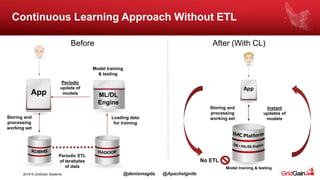
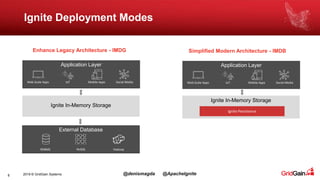
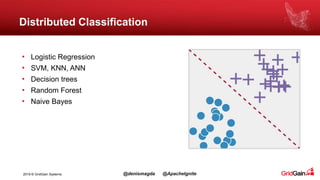
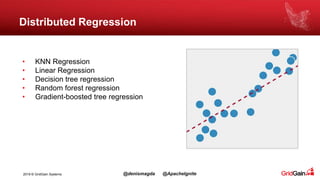
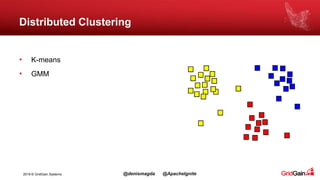
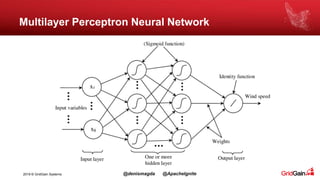
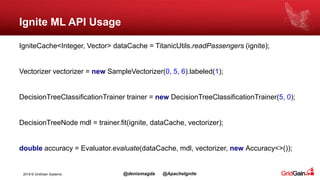
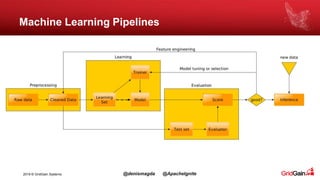
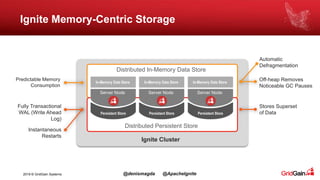
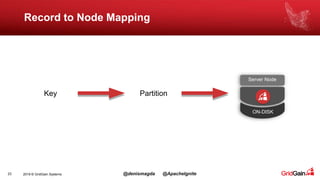
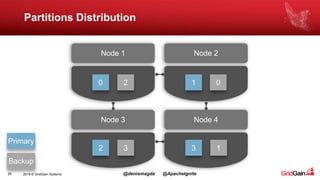
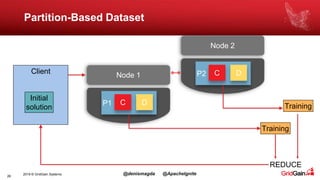
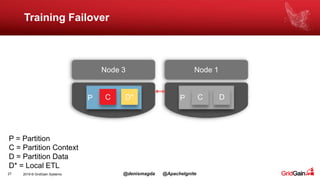
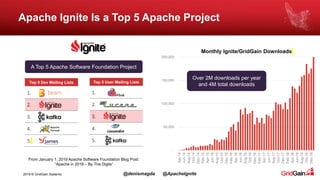
The document discusses the integration of machine and deep learning with Apache Ignite, focusing on scalability, continuous learning, and minimizing ETL processes. It covers various Ignite machine learning features, its architecture, and deployment modes, including benefits of integrating TensorFlow. Key details include distributed algorithms, multi-language support, and continual model updates without traditional ETL methods.