Google Cloud ベストプラクティスGoogle BigQuery
Confidential & Proprietary
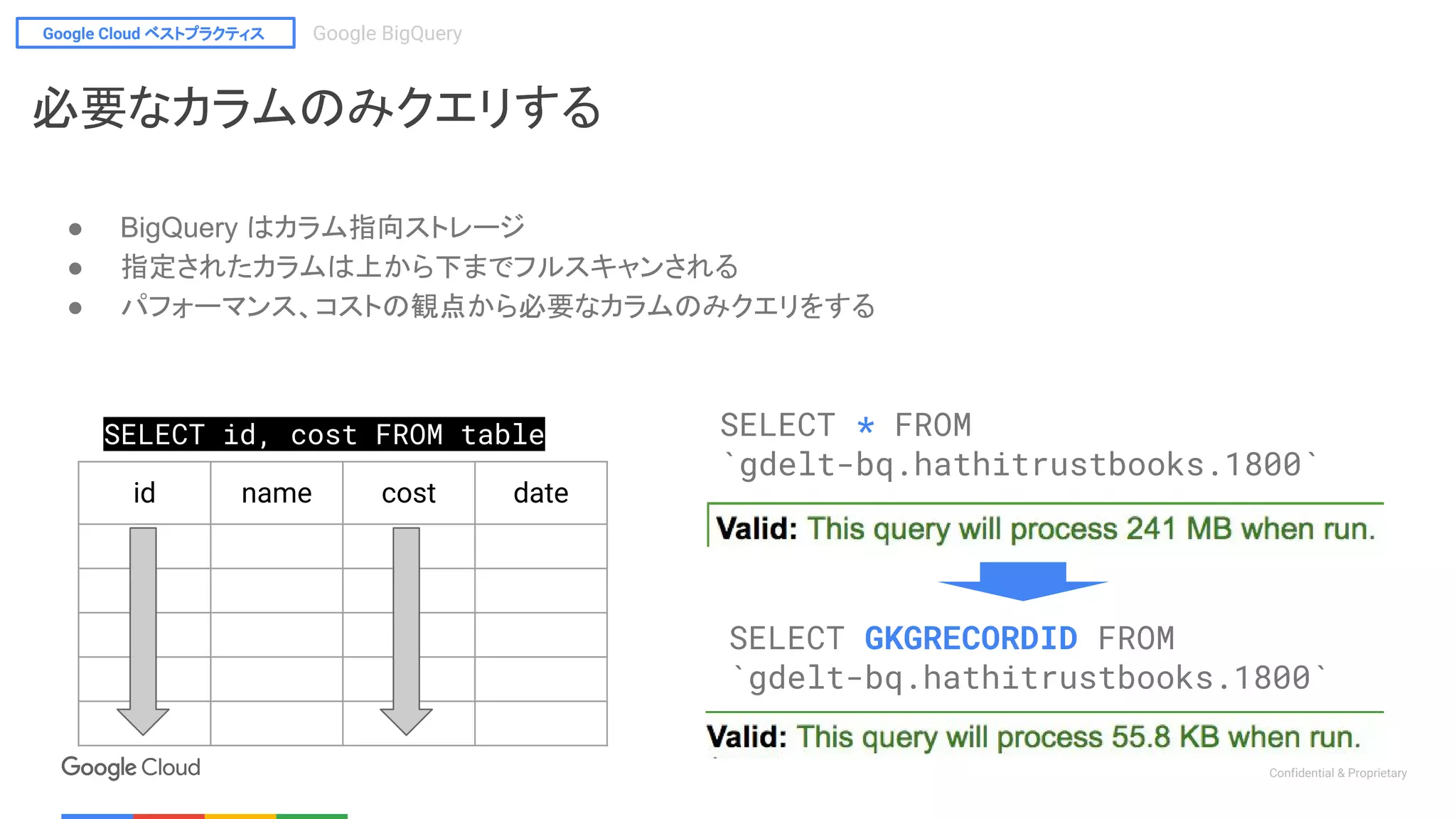
id name cost date
SELECT id, cost FROM table
SELECT GKGRECORDID FROM
`gdelt-bq.hathitrustbooks.1800`
SELECT * FROM
`gdelt-bq.hathitrustbooks.1800`
必要なカラムのみクエリする
● BigQuery はカラム指向ストレージ
● 指定されたカラムは上から下までフルスキャンされる
● パフォーマンス、コストの観点から必要なカラムのみクエリをする
6.
