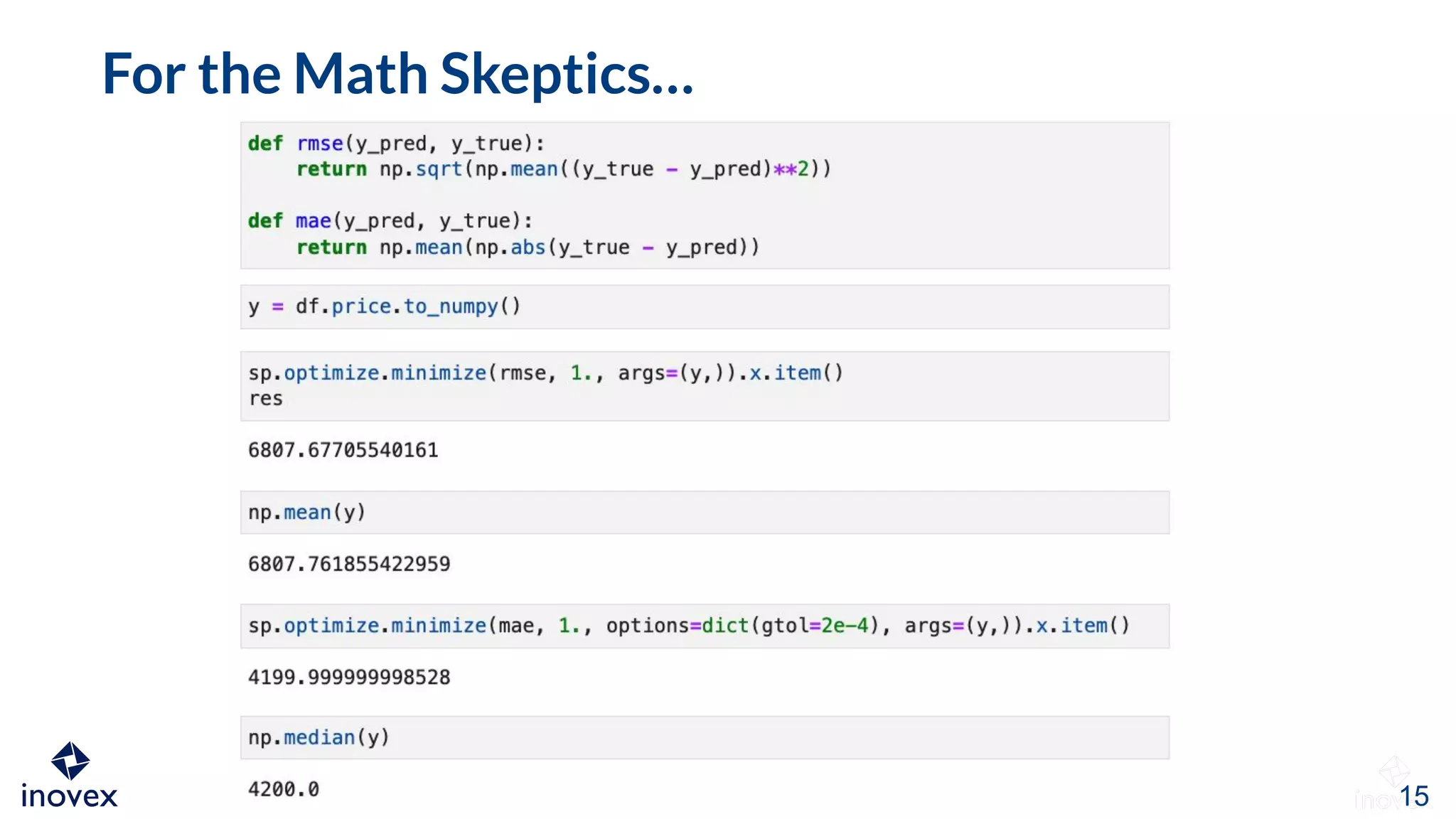
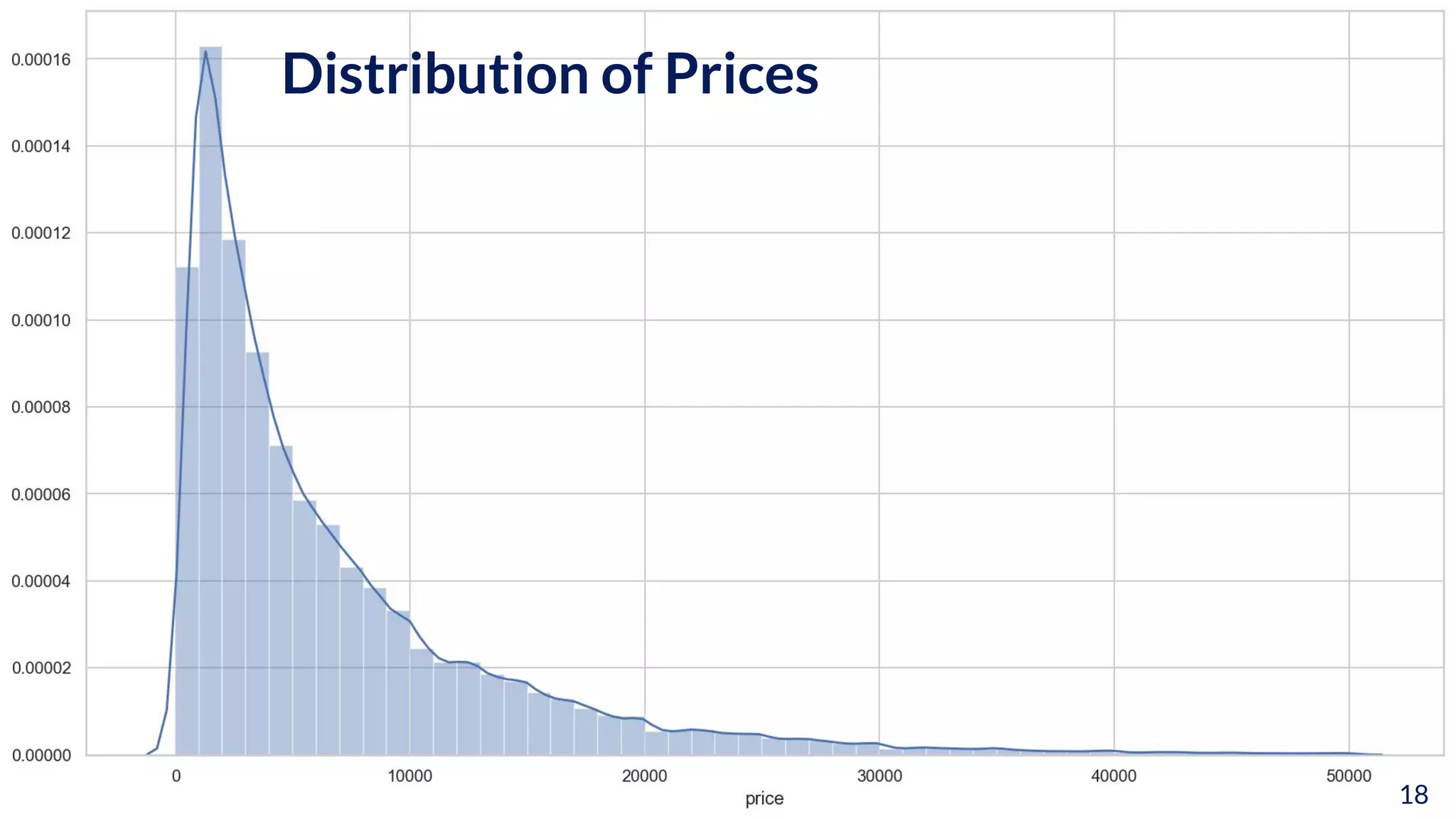
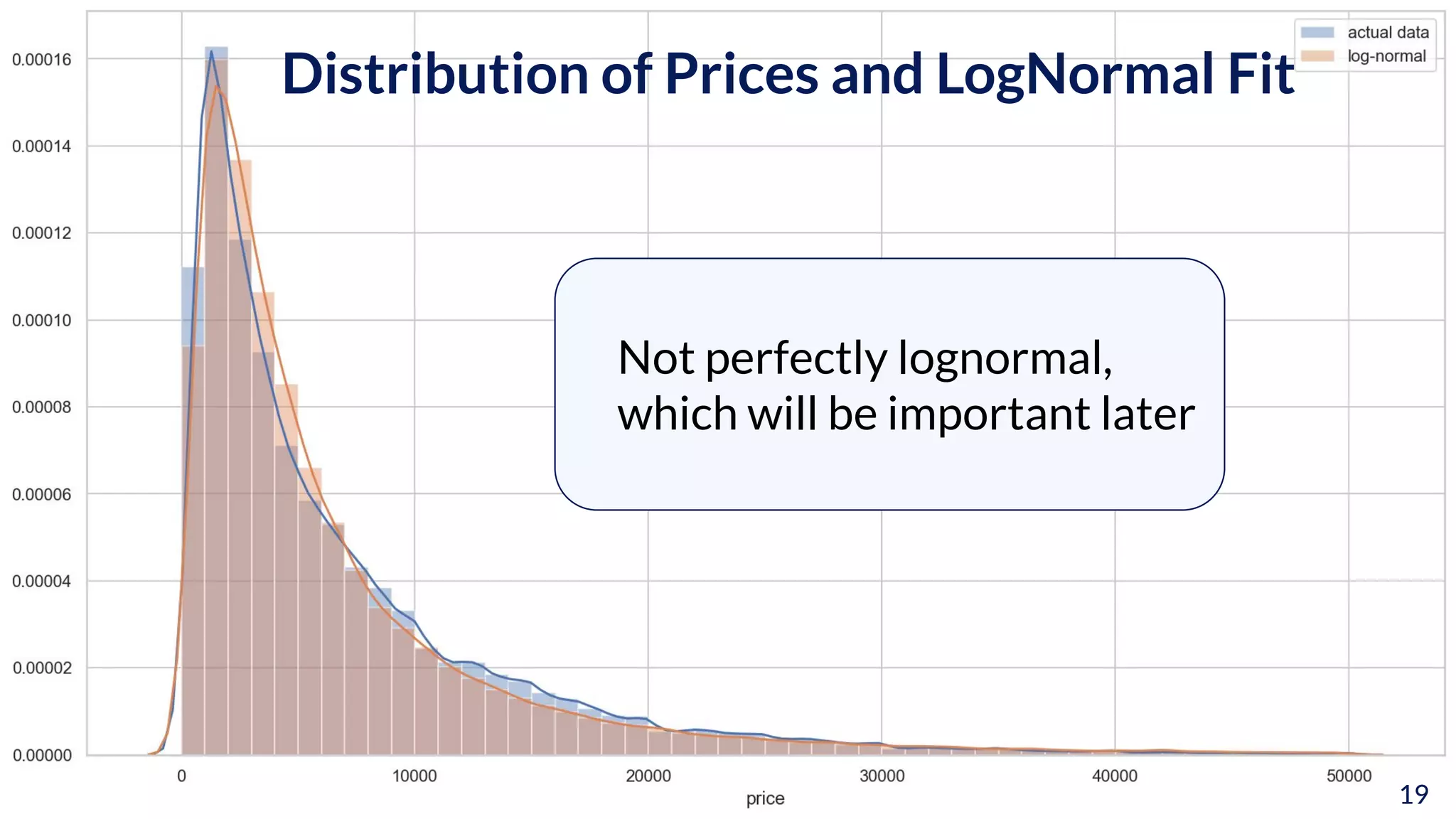
