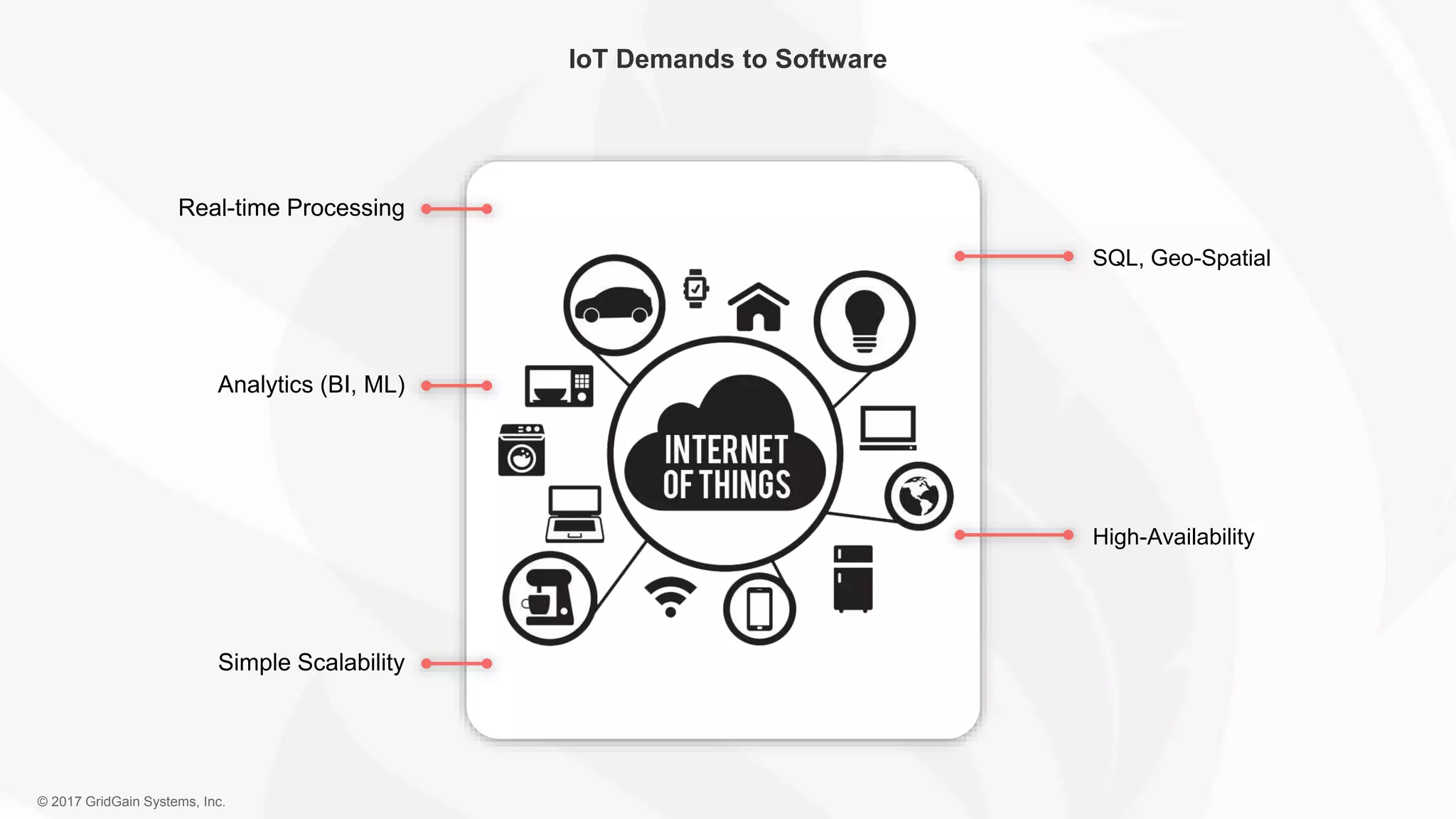
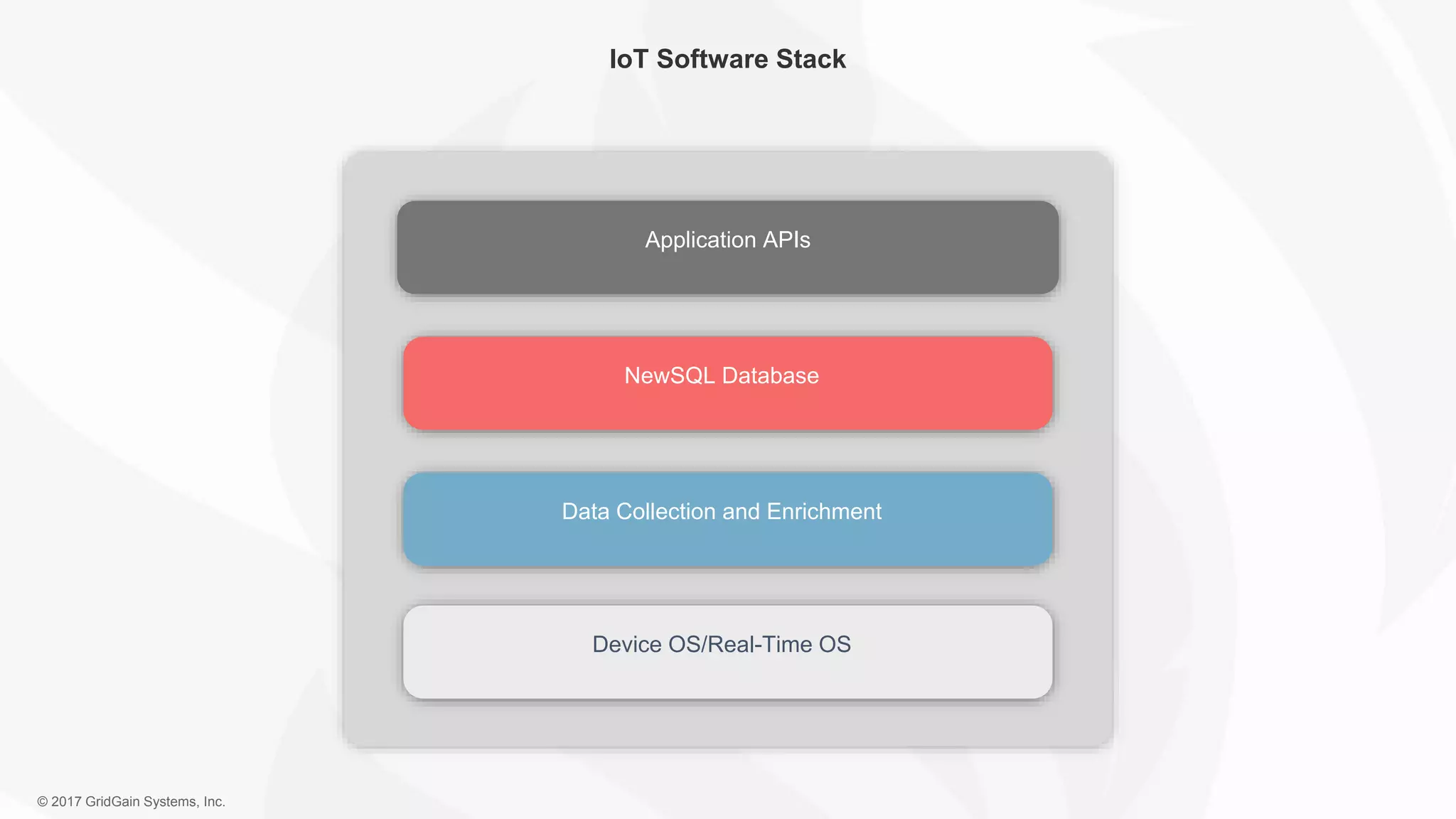
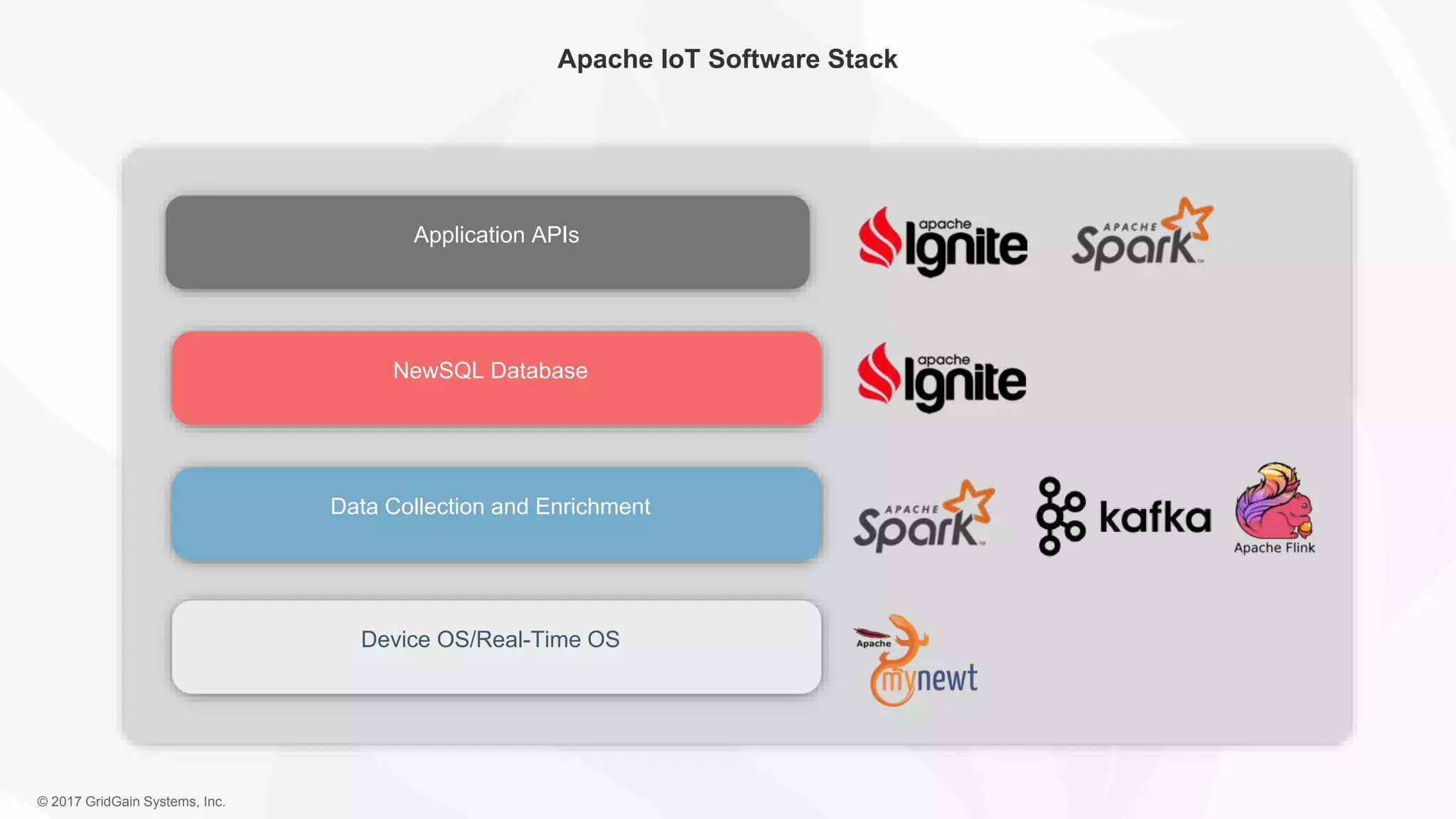
