanlin/ Justin's slides were recorded in advance. The version without speaker notes is here: https://www.slideshare.net/JustinGosses/practical-considerations-of-data-science-consulting-in-large-organizations-oct-12-2017















