Google Cloud ベストプラクティスGoogle BigQuery
Confidential & Proprietary
※ 分割テーブル
#standardSQL
SELECT
*
FROM
mydataset.partitioned_table
WHERE
_PARTITIONTIME BETWEEN
TIMESTAMP_TRUNC(TIMESTAMP_SUB(CURRENT_TIMES
TAMP(), INTERVAL 7 * 24 HOUR),DAY)
AND
TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(),DAY);
#Caluculate the cost for today
#standardSQL
SELECT service.description, SUM(cost)
FROM
`yutah-playground.billing_dashboard.gcp_billi
ng_export_v1_00AFE2_6C3561_890001`
WHERE
_PARTITIONTIME = TIMESTAMP("2017-10-13")
GROUP BY service.id, service.description
LIMIT
1000
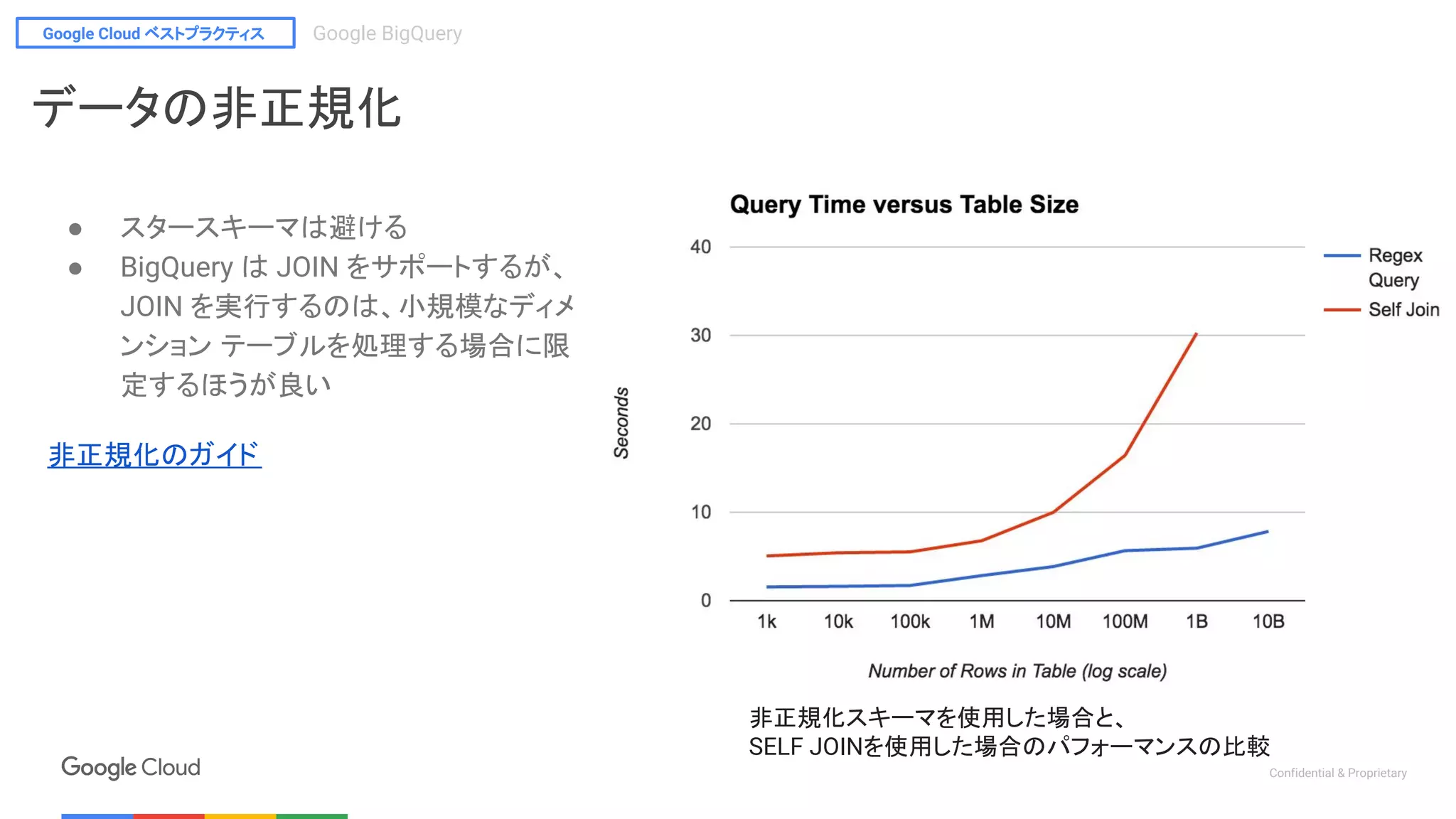
分割テーブル (partitioned table)
● テーブルを パーティション に分割する
● 2017年10月 現在, データが挿入された日付で分割がされる 日付分割 のみ対応