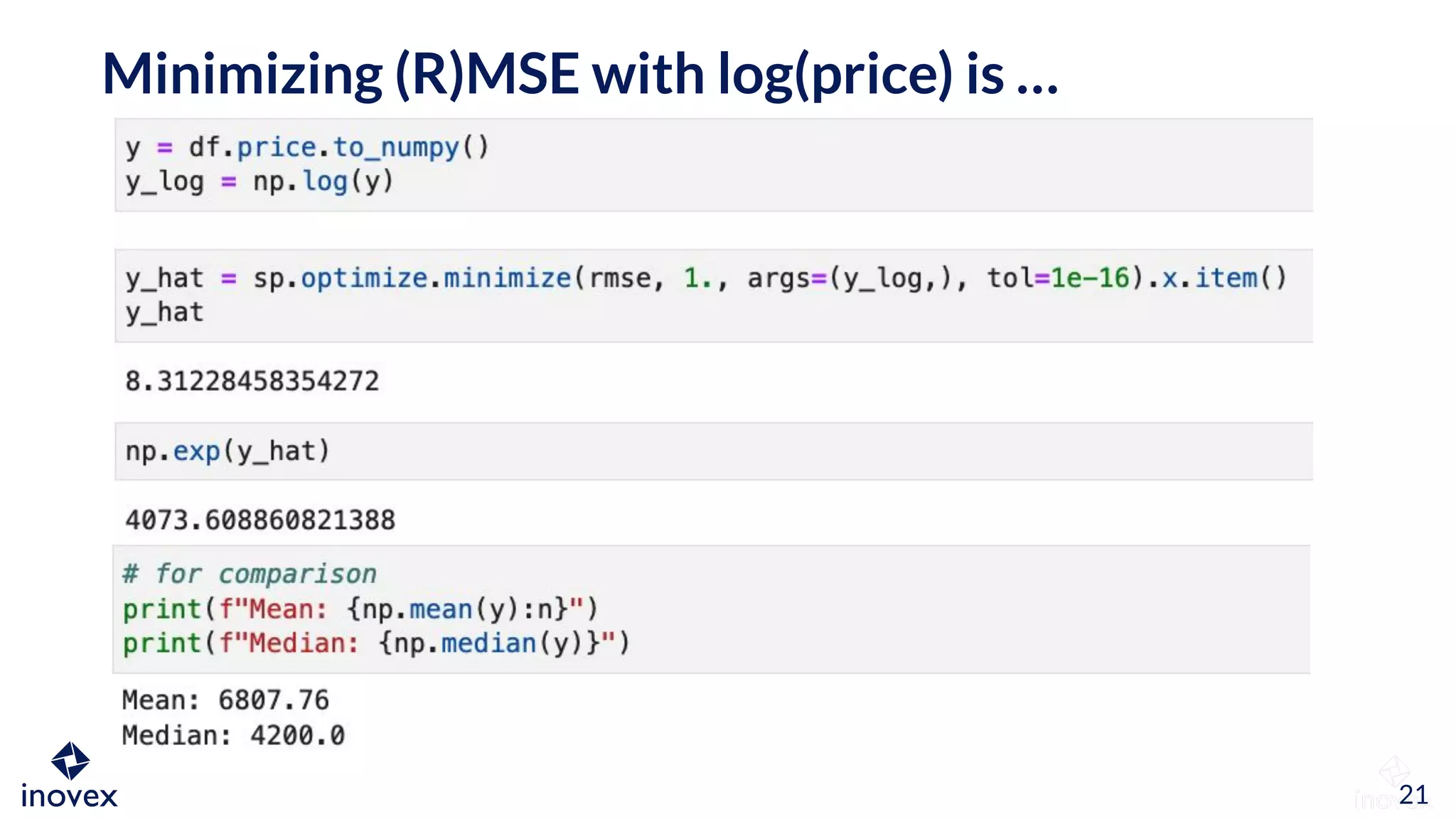
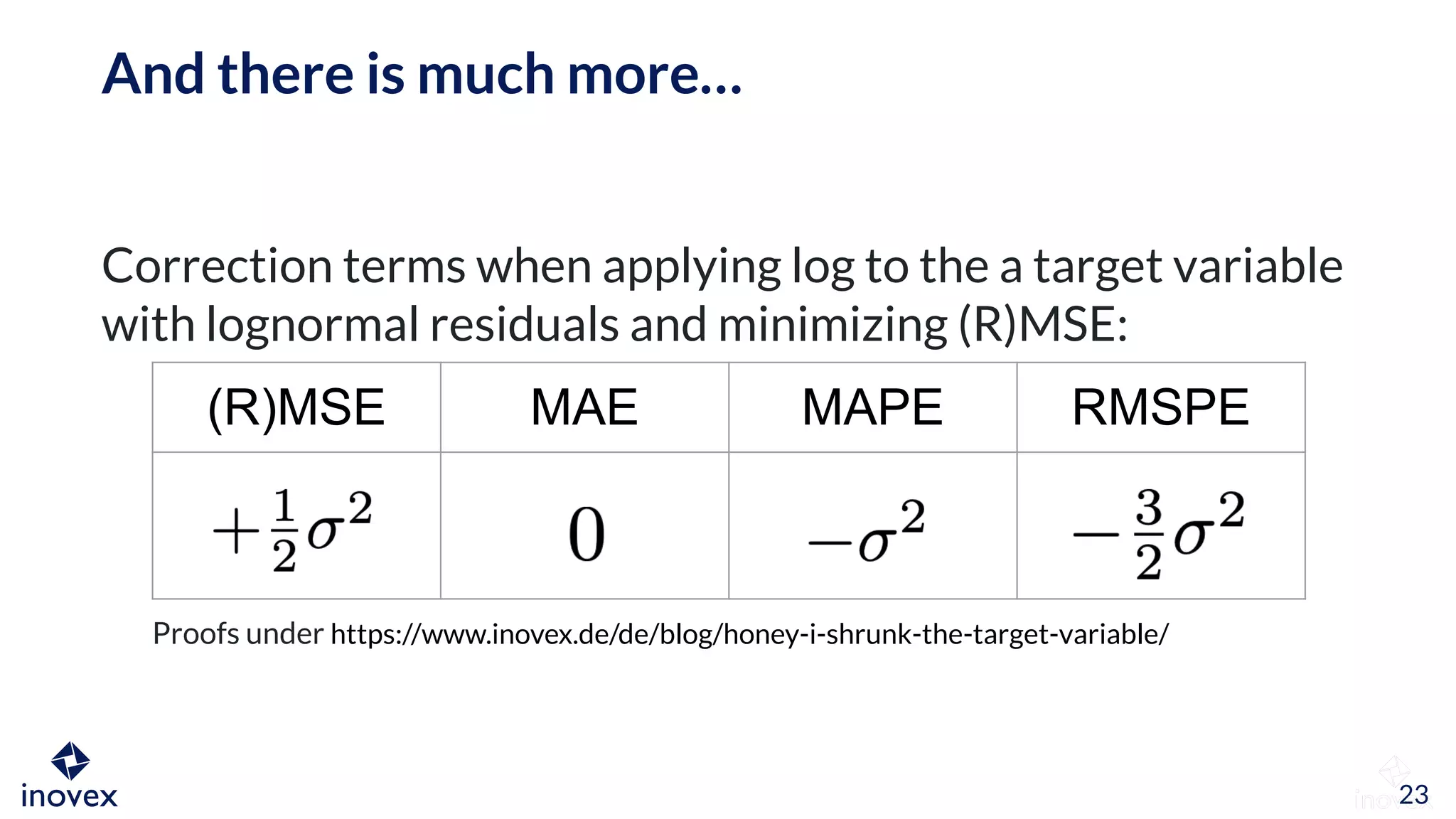