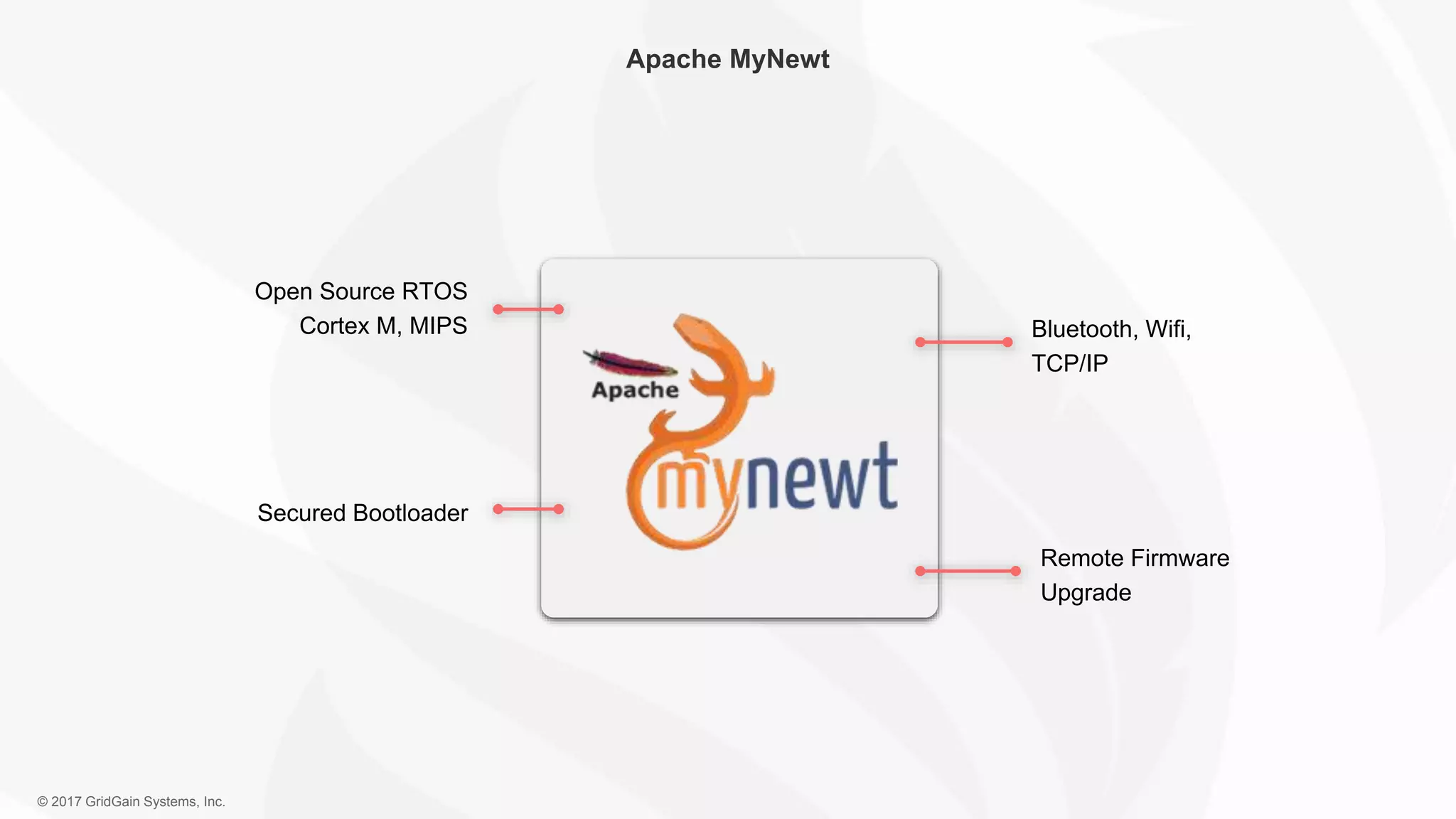
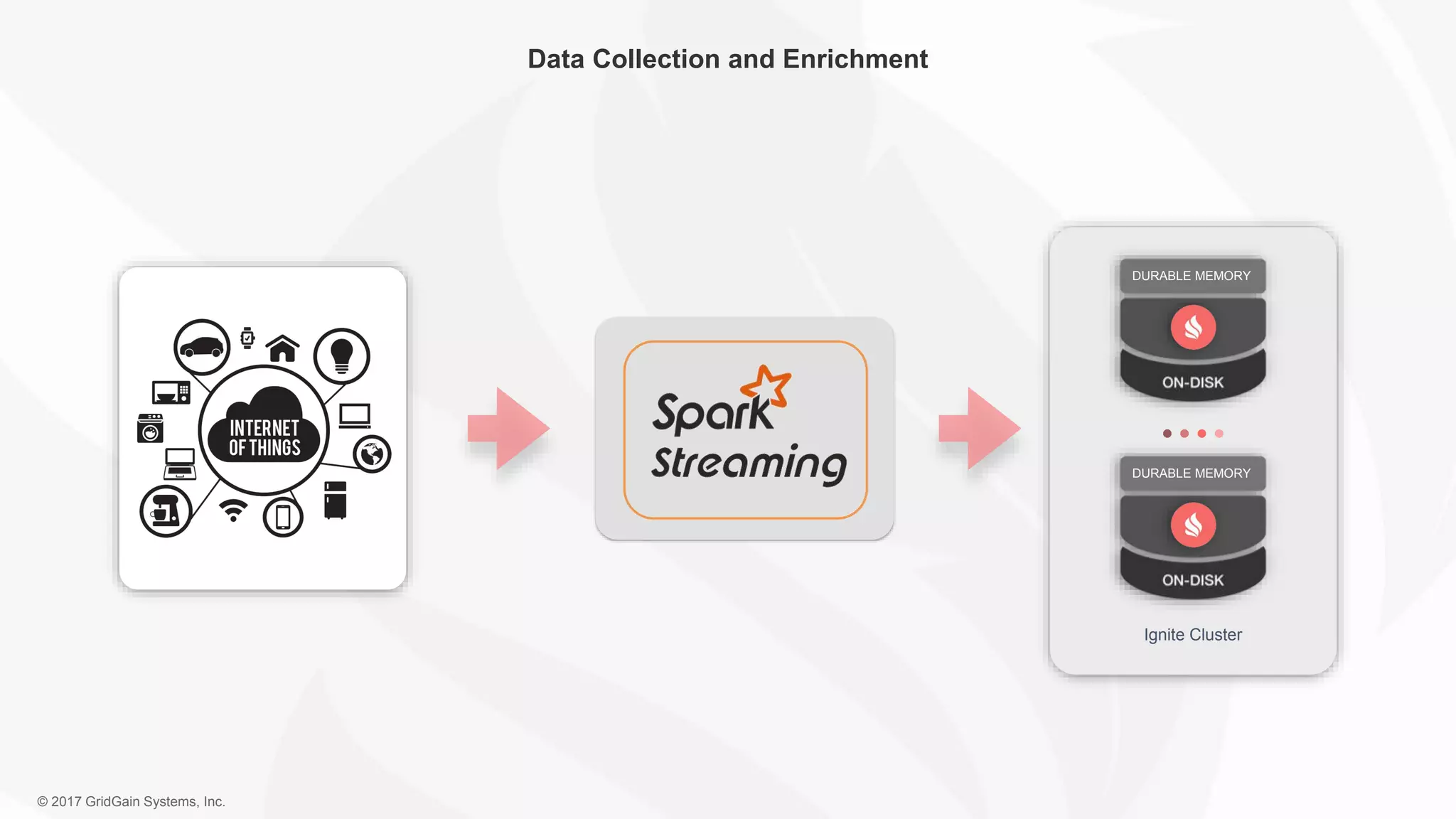