● 最新のデータ(7日間)のみ取得するビューを作るなど、スキャン対象データを絞れる
Google Cloud ベストプラクティスGoogle BigQuery
Confidential & Proprietary
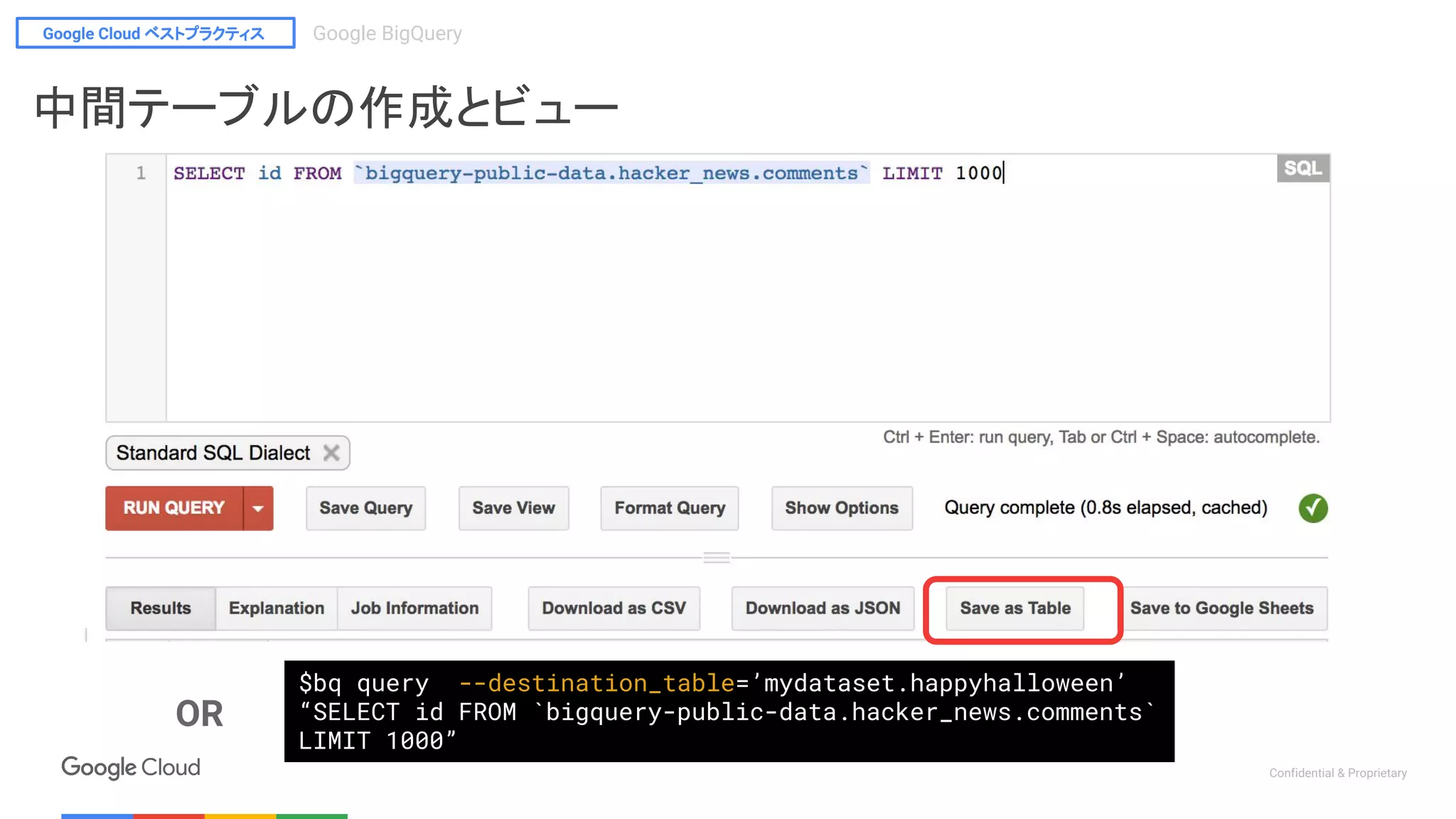
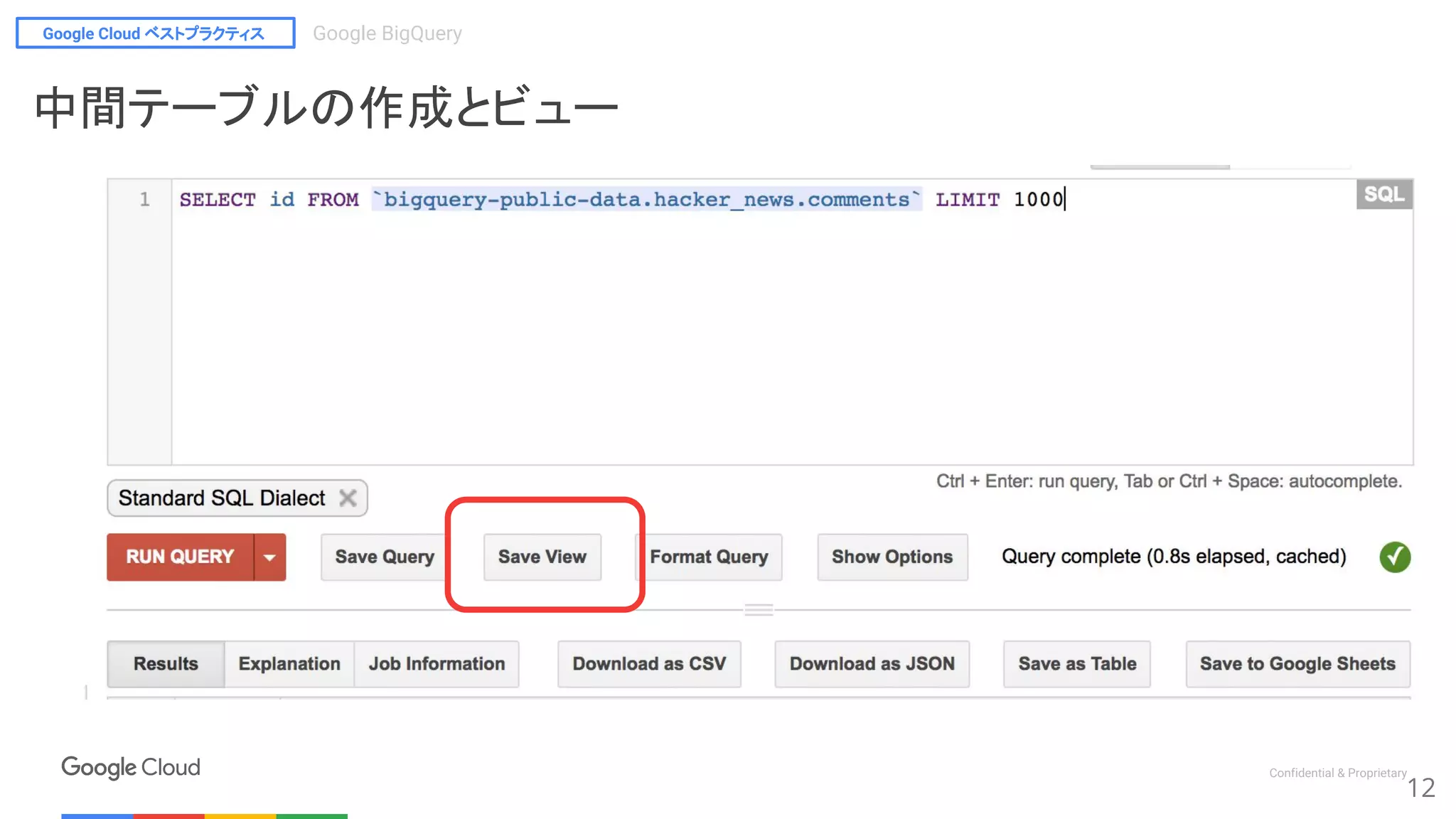
$bq query --destination_table=’mydataset.happyhalloween’
“SELECT id FROM `bigquery-public-data.hacker_news.comments`
LIMIT 1000”
OR
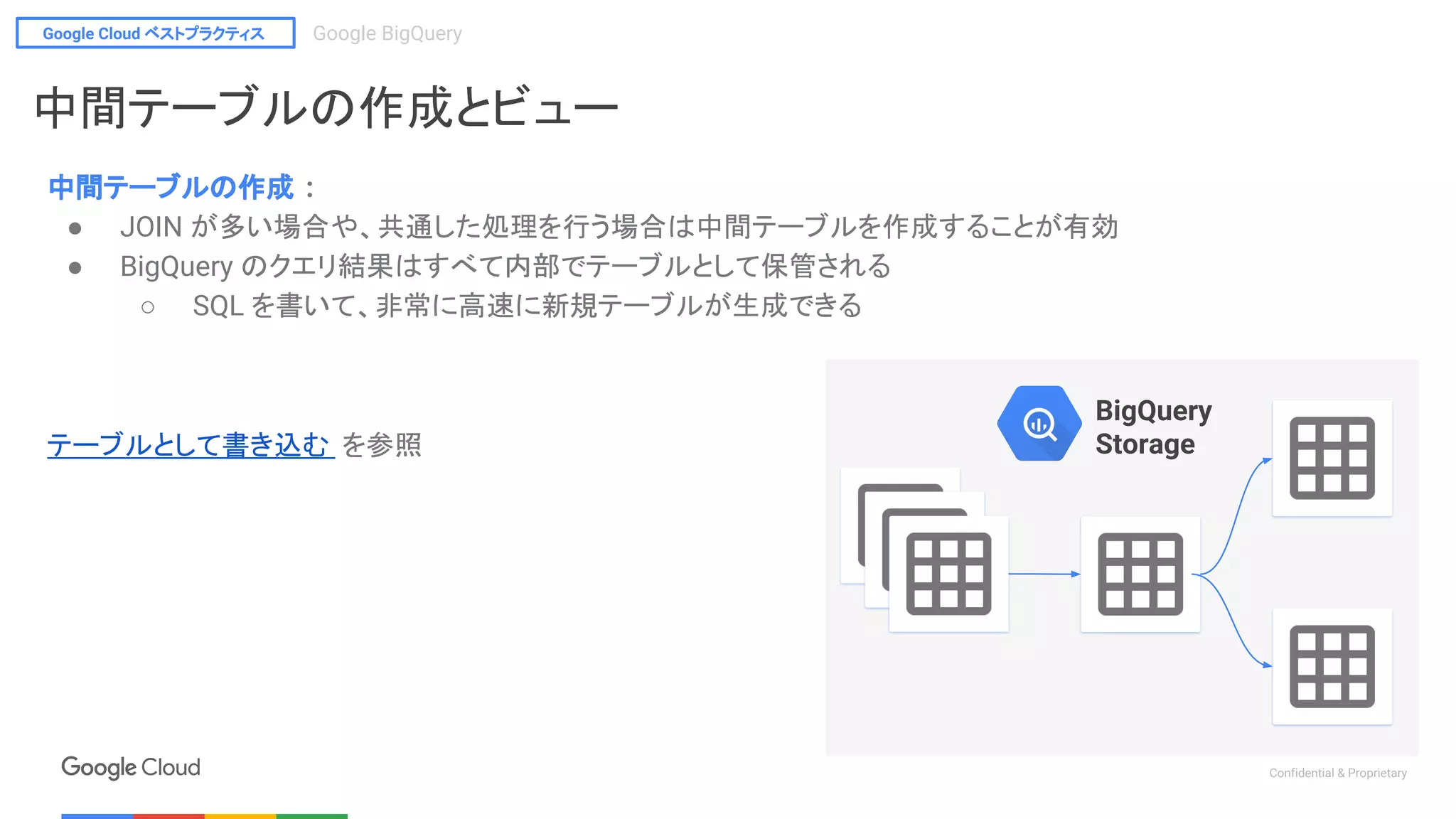
中間テーブルの作成とビュー
11.