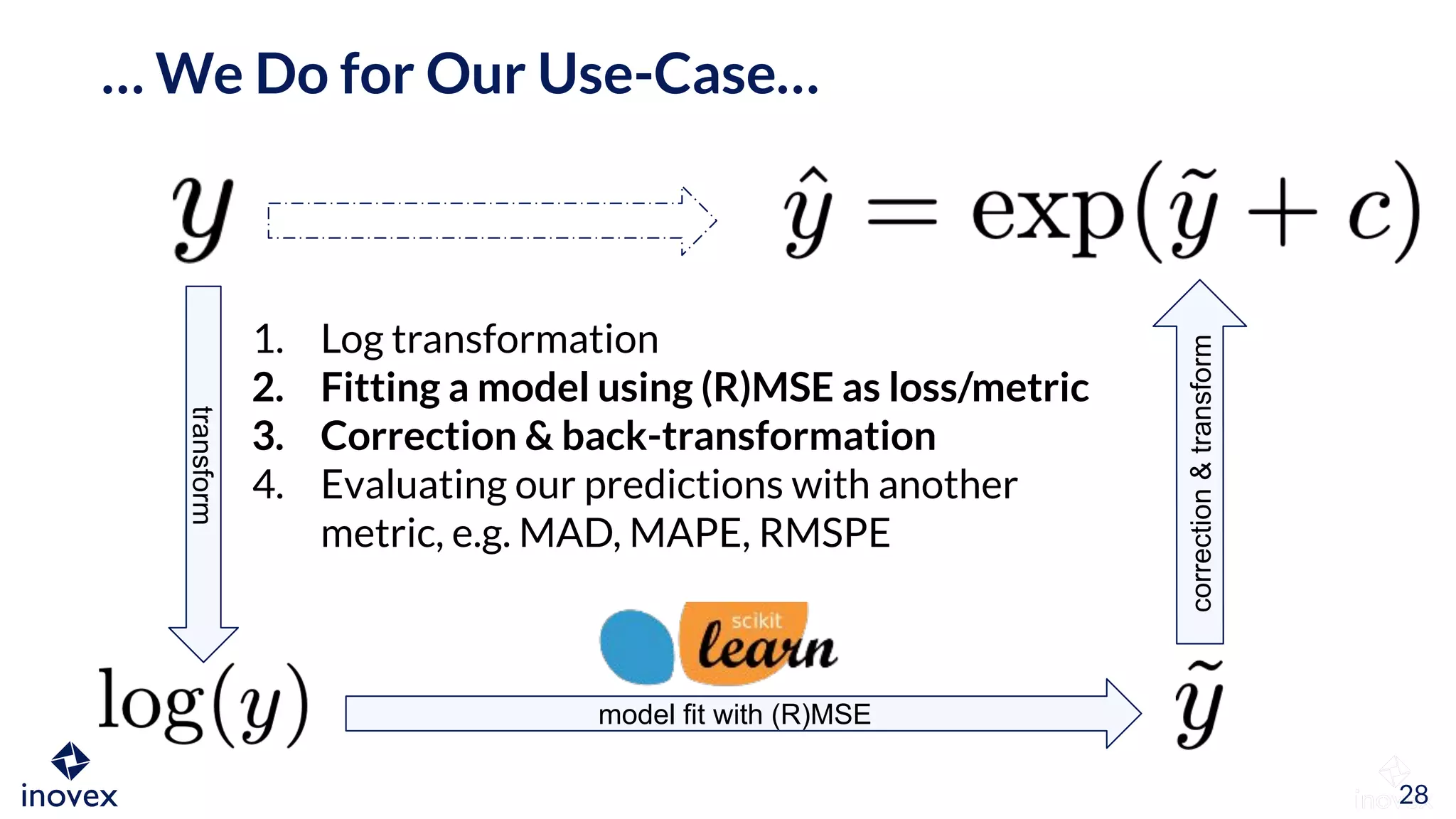
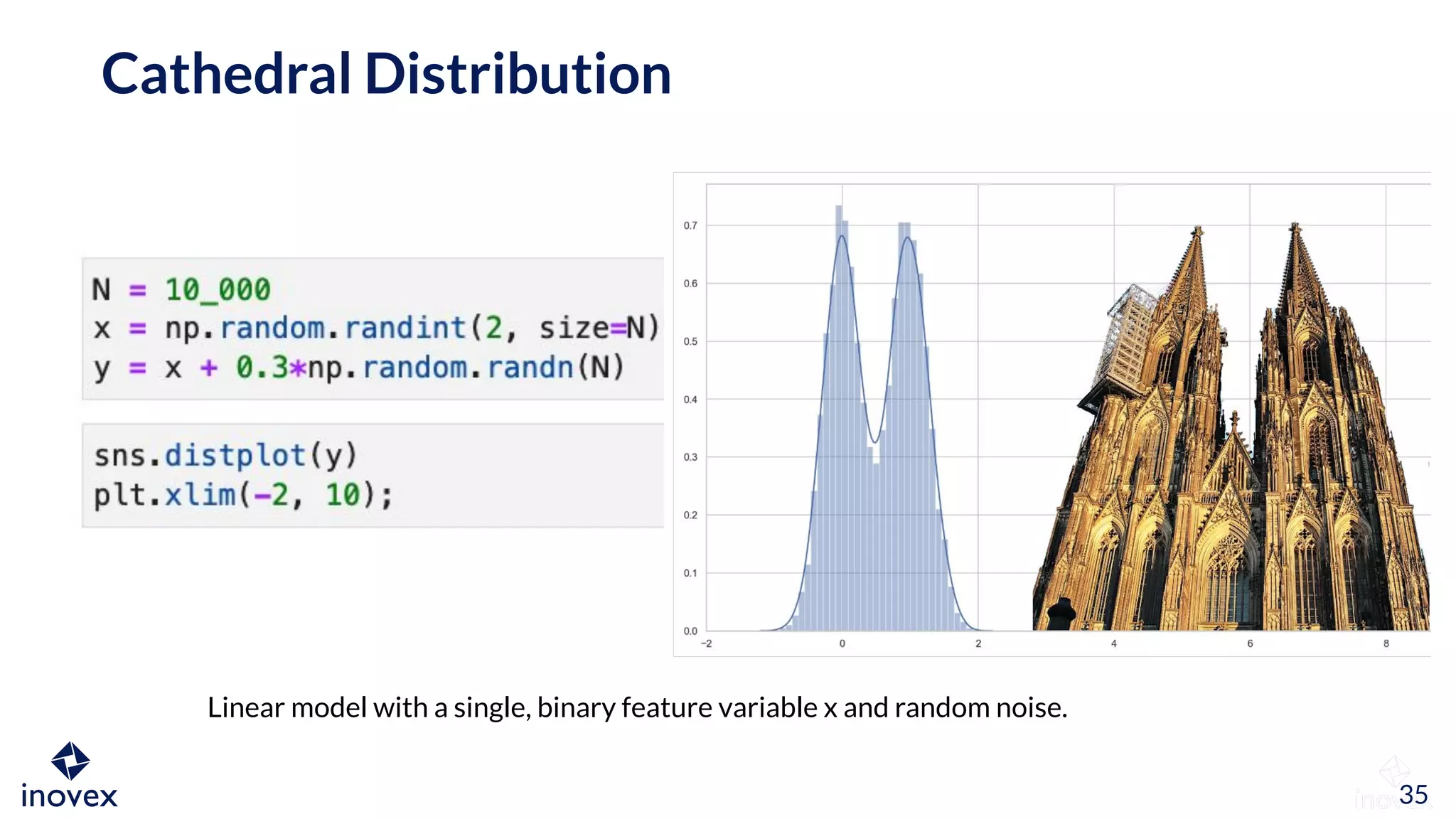
The document discusses the implications of transforming target variables in data science, emphasizing that the choice of metric affects model results. It highlights the advantages of using log transformations to minimize residual error metrics like (r)mse and the importance of correcting results based on the distribution of data. Key insights include that the mean minimizes (r)mse while the median minimizes mae, and the necessity of adjusting metric evaluations when using transformations.