Downloaded 12 times


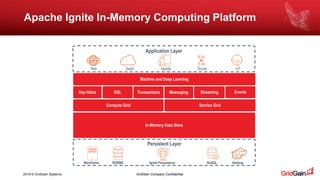



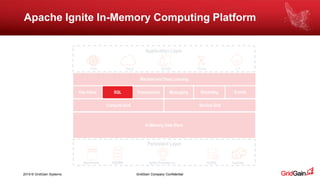
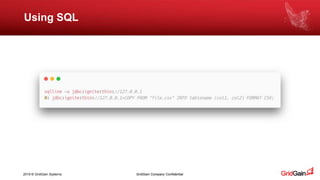
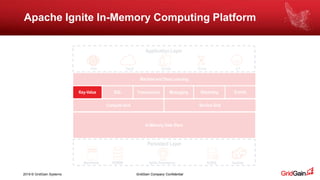
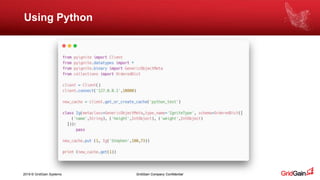
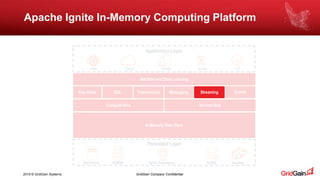
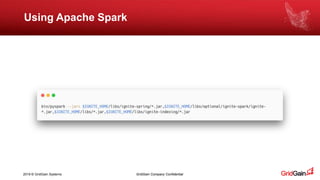






The document outlines methods for loading data into Apache Ignite using various technologies such as Python, SQL, and Apache Spark. It provides a step-by-step guide for setting up a project, including the necessary libraries and code snippets. Additionally, it mentions available resources and invites readers to a related event in Europe.