
Download as PDF, PPTX





![Problem Summary
• Current Plagiarism Detection Systems:
– Perform sophisticated text analysis
– Find copy & paste plagiarism typical for students
– Miss disguised plagiarism frequent among researchers
• Our prior research:
– Analyzing citation patterns [1]
– Analyzing image similarity [2]
Doc C
Doc E
Doc D
Section 1
This is an exampl etext withreferences to different documents for illustratingtheusageof
citation analysis for plagiari sm detection. This is an example text with references to
different documents for illustrati ng the usage of citationanalysis forplagiarism detection.
This is ain-text citation [1]. This is anexample text with references todifferent documents
for illustrating the usage of citation analysis for plagiari sm detection.This is an example
text withreferenc es to differentdocuments fori llustratingthe usage ofci tation analy sis
for plagiarism detection.
Section 2
Another in-text citation [2]. tThi s is an exampletext with references to different
documents for illustrati ng the usage of citationanalysis forplagiarism detection.Thi s is an
ex ampletext with references to different documents for illustrati ng the usageof citation
anal ysis for plagiarism detection.This is a repeated in-text citation [1].
This is an exampl etext withreferences to different documents for illustratingtheusageof
citation analysis for plagiari sm detection. This is an example text with references to
different documents for illustrati ng the usage of citationanalysis forplagiarism detection.
Setion 3
A third in-text citation [3]. This is anexample text with references todifferent documents
for illustrating the usage of citation analysis for plagiari sm detection.This is an example
text withreferenc es to differentdocuments fori llustratingthe usage ofci tation analysis
for plagiarism detection.afinal i n-text-citation[2].
References
[1]
[2]
[3]
Document B
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection. This is ain-text citation [1]. This is an
ex ampletext with references to different documents for illustrati ng the usageof citation
anal ysis for plagiarism detection.Another exampl efor ani n-text citation [2].
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection.
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection. This is anexample text with references to
different documents for illustrati ng the usage of citationanalysis forplagiarism
detection. This is an example text withreferences to differentdocuments fori llustrating
the usage ofcitation analysi s for pl agiarism detection.
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection. This is anexample text with references to
different documents for illustrati ng the usage of citationanalysis forplagiarism
detection. Here s a third in-text citation [3]. This is anexample text with references to
different documents for illustrati ng the usage of citationanalysis forplagiarism
detection.
This is an exampl etext withreferences to different documents for illustratingtheusage
ofci tation analysis for plagi arism detection.
Document A
References
[1]
[2]
[3]
EDC DECDC
Citation Pattern Citation Pattern
Doc A Doc B
Ins.EIns.DC
DECDC
Pattern Comparison
Doc A
Doc B
[1] B. Gipp and N. Meuschke, “Citation Pattern Matching Algorithms for Citation-based Plagiarism Detection: Greedy Citation
Tiling, Citation Chunking and Longest Common Citation Sequence,” in Proc. ACM Symp. on Document Engin. (DocEng), 2011.
Analysis of in-text citation patterns.
Analysis of image similarity using Perceptual Hashing
[2] N. Meuschke, C. Gondek, D. Seebacher, C. Breitinger, D. Keim, and B. Gipp, “An Adaptive Image-based Plagiarism
Detection Approach,” in Proc. Joint Conf. on Digital Libraries (JCDL), 2018. 5](https://image.slidesharecdn.com/jcdlhybridpdslideshare-190604191246/85/Improving-Academic-Plagiarism-Detection-for-STEM-Documents-by-Analyzing-Mathematical-Content-and-Citations-5-320.jpg)


