Download to read offline






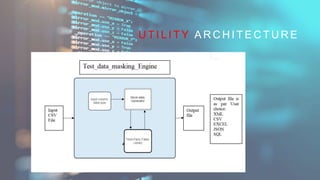



Test data anonymization involves transforming sensitive information in test datasets to protect privacy and comply with regulations. It allows thorough software testing while preventing exposure of personal data. Common techniques for anonymization include tokenization, synthetic data generation, data masking, encryption, and subset selection. Anonymization benefits organizations by mitigating risks, enabling effective testing, and safeguarding privacy.



































































