Download to read offline



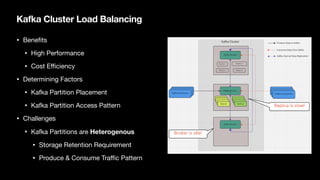

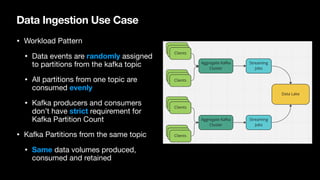
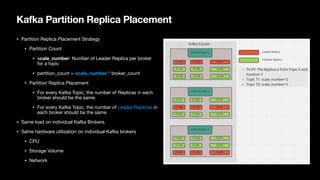








The document discusses strategies for balancing Kafka clusters while minimizing data movement, emphasizing the importance of partition placement and load balancing for performance and cost efficiency. It outlines challenges such as heterogeneous partitions and storage retention requirements, and suggests implementing a continuous rebalancing mechanism based on load metrics. Additionally, it highlights the potential for improving load balance through a refined partition placement strategy and the plan to contribute to the Apache Kafka project.


































