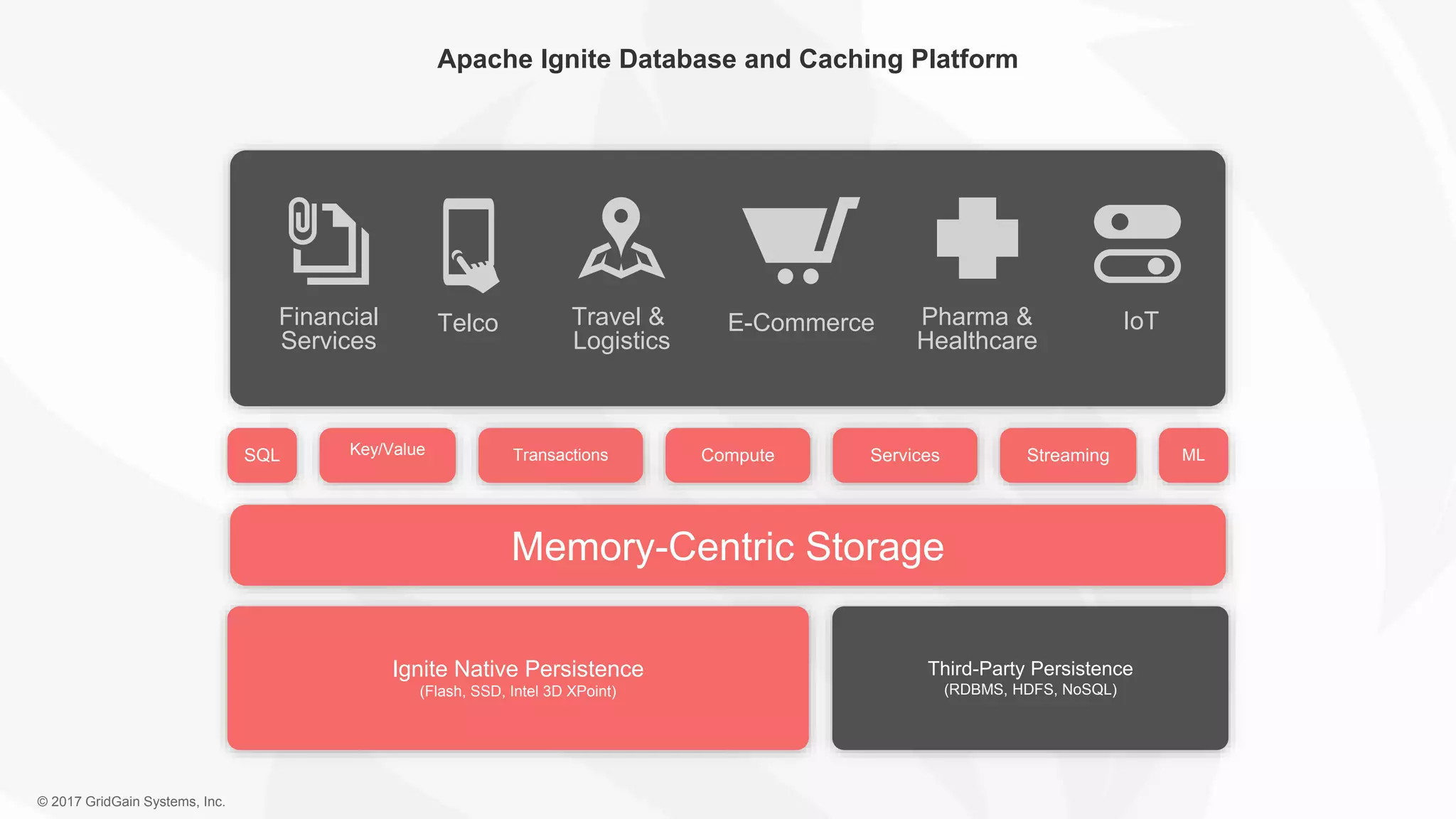
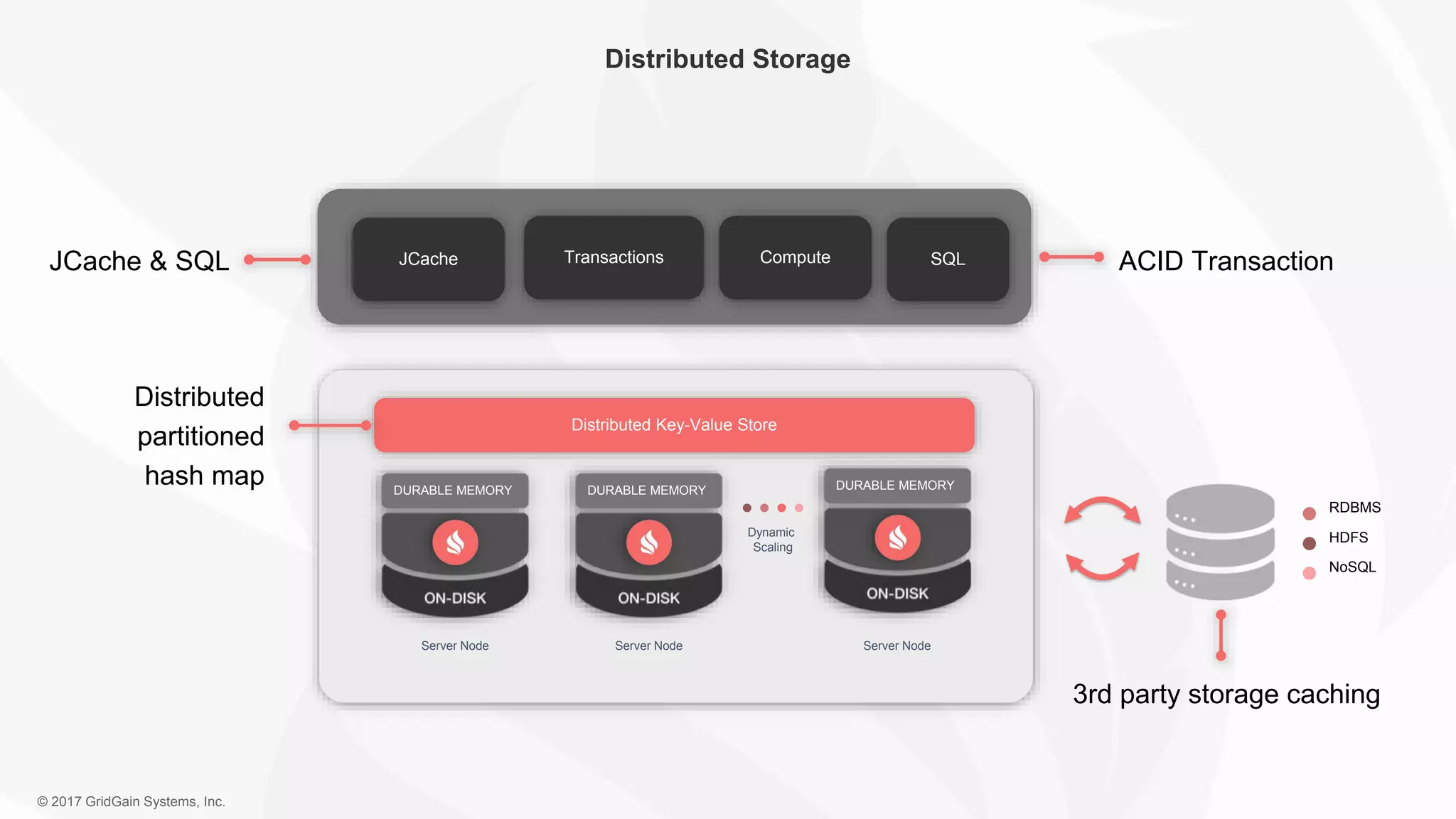
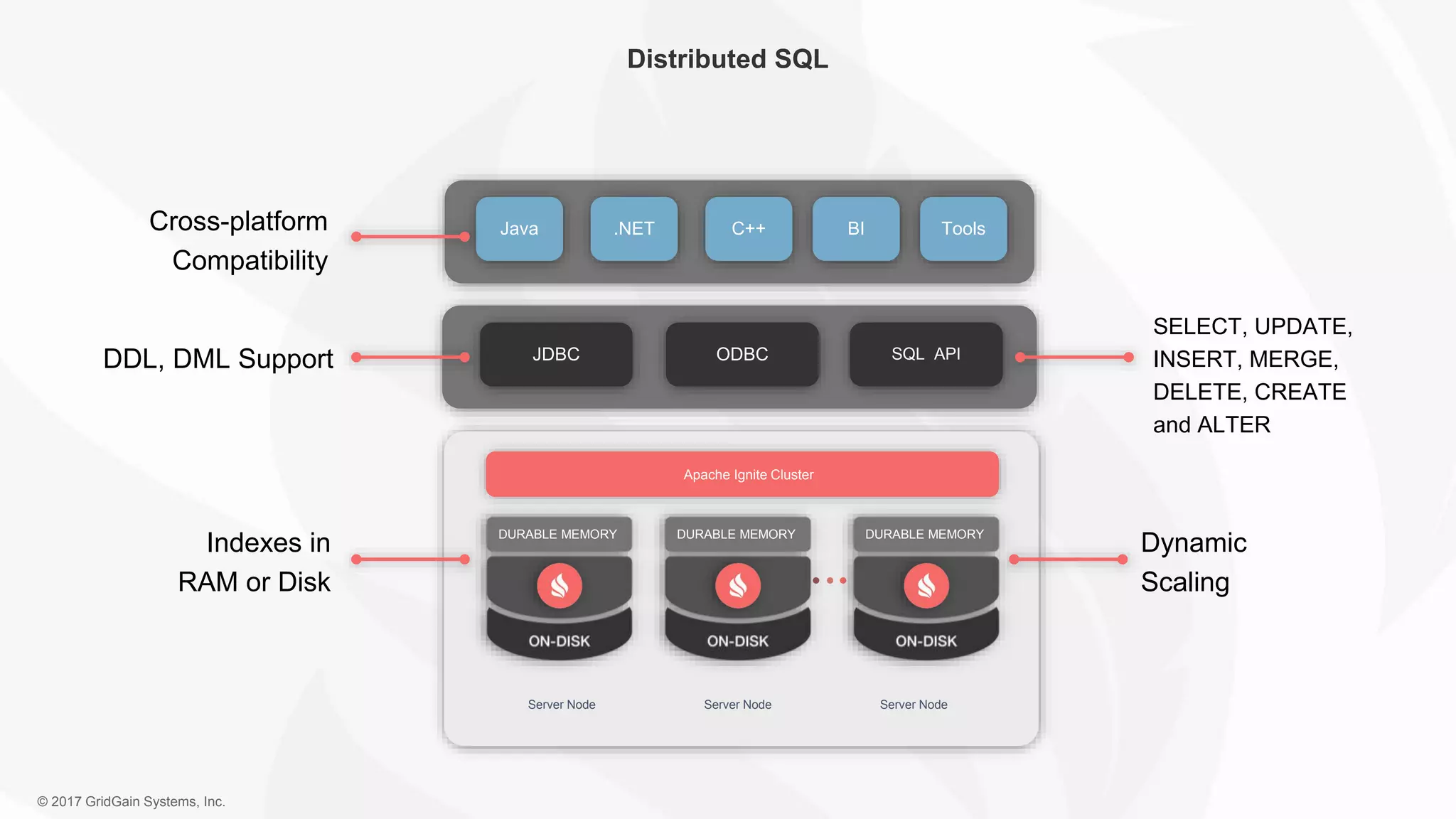