![Approach
• Combined analysis of math-based and citation-based similarity
• Pilot study [3]:
[3] N. Meuschke, M. Schubotz, F. Hamborg, T. Skopal, and B. Gipp, “Analyzing Mathematical Content to Detect
Academic Plagiarism,” in Proc. Int. Conf. on Information and Knowledge Management (CIKM), 2017. 8
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
r x Δ
Identifiers (ci)
Doc1
r
xx −
− )²( 2
3
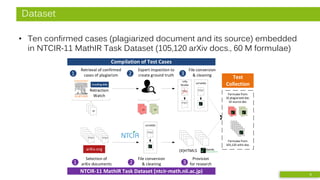
Formulae from:
10 plagiarized doc.
10 source doc.
105,120 arXiv doc.
Mathosphere Framework
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
r x 2 3 - Δ
Feature Combination
.13
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
2 3 Δ
Numbers (cn)
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
- Δ
Operators (co)
.50
All-to-all comparison
of documents and
document partitions
Computation:
relative distance of
frequency histograms of
feature occurrences
Doc2
r
xx )3²2( −](https://image.slidesharecdn.com/jcdlhybridpdslideshare-190604191246/85/Improving-Academic-Plagiarism-Detection-for-STEM-Documents-by-Analyzing-Mathematical-Content-and-Citations-8-320.jpg)

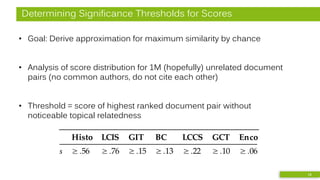
![Approach
• Combined analysis of math-based and citation-based similarity
• Pilot study [3]:
• MRR = 0.86
(ident., doc.)
• MRR = 0.70
(comb., part.)
[3] N. Meuschke, M. Schubotz, F. Hamborg, T. Skopal, and B. Gipp, “Analyzing Mathematical Content to Detect
Academic Plagiarism,” in Proc. Int. Conf. on Information and Knowledge Management (CIKM), 2017. 11
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
r x Δ
Identifiers (ci)
Doc1
r
xx −
− )²( 2
3
Formulae from:
10 plagiarized doc.
10 source doc.
105,120 arXiv doc.
Mathosphere Framework
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
r x 2 3 - Δ
Feature Combination
.13
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
2 3 Δ
Numbers (cn)
0
1
2
Doc1
Doc2
Distance
0
1
2
Doc1
Doc2
Distance
- Δ
Operators (co)
.50
All-to-all comparison
of documents and
document partitions
Computation:
relative distance of
frequency histograms of
feature occurrences
Doc2
r
xx )3²2( −](https://image.slidesharecdn.com/jcdlhybridpdslideshare-190604191246/85/Improving-Academic-Plagiarism-Detection-for-STEM-Documents-by-Analyzing-Mathematical-Content-and-Citations-11-320.jpg)



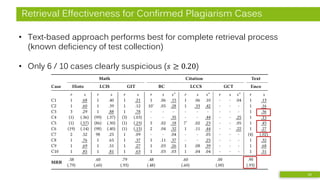
![Detailed Analysis - Citation & Text Features
• Bibliographic Coupling (BC)
– Order-agnostic bag of references
• Greedy Citation Tiles (GCT)
– Contiguous in-text citations
in same order
– minimum length of 2
• Longest Common Citation Sequence (LCCS)
– Citations in same order
but not necessarily contiguous
• Text-based: Encoplot
– Efficiency-optimized character 16-gram comparison
15
xxx6x54xx321
6xxxx321xx54
I
III
II III
III
Tiles: I (1,5,3) II (6,1,2) III (9,12,1)
Doc A:
Doc B:
6543xx2xx1xx
x34xxx256x1x
LCCS: 1,2,3
Doc A:
Doc B:
𝑠BC = 3Doc A
citing
Doc B
citing
[1]
[2]
[3]
cites cites](https://image.slidesharecdn.com/jcdlhybridpdslideshare-190604191246/85/Improving-Academic-Plagiarism-Detection-for-STEM-Documents-by-Analyzing-Mathematical-Content-and-Citations-15-320.jpg)






The document discusses enhancing plagiarism detection in STEM fields, particularly math-heavy disciplines, by analyzing mathematical content and citations alongside traditional text-based methods. It emphasizes the limitations of existing systems in effectively identifying disguised plagiarism and presents a methodology that combines math-based and citation-based analyses, yielding promising results in uncovering previously undiscovered cases. Ultimately, the study advocates for improved extraction of citation data and the development of more sophisticated math-based methods to optimize plagiarism detection.







![[IJET-V1I6P17] Authors : Mrs.R.Kalpana, Mrs.P.Padmapriya](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i6p17-160110012712-thumbnail.jpg?width=640&height=640&fit=bounds)


































