Google Cloud ベストプラクティスGoogle BigQuery
Confidential & Proprietary
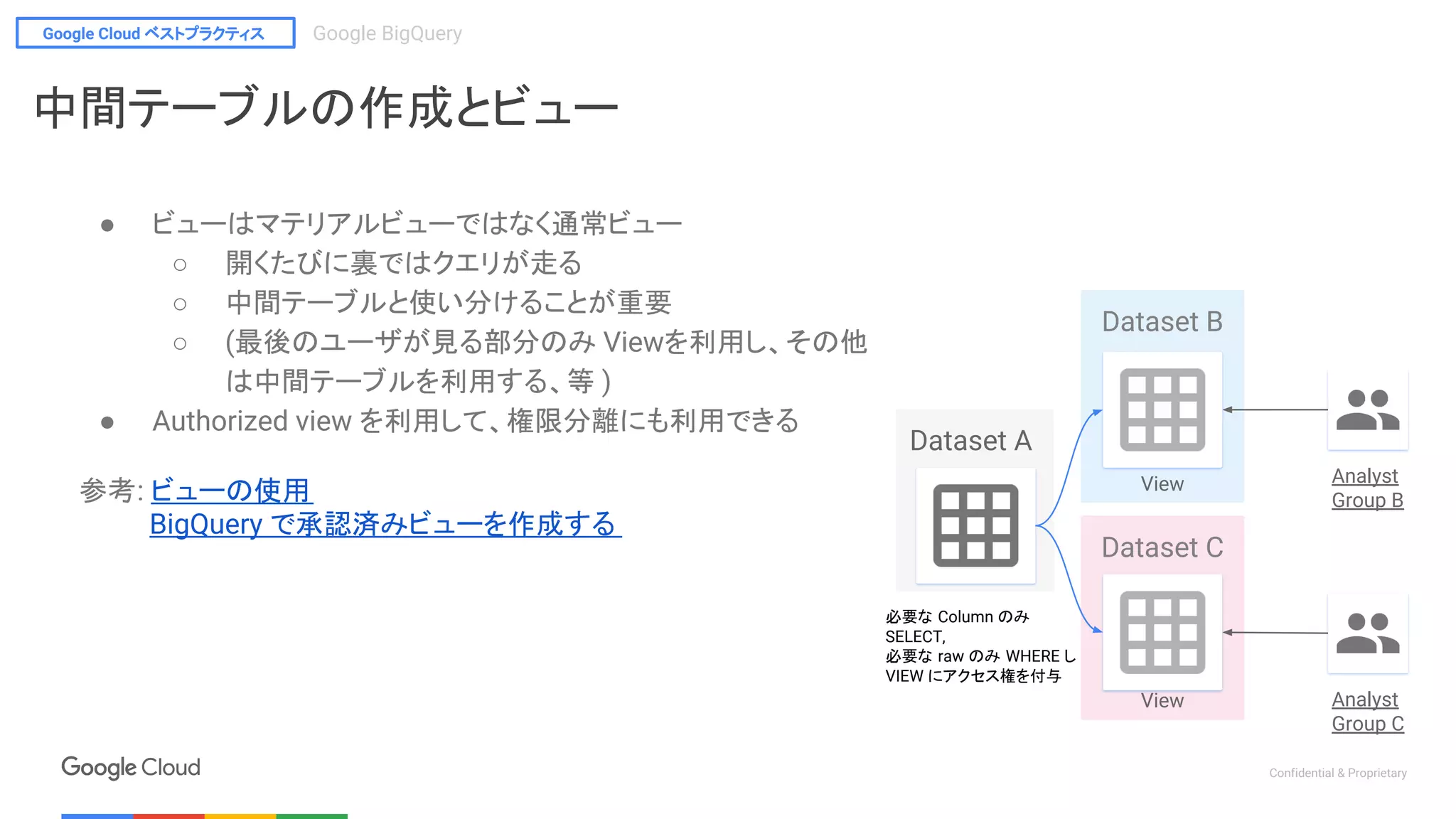
Dataset C
Dataset B
● ビューはマテリアルビューではなく通常ビュー
○ 開くたびに裏ではクエリが走る
○ 中間テーブルと使い分けることが重要
○ (最後のユーザが見る部分のみ Viewを利用し、その他
は中間テーブルを利用する、等 )
● Authorized view を利用して、権限分離にも利用できる
参考: ビューの使用
BigQuery で承認済みビューを作成する
Dataset A
View
View
必要な Column のみ
SELECT,
必要な raw のみ WHERE し
VIEW にアクセス権を付与
Analyst
Group B
Analyst
Group C
中間テーブルの作成とビュー
Google Cloud ベストプラクティスGoogle BigQuery
Confidential & Proprietary
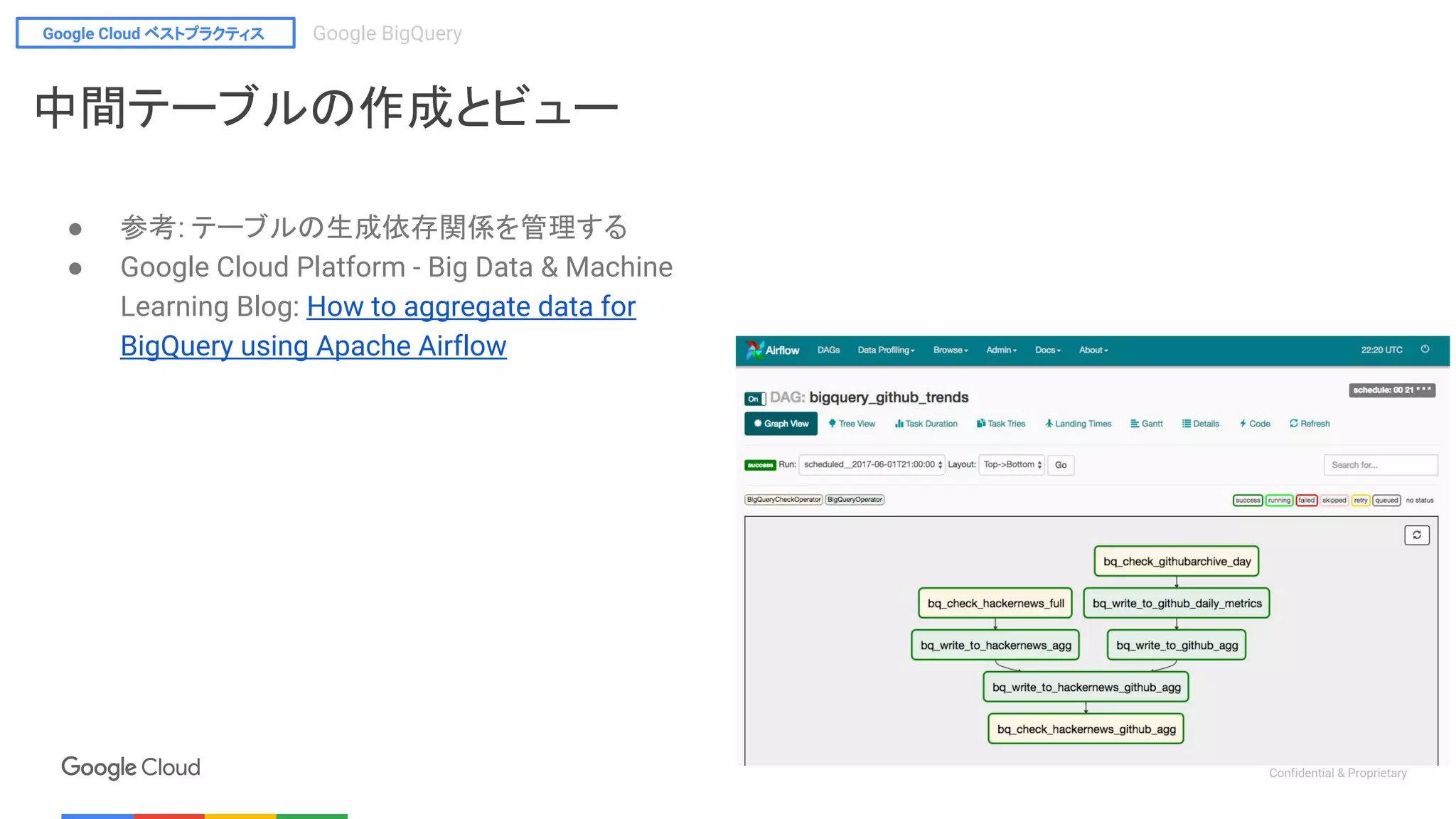
中間テーブルの作成とビュー
● 参考: テーブルの生成依存関係を管理する
● Google Cloud Platform - Big Data & Machine
Learning Blog: How to aggregate data for
BigQuery using Apache Airflow
14.
Google Cloud ベストプラクティスGoogle BigQuery
Confidential & Proprietary
14
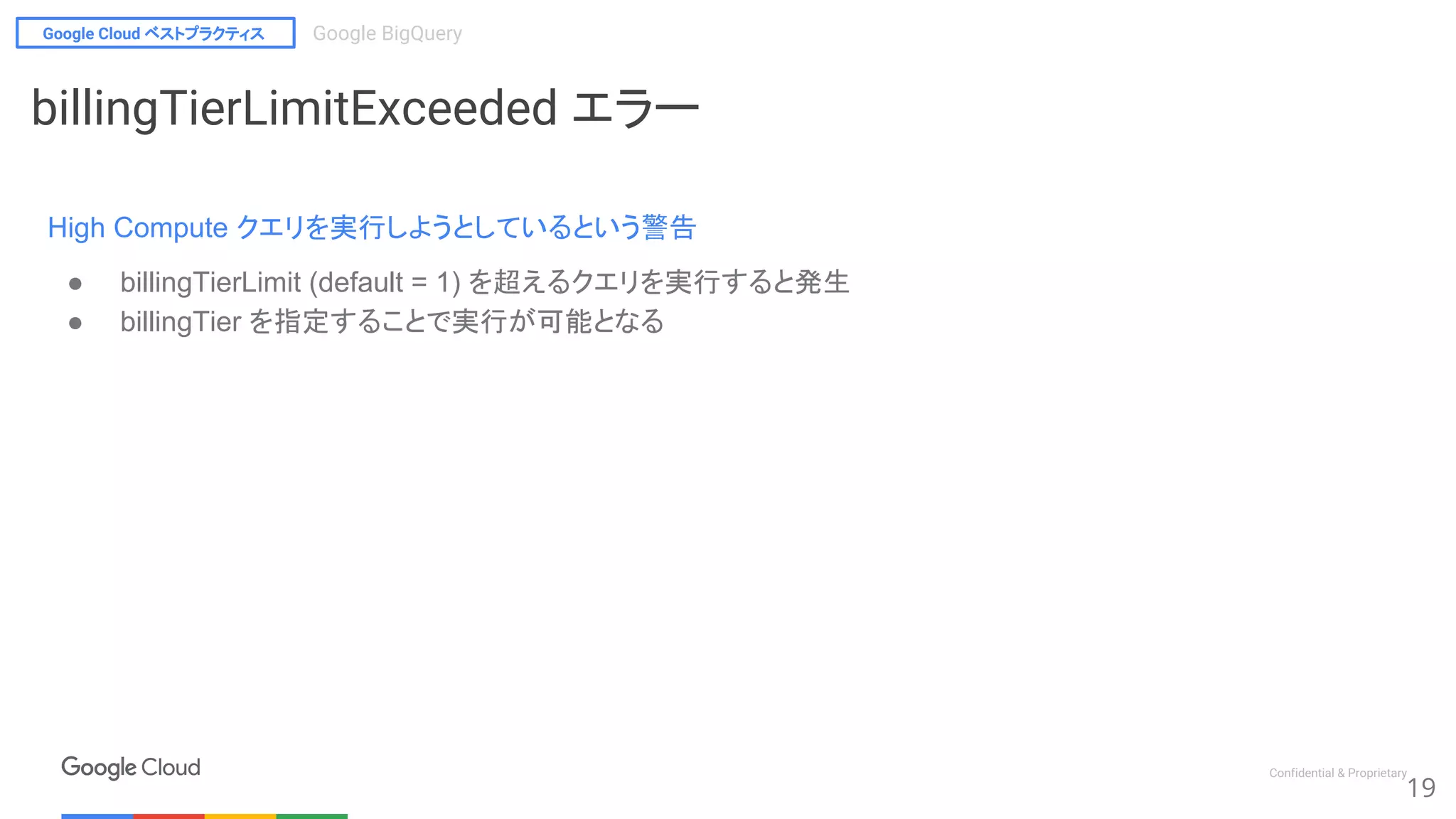
Google BigQuery 注意事項
● responseTooLarge 応答結果が大きすぎる
○ 圧縮後128MBまで -> 別テーブルに出力する
● resourcesExceeded リソースが足りな
○ GROUP EACH BY, EACH JOIN … ON
● quotaExceeded クォータを超過してい
○ クォータに注意
● billingTierLimitExceeded HighCompute クエリを実行しようとしている
○ maximumBillingTier を指定する
Google Cloud ベストプラクティスGoogle BigQuery
Confidential & Proprietary
36
https://cloud.google.com/bigquery/pricing
BigQuery - Storage
[Unit: per GB per month]
GCS
[Unit: per GB per month]
BigQuery: Storage
GCS: Nealine
$0.02 $0.01
BigQuery: Long Term Storage
GCS: Coldline
$0.01 $0.007
bq extract --compression=GZIP [DATASET].[TABLE_NAME]
gs://[BUCKET_NAME]/[FILENAME] ※料金はUSリージョン
利用料金の節約 - ストレージ
古いデータを Google Cloud Storage (GCS) へエクスポート
● GCS へのエクスポート時に gzip 圧縮を指定することも検討
37.
Google BigQuery