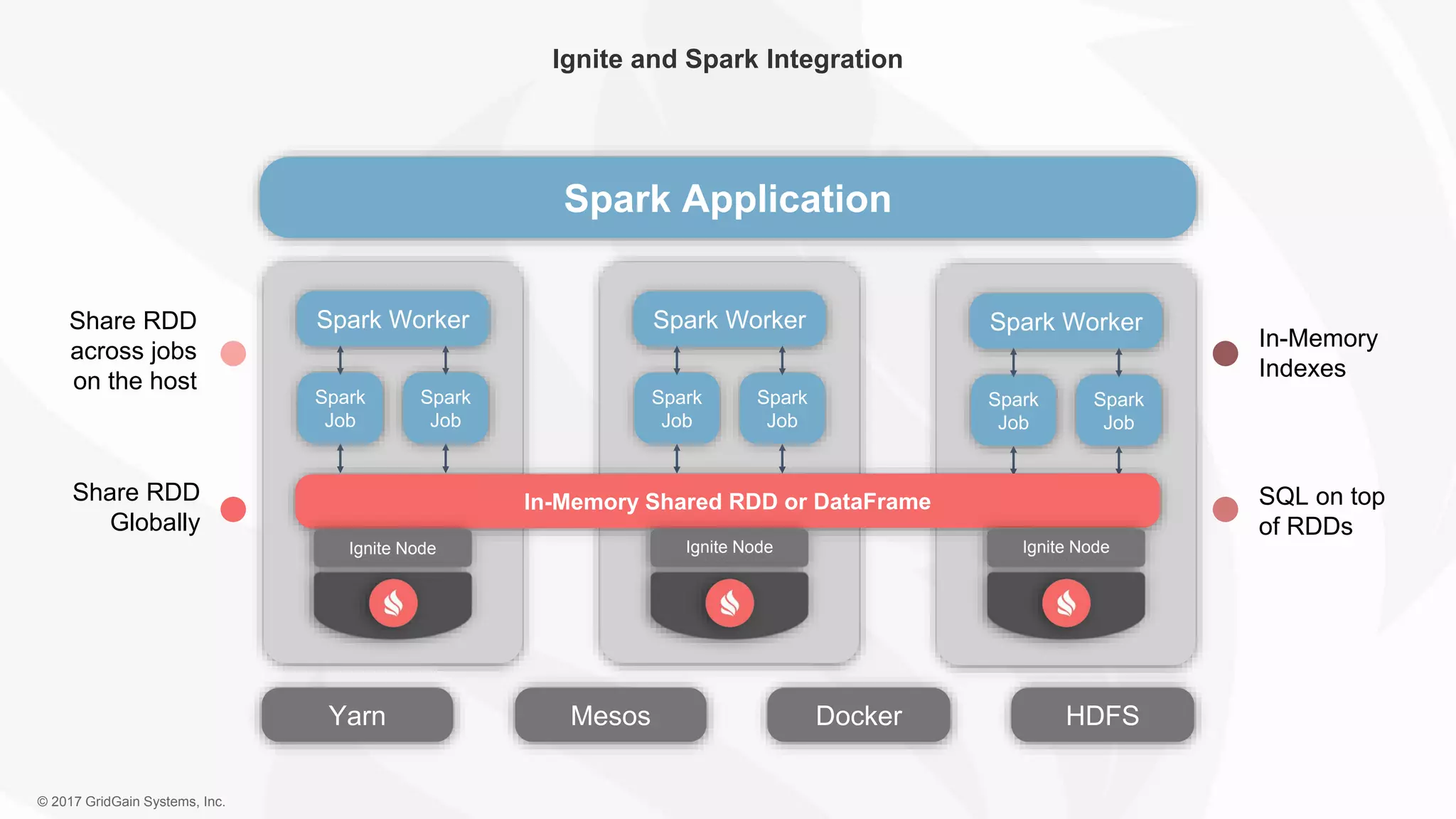
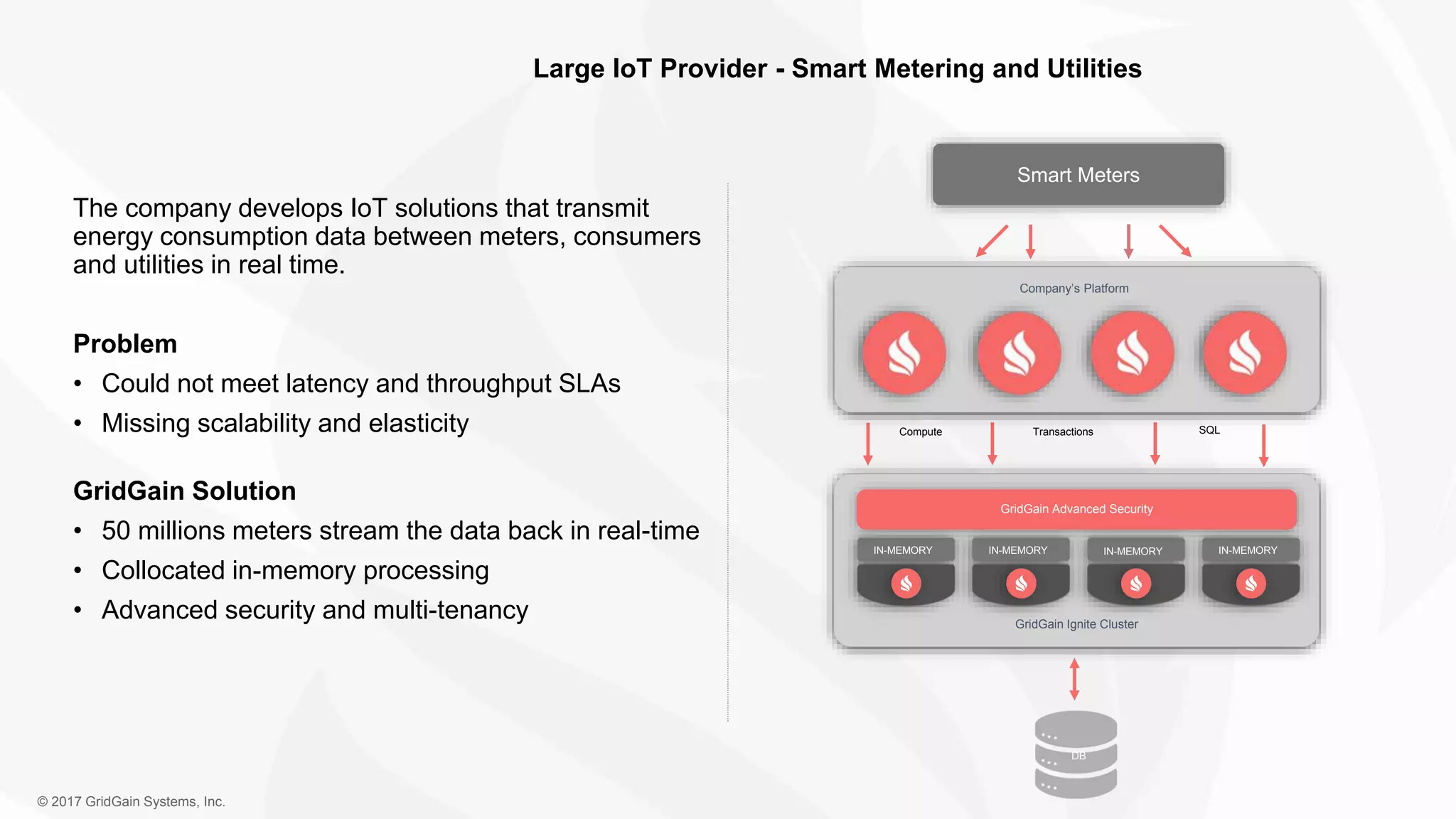
The document outlines the IoT software stack developed by GridGain Systems, emphasizing the need for real-time data processing, scalability, and high availability. It highlights their solutions, including Apache Ignite's in-memory computing capabilities and integration with Apache Spark for enhanced data management and analytics. The company demonstrates its platform's effectiveness in maintaining low latency and high throughput for smart metering and utilities applications.