Download to read offline



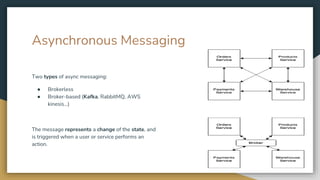
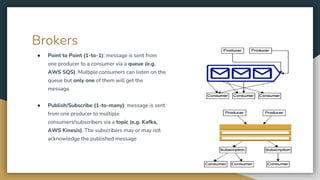



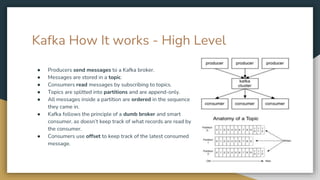
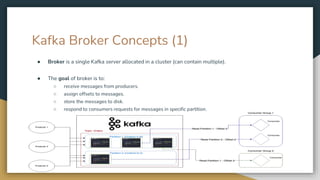



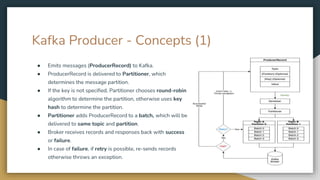
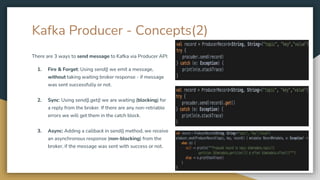










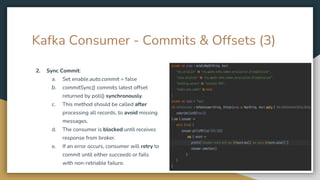

















The document serves as an introduction to Kafka and event-driven inter-process communication, explaining key concepts like message brokers, producers, consumers, and producer/consumer configurations. Kafka is described as an event streaming platform that emphasizes high throughput and durability through its distributed commit log architecture. The document also details practical configurations for brokers, producers, and consumers, along with strategies for ensuring reliable data delivery and processing guarantees.

































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)