Google Cloudベストプラクティス
Thank you
1 : Introduction / BigQuery Organization / Exploring and Interacting with BigQuery
2 : Data ingestion into BigQuery / Writing Queries in BigQuery / Data extraction and exportation from BigQuery
3 : Best Practices and Performance Optimization / Cost Optimization













![Google Cloud ベストプラクティス Google BigQuery
Confidential & Proprietary
24
データ処理容量
[ $5 / TB ]
BillingTier
[ 明示的に指定しないと 1 ]×
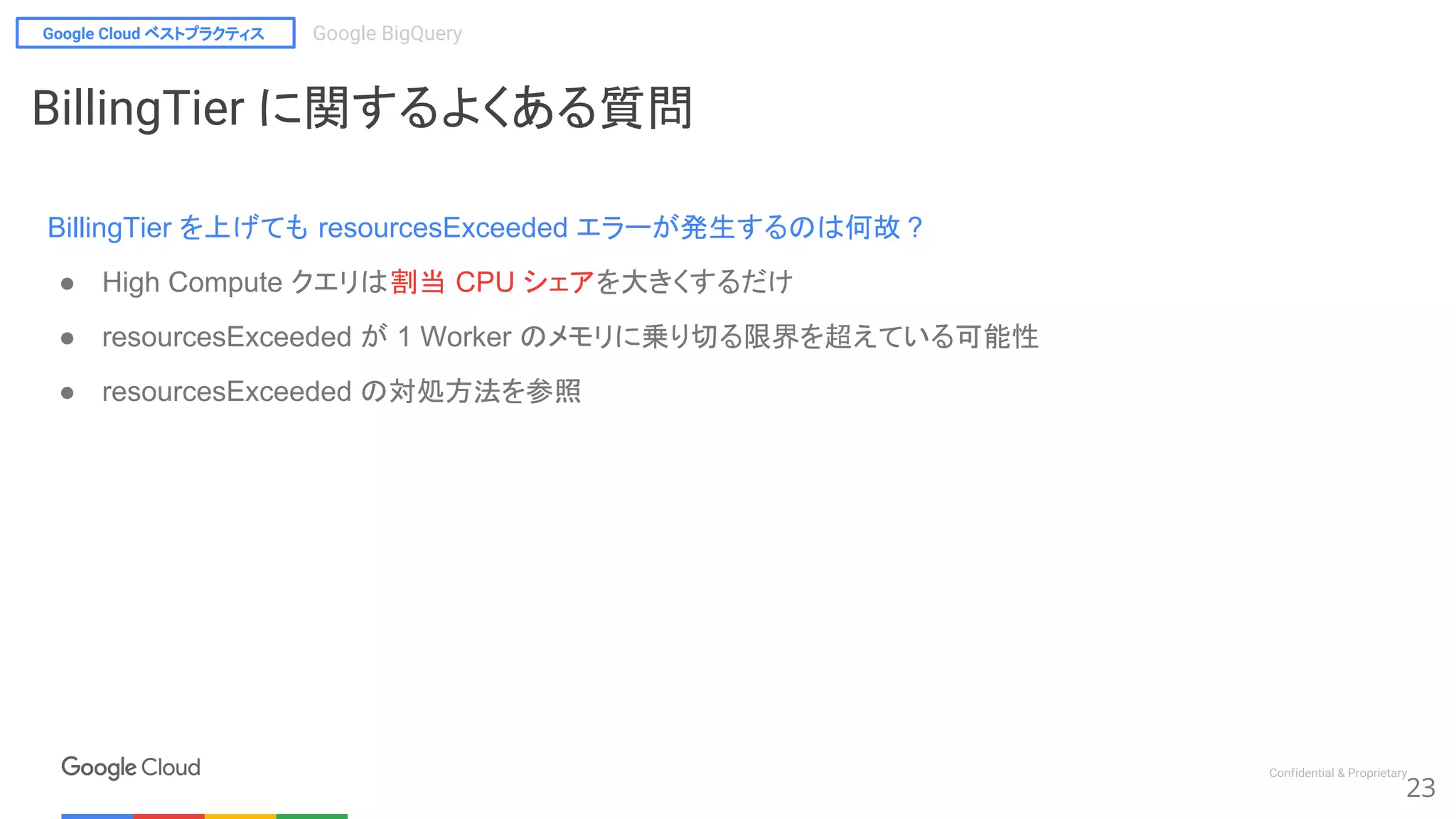
BillingTier に関するよくある質問
2017 年 3 月より BigQuery の料金は何が変わったのか
● 既存クエリ に対する特例措置の終了
● 2016 年 1 月 1 日よりも前に作成されたプロジェクトでは、追加料金なしで High
Compute クエリが使用できたが、 2017 年 1 月 1 日よりこの特例措置がなくなる
○ 参考 : High-Compute クエリ のタイミング
○ 特例措置が適用されている場合、プロジェクトオーナーに通知
● その他、基本料金にかかる変更は無い](https://image.slidesharecdn.com/googlecloudbestpracticegooglebigquery03-171225091627/75/Google-Cloud-Google-BigQuery-03-24-2048.jpg)










![Google Cloud ベストプラクティス Google BigQuery
Confidential & Proprietary
36
https://cloud.google.com/bigquery/pricing
BigQuery - Storage
[Unit: per GB per month]
GCS
[Unit: per GB per month]
BigQuery: Storage
GCS: Nealine
$0.02 $0.01
BigQuery: Long Term Storage
GCS: Coldline
$0.01 $0.007
bq extract --compression=GZIP [DATASET].[TABLE_NAME]
gs://[BUCKET_NAME]/[FILENAME] ※料金はUSリージョン
利用料金の節約 - ストレージ
古いデータを Google Cloud Storage (GCS) へエクスポート
● GCS へのエクスポート時に gzip 圧縮を指定することも検討](https://image.slidesharecdn.com/googlecloudbestpracticegooglebigquery03-171225091627/75/Google-Cloud-Google-BigQuery-03-36-2048.jpg)






![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Cloud OnAir] BigQuery へデータを読み込む 2019年3月14日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0314-190314100128-thumbnail.jpg?width=640&height=640&fit=bounds)







![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)











![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Cloud OnAir] 最新アップデート Google Cloud データ関連ソリューション 2020年5月14日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0514-200514080330-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Cloud OnAir] BigQuery で実現する Smart Analytics Platform 2019年10月24日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1024-191024090721-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Cloud OnAir] BigQuery の一般公開データセットを 利用した実践的データ分析 2019年3月28日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0328-190328095050-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2014] B33: 超高速データベースエンジンでのビッグデータ分析活用事例 by 株式会社日立製作所 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014b33-141127184852-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[External] 2021.12.15 コンテナ移行の前に知っておきたいこと @ gcpug 湘南](https://cdn.slidesharecdn.com/ss_thumbnails/external2021-211216025522-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Cloud OnAir] 事例紹介 : 株式会社マーケティングアプリケーションズ 〜クラウドへのマイグレーションとその後〜 2020年12月17日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ppp-201221033858-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【実演】Google Cloud VMware Engine と VMware ソリューションを組み合わせたハイブリッド環境の...](https://cdn.slidesharecdn.com/ss_thumbnails/pta-201210085248-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Workspace でできる データ分析と業務自動化のご紹介 2020年12月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ol-201203090835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud へのマイグレーション ツールの紹介 2020年11月26日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ii-201126090801-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud における RDBMS の運用パターン 2020年11月19日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/yy-201119084816-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 事例紹介: 株式会社オープンハウス 〜Google サービスを活用したオープンハウスの AI の取り組み〜 2020年11月1...](https://cdn.slidesharecdn.com/ss_thumbnails/h-201112061942-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Anthos 演習】 解説を聞きながら Anthos を体験しよう 2020年11月5日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ab-201105085037-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] 【Google Kubernetes Engine 演習】解説を聞きながら GKE を体験しよう 2020年10月29日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/bb-201029090440-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud の AI / IoT 最新事例紹介 2020年10月22日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/aa-201022092013-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud Next '20: OnAir 特別編 〜世界で人気のあったセッション特集〜 2020年9月24日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ooo-200924094839-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Talks by DevRel Vol.5 アプリケーションのモダナイゼーション 2020年9月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ffffffffffffffff-200903090943-thumbnail.jpg?width=640&height=640&fit=bounds)







